







论文笔记
资料
1.代码地址
https://github.com/pytorch/vision/blob/main/torchvision/models/squeezenet.py
2.论文地址
https://arxiv.org/abs/1602.07360
3.数据集地址
还没实验
1论文摘要的翻译
最近对深度卷积神经网络(cnn)的研究主要集中在提高准确性上。对于给定的精度级别,通常可以识别达到该精度级别的多个CNN架构。==在同等精度的情况下,较小的CNN架构提供了至少三个优势:(1)较小的CNN在分布式训练期间需要更少的服务器间通信。(2)较小的cnn从云端导出新模型到自动驾驶汽车所需的带宽更少。(3)较小的cnn更适合部署在fpga和其他内存有限的硬件上。==为了提供所有这些优势,我们提出了一个名为SqueezeNet的小型CNN架构。SqueezeNet在ImageNet上实现alexnet级别的精度,参数减少了50倍。此外,通过模型压缩技术,我们能够将SqueezeNet压缩到小于0.5MB(比AlexNet小510倍)。
背景
最近对深度卷积神经网络(cnn)的研究主要集中在提高计算机视觉数据集的准确性上。对于给定的精度水平,通常存在多个达到该精度水平的CNN架构。给定相同的精度,具有较少参数的CNN架构具有以下优点
- 更高效的分布式训练
服务器间的通信是分布式CNN训练可扩展性的限制因素。对于分布式数据并行训练,通信开销与模型中的参数数量成正比。简而言之,小模型训练更快,因为需要更少的交流。 - 在向客户端导出新模型时减少开销
今天典型的CNN/DNN模型的无线更新可能需要大量的数据传输。使用AlexNet,这将需要从服务器到汽车的240MB通信。较小的模型需要较少的通信,使频繁更新更可行。 - 可行的FPGA和嵌入式部署
fpga的片内存储器通常小于10MB,没有片外存储器或存储器。对于推理,足够小的模型可以直接存储在FPGA上,而不会受到内存带宽的瓶颈,而视频帧则实时通过FPGA。此外,当在专用集成电路(ASIC)上部署CNN时,足够小的模型可以直接存储在芯片上,而更小的模型可以使ASIC适合更小的芯片。
2论文的创新点
- 基于已有的CNN模型,发现一个新的SqueezeNet,它是具有更少参数但同等精度的架构。
3 论文方法的概述
3.1 网络设计策略
策略1 :用1x1卷积核替换3x3卷积核
给定确定预期数量的卷积滤波器的,我们将选择使这些滤波器中的大多数为1x1,因为1x1滤波器的参数比3x3滤波器少9倍。
策略2。将输入通道的数量减少到3x3个滤波器。
考虑一个完全由3x3个卷积滤波器组成的卷积层。该层参数总数为
(
输入通道数
)
∗
(
滤波器数
)
∗
(
3
∗
3
)
(输入通道数)*(滤波器数)*(3*3)
(输入通道数)∗(滤波器数)∗(3∗3)。因此,为了在CNN中保持较小的参数总数,重要的是不仅要减少3x3滤波器的数量,还要减少3x3滤波器的输入通道数量。我们使用squeeze layers将输入通道的数量减少到3x3个过滤器。
策略3。在网络的后期进行下采样,这样卷积层就有了大的激活图。
在卷积网络中,每个卷积层产生一个输出激活图,其空间分辨率至少为1x1,通常比1x1大得多。
激活图的高度和宽度由:
(1)输入数据的大小(例如256x256图像)
(2)在CNN架构中下采样的层的选择来控制。
总结:
策略1和策略2是关于明智地减少CNN中参数的数量,同时试图保持准确性。策略3是关于在有限的参数预算下最大化准确性。
3.2 FIRE MODULE
Fire模块包括:squeeze convolution layer只有1x1滤波器),expand layer ,其中有1x1和3x3卷积滤波器的混合;我们在下图1中对此进行了说明。在Fire模块中自由使用1x1过滤器是3.1节中策略1的应用。我们在Fire模块中公开了三个可调维度(超参数):
s
1
x
1
s_{1x1}
s1x1、
e
1
x
1
e_{1x1}
e1x1和
e
3
x
3
e_{3x3}
e3x3。在Fire模块中,
s
1
x
1
s_{1x1}
s1x1为挤压层(均为1x1)中的过滤器数量,
e
1
x
1
e_{1x1}
e1x1为扩展层中1x1过滤器的数量,
e
3
x
3
e_{3x3}
e3x3为扩展层中3x3过滤器的数量。当我们使用Fire模块时,我们将
s
1
x
1
s_{1x1}
s1x1设置为小于(
e
1
x
1
e_{1x1}
e1x1 +
e
3
x
3
e_{3x3}
e3x3),因此squeeze layer有助于限制3x3滤波器的输入通道数量,如3.1节中的策略2所示。
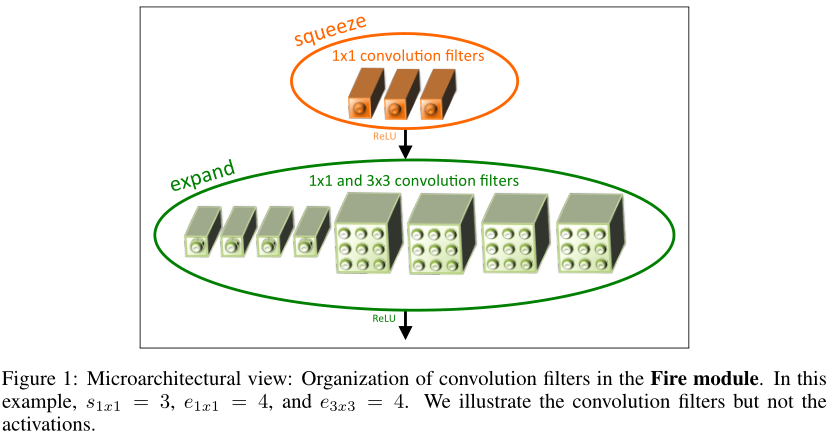
3.3 SQUEEZENET ARCHITECTURE
SqueezeNet从一个独立的卷积层(conv1)开始,然后是8个Fire模块(fire2-9),最后以一个卷积层(conv10)结束。从网络的开始到结束,我们逐渐增加每个fire模块的过滤器数量。在conv1、fire4、fire8和conv10层之后,SqueezeNet以2步长执行最大池化; 下表展示的是完整的squeeze net架构,
以下是模型架构的细节
- 为了使来自1x1和3x3过滤器的输出激活具有相同的高度和宽度,我们在expand module的3x3过滤器的输入数据中添加一个1像素的零填充边界。
- ReLU 作为squeeze and expand layers的激活函数
- 50%的Dropout在fire9模块之后应用


4 EVALUATION OF SQUEEZENET
在评估SqueezeNet时,我们使用AlexNet5和相关的模型压缩结果作为比较的基础。
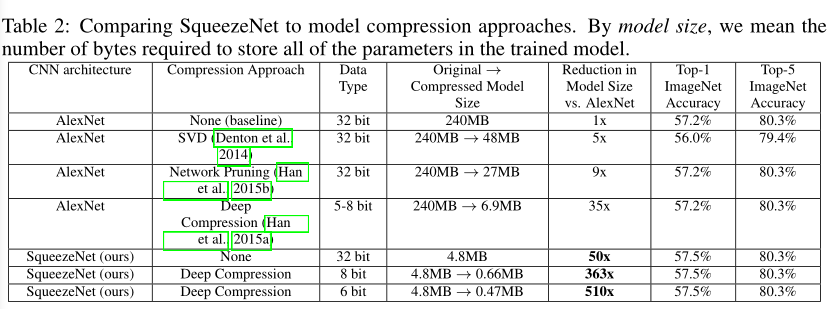
在下表中,我们在最近的模型压缩结果的背景下回顾了SqueezeNet。基于svd的方法能够将预训练的AlexNet模型压缩5倍,同时将前1的准确率降低到56.0% 。在ImageNet上,Network Pruning在保持57.2% top-1和80.3% top-5准确率的基础上,将模型大小减少了9倍。深度压缩在保持基线精度水平的同时实现了35倍的模型尺寸减小。现在,使用SqueezeNet,与AlexNet相比,我们实现了模型尺寸减少50倍,同时达到或超过AlexNet的前1和前5精度。我们在下表2中总结了上述所有结果。
这里还有个模型问题:小模型是否适合压缩,或者小模型是否“需要”密集浮点值所提供的所有表示能力?
我们使用深度压缩到SqueezeNet,使用33%稀疏性和8位量化。这产生了一个0.66 MB的模型(比32位AlexNet小363x),其精度与AlexNet相当。此外,在SqueezeNet上应用6位量化和33%稀疏度的深度压缩,我们产生了0.47MB的模型(比32位AlexNet小510倍),具有相同的精度。我们的小模型确实可以压缩。
5 CNN MICROARCHITECTURE DESIGN SPACE EXPLORATION
我们将这种架构探索分为两个主要主题:
- microarchitectural exploration 微架构探索(每个模块层的维度和配置)
- macroarchitectural exploration 宏观架构探索(模块和其他层的高级端到端组织)。
5.1 MICROARCHITECTURE METAPARAMETERS
我们定义了以下一组更高级别的元参数,它们控制CNN中所有Fire模块的尺寸。我们将 b a s e e base_e basee定义为CNN中第一个Fire模块中的扩展滤波器的数量。在每个freq Fire模块之后,我们增加扩展过滤器的数量。换句话说,对于Fire模块 i i i,扩展过滤器的数量为 e i = b a s e e + ( i n c r e e ∗ ) ⌊ i f r e q ⌋ e_i =base_e + (incre_e * )\lfloor \frac{i}{freq} \rfloor ei=basee+(incree∗)⌊freqi⌋。在Fire模块的扩展层中,有些滤波器是1x1的,有些是 3 x 3 3x3 3x3的;我们定义 e i = e i , 1 x 1 + e i , 3 x 3 e_i = e_{i,1x1} + e_{i,3x3} ei=ei,1x1+ei,3x3与 p c t 3 x 3 pct_{3x3} pct3x3(在[0,1]范围内,在所有Fire模块上共享)作为扩展过滤器为3x3的百分比。换句话说, e i , 3 x 3 = e i ∗ p c t 3 x 3 e_{i,3x3} = e_i∗pct_{3x3} ei,3x3=ei∗pct3x3,和 e i , 1 x 1 = e i ∗ ( 1 − p c t 3 x 3 ) e_{i,1x1} = e_i∗(1−pct_{3x3}) ei,1x1=ei∗(1−pct3x3)。最后,我们使用称为挤压比(SR)的元参数定义Fire模块的挤压层中的过滤器数量(再次,在 [ 0 , 1 ] [0,1] [0,1]范围内,由所有Fire模块共享): s i , 1 x 1 = S R ∗ e i s_{i,1x1} = SR∗e_i si,1x1=SR∗ei(或等效 s i , 1 x 1 = S R ∗ ( e i , 1 x 1 + e i , 3 x 3 ) ) s_{i,1x1} = SR∗(e_{i,1x1} + e_{i,3x3})) si,1x1=SR∗(ei,1x1+ei,3x3))。SqueezeNet(表1)是我们用前面提到的一组元参数生成的一个示例体系结构。具体来说,《SqueezeNet》拥有以下元参数: b a s e e base_e basee = 128, i n c r e incr_e incre = 128, p c t 3 x 3 pct_{3x3} pct3x3 = 0.5, freq = 2, SR = 0.125。
5.2 SQUEEZE RATIO 压缩比
我们现在设计了一个实验来研究挤压比对模型尺寸和精度的影响
在这些实验中,我们使用SqueezeNet(图2)作为起点。与在SqueezeNet中一样,这些实验使用以下元参数:
b
a
s
e
e
base_e
basee = 128,
i
n
c
r
e
incr_e
incre = 128,
p
c
t
3
x
3
pct_{3x3}
pct3x3 = 0.5, freq = 2。我们训练了多个模型,其中每个模型在#[0.125,1.0]#范围内具有不同的挤压比(SR)。在图3(a)中,我们展示了这个实验的结果,图上的每个点都是一个从头开始训练的独立模型。SqueezeNet是这个图中的#SR=0.125#点从该图中,我们了解到将SR提高到0.125以上可以进一步将ImageNet top-5的准确率从4.8MB模型的80.3%(即alexnet级别)提高到19MB模型的86.0%。当SR=0.75 (19MB模型)时,准确率稳定在86.0%,设置#SR=1.0#会进一步增加模型大小,但不会提高准确率。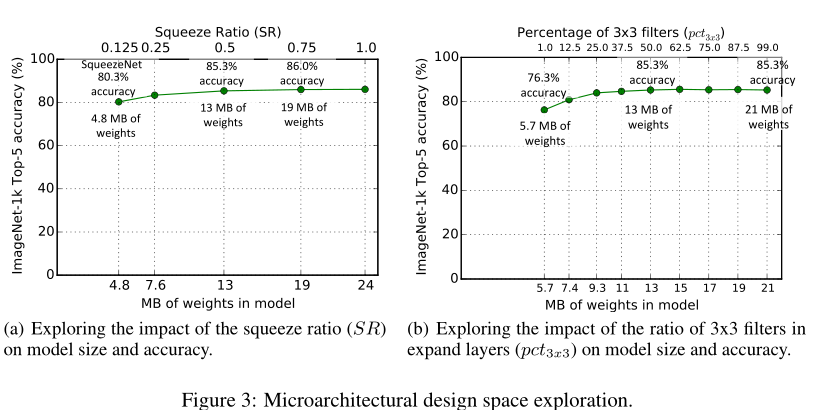
5.3权衡1x1和3x3过滤器
空间分辨率在CNN滤波器中有多重要?
我们在这个实验中使用以下元参数:
b
a
s
e
e
=
i
n
c
r
e
=
128
base_e = incr_e = 128
basee=incre=128,
f
r
e
q
=
2
freq = 2
freq=2,
S
R
=
0.500
SR = 0.500
SR=0.500,我们将
p
c
t
3
x
3
pct_{3x3}
pct3x3从1%变化到99%。换句话说,每个Fire模块的扩展层在1x1和3x3之间划分了预定义的过滤器数量,在这里我们将这些过滤器的旋钮从“主要1x1”转到“主要3x3”。与前面的实验一样,这些模型有8个Fire模块,遵循图2中相同的层组织。我们将实验结果显示在上图3(b)中。注意,图3(a)和图3(b)中的13MB模型是相同的架构:
S
R
=
0.500
SR = 0.500
SR=0.500,
p
c
t
3
x
3
=
50
%
pct_{3x3} = 50\%
pct3x3=50%。我们在图3(b)中看到,使用50%的3x3滤波器时,前5个精度稳定在85.6%,进一步增加3x3滤波器的百分比会导致更大的模型尺寸,但在ImageNet上没有提高精度。
6 CNN MACROARCHITECTURE DESIGN SPACE EXPLORATION
现在,我们在宏观体系结构级别探讨有关Fire模块之间的高级连接的设计决策。我们探索了三种不同的架构
- V anilla SqueezeNet
- SqueezeNet with simple bypass connections between some Fire modules.
- SqueezeNet with complex bypass connections between the remaining Fire modules.
我们的简单旁路架构在Fire模块3、5、7和9周围添加了旁路连接,要求这些模块在输入和输出之间学习残差函数。与ResNet一样,为了实现绕过Fire3的连接,我们将Fire4的输入设置为(Fire2的输出+ Fire3的输出),其中+运算符是元素加法。这改变了应用于这些Fire模块参数的正则化,并且,根据ResNet,可以提高最终的准确性和/或训练完整模型的能力。
我们用图2中的三个宏观架构训练了SqueezeNet,并在表3中比较了精度和模型大小。

与普通的SqueezeNet架构相比,复杂和简单的旁路连接都提高了精度。有趣的是,与复杂旁路相比,简单旁路能够提高精度。
7 总结
提出了一种更有纪律的方法来探索卷积神经网络的设计空间。
为了实现这一目标,我们提出了SqueezeNet,这是一种CNN架构,其参数比AlexNet少50倍,并在ImageNet上保持AlexNet级别的精度。
SqueezeNet是我们在广泛探索CNN架构的设计空间时发现的几个新的CNN之一。我们希望SqueezeNet能够激发读者思考和探索CNN建筑设计空间的广泛可能性,并以更系统的方式进行探索
















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











