






Kubernetes&&批处理平台&&Volcano
前言
官网
Volcano是一个基于Kubernetes的容器批量计算平台,主要用于高性能计算场景。提供了包括基于各种主流架构的CPU、GPU在内的异构设备混合调度能力、高性能任务调度引擎、高性能异构芯片管理、高性能任务运行管理等通用计算能力,通过接入AI、大数据、基因、渲染等诸多行业计算框架服务终端用户。
支持的调度策略
- Gang-scheduling
- Fair-share scheduling
- Queue scheduling
- Preemption scheduling
- Topology-based scheduling
- Reclaims
- Backfill
- Resource Reservation
Volcano 提供了基于多种架构的计算资源的混合调度能力
- x86
- ARM
- 鲲鹏
- 昇腾
- GPU
系统架构

- Volcano Scheduler 通过一系列的action和plugin调度Job,并为它找到一个最适合的节点,与Kubernetes default-Scheduler相比,Volcano支持针对Job的多种调度算法。
- Volcano ControllerManager管理CRD资源的生命周期。它主要由Queue ControllerManager、PodGroupControllerManager、VCJob ControllerManager构成。
- Volcano Admission 负责对CRD API资源进行校验。
- Volcano Vcctl 是Volcano的命令行客户端工具。
Queue
Queue 是容纳一组 podgroup 的队列,也是该组 podgroup 获取集群资源的划分依据。
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2020-08-10T11:54:36Z"
generation: 1
name: default
resourceVersion: "559"
selfLink: /apis/scheduling.volcano.sh/v1beta1/queues/default
uid: 14082e4c-bef6-4248-a414-1e06d8352bf0
spec:
reclaimable: true
weight: 1
capability:
cpu: "4"
memory: "4096Mi"
status:
state: Open
关键字段
- weight
- weight表示该queue在集群资源划分中所占的相对比重,该queue应得资源总量为 (weight/total-weight) * total-resource。其中, total-weight表示所有的queue的weight总和,total-resource表示集群的资源总量。weight是一个软约束,取值范围为[1, 2^31-1]。
- capability
- capability表示该queue内所有podgroup使用资源量之和的上限,它是一个硬约束。
- reclaimable
- reclaimable表示该queue在资源使用量超过该queue所应得的资源份额时,是否允许其他queue回收该queue使用超额的资源,默认值为true。
资源状态
- Open: 该queue当前处于可用状态,可接收新的podgroup
- Closed: 该queue当前处于不可用状态,不可接收新的podgroup
- Closing: 该Queue正在转化为不可用状态,不可接收新的podgroup
- Unknown: 该queue当前处于不可知状态,可能是网络或其他原因导致queue的状态暂时无法感知
PodGroup
PodGroup 是一组强关联Pod的集合,主要用于批处理工作负载场景,比如Tensorflow中的一组ps和worker。它是volcano自定义资源类型。
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
creationTimestamp: "2020-08-11T12:28:55Z"
generation: 5
name: test
namespace: default
ownerReferences:
- apiVersion: batch.volcano.sh/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Job
name: test
uid: 028ecfe8-0ff9-477d-836c-ac5676491a38
resourceVersion: "109074"
selfLink: /apis/scheduling.volcano.sh/v1beta1/namespaces/default/podgroups/job-1
uid: eb2508f5-3349-439c-b94d-4ac23afd71ff
spec:
minMember: 1
minResources:
cpu: "3"
memory: "2048Mi"
priorityClassName: high-prority
queue: default
status:
conditions:
- lastTransitionTime: "2020-08-11T12:28:57Z"
message: '1/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable.'
reason: NotEnoughResources
status: "True"
transitionID: 77d5be3f-6169-4f86-8e65-0bdc621ce983
type: Unschedulable
- lastTransitionTime: "2020-08-11T12:29:02Z"
reason: tasks in gang are ready to be scheduled
status: "True"
transitionID: 54514401-5c90-4b11-840d-90c1cda93096
type: Scheduled
phase: Running
running: 1
关键字段
- minMember
- minMember表示该podgroup下最少需要运行的pod或任务数量。如果集群资源不满足miniMember数量任务的运行需求,调度器将不会调度任何一个该podgroup 内的任务。
- queue
- queue表示该podgroup所属的queue。queue必须提前已创建且状态为open。
- priorityClassName
- priorityClassName表示该podgroup的优先级,用于调度器为该queue中所有podgroup进行调度时进行排序。system-node-critical和system-cluster-critical 是2个预留的值,表示最高优先级。不特别指定时,默认使用default优先级或zero优先级。
- minResources
- minResources表示运行该podgroup所需要的最少资源。当集群可分配资源不满足minResources时,调度器将不会调度任何一个该podgroup内的任务。
- phase
- phase表示该podgroup当前的状态。
- conditions
- conditions表示该podgroup的具体状态日志,包含了podgroup生命周期中的关键事件。
- running
- running表示该podgroup中当前处于running状态的pod或任务的数量。
- succeed
- succeed表示该podgroup中当前处于succeed状态的pod或任务的数量。
- failed
- failed表示该podgroup中当前处于failed状态的pod或任务的数量。
VolcanoJob
Volcano Job,简称vcjob,是Volcano自定义的Job资源类型。区别于Kubernetes Job,vcjob提供了更多高级功能,如可指定调度器,支持最小运行pod数,支持task,支持生命周期管理、支持指定队列、支持优先级调度等。Volcano Job更加适用于机器学习、大数据、科学计算等高性能计算场景。
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: test-job
spec:
minAvailable: 3
schedulerName: volcano
priorityClassName: high-priority
policies:
- event: PodEvicted
action: RestartJob
plugins:
ssh: []
env: []
svc: []
maxRetry: 5
queue: default
volumes:
- mountPath: "/myinput"
- mountPath: "/myoutput"
volumeClaimName: "testvolumeclaimname"
volumeClaim:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
tasks:
- replicas: 6
name: "default-nginx"
template:
metadata:
name: web
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources:
requests:
cpu: "1"
restartPolicy: OnFailure
关键字段
- schedulerName
- schedulerName表示该job的pod所使用的调度器,默认值为volcano,也可指定为default-scheduler。它也是tasks.template.spec.schedulerName的默认值。
- minAvailable
minAvailable表示运行该job所要运行的最少pod数量。只有当job中处于running状态的pod数量不小于minAvailable时,才认为该job运行正常。 - volumes
- volumes表示该job的挂卷配置。volumes配置遵从kubernetes volumes配置要求。
- tasks.replicas
- tasks.replicas表示某个task pod的副本数。
- tasks.template
- tasks.template表示某个task pod的具体配置定义。
- tasks.policies
- tasks.policies表示某个task的生命周期策略。
- policies
- policies表示job中所有task的默认生命周期策略,在tasks.policies不配置时使用该策略。
- plugins
- plugins表示该job在调度过程中使用的插件。
- queue
- queue表示该job所属的队列。
- priorityClassName
- priorityClassName表示该job优先级,在抢占调度和优先级排序中生效。
- maxRetry
- maxRetry表示当该job可以进行的最大重启次数。
资源状态
- pending
- pending表示job还在等待调度中,处于排队的状态。
- aborting
- aborting表示job因为某种外界原因正处于中止状态,即将进入aborted状态。
- aborted
- aborted表示job因为某种外界原因已处于中止状态。
- running
- running表示job中至少有minAvailable个pod正在运行状态。
- restarting
- restarting表示job正处于重启状态,正在中止当前的job实例并重新创建新的实例。
- completing
- completing表示job中至少有minAvailable个数的task已经完成,该job正在进行最后的清理工作。
- completed
- completing表示job中至少有minAvailable个数的task已经完成,该job已经完成了最后的清理工作。
- terminating
- terminating表示job因为某种内部原因正处于终止状态,正在等到pod或task释放资源。
- terminated
- terminated表示job因为某种内部原因已经处于终止状态,job没有达到预期就结束了。
- failed
- failed表示job经过了maxRetry次重启,依然没有正常启动。
Volcano Scheduler
Volcano Scheduler是负责Pod调度的组件,它由一系列action和plugin组成。action定义了调度各环节中需要执行的动作;plugin根据不同场景提供了action 中算法的具体实现细节。Volcano scheduler具有高度的可扩展性,您可以根据需要实现自己的action和plugin。
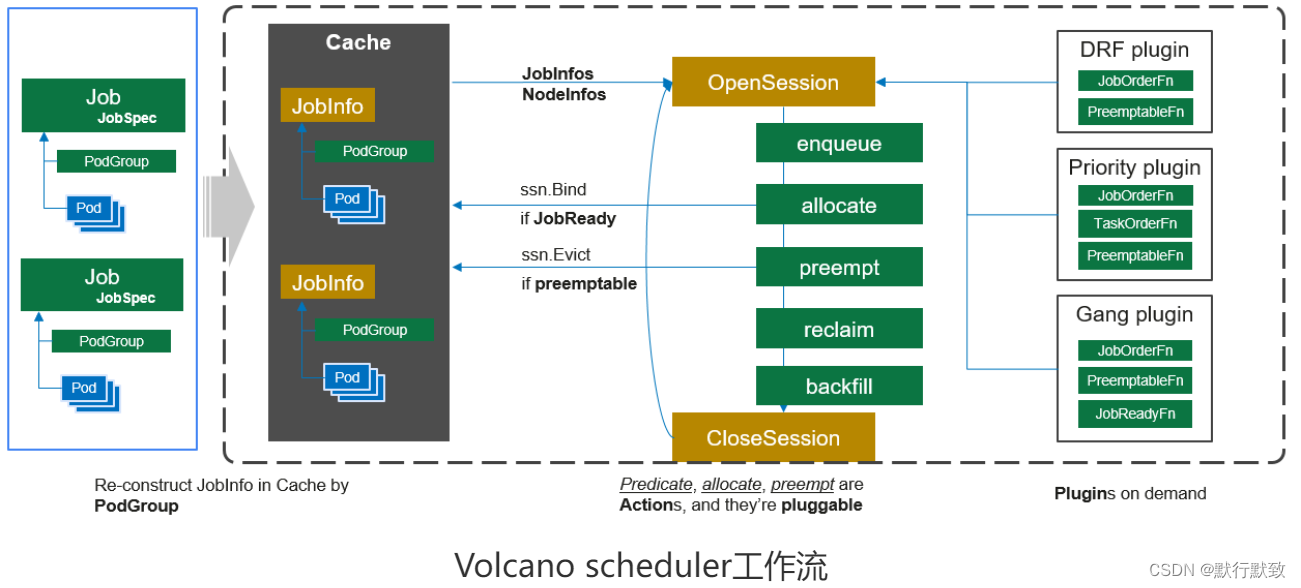
Actions
Enqueue
简介
Enqueue action筛选符合要求的作业进入待调度队列。当一个Job下的最小资源申请量不能得到满足时,即使为Job下的Pod执行调度动作,Pod也会因为gang约束没有达到而无法进行调度;只有当job的最小资源量得到满足,状态由”Pending”刷新为”Inqueue”才可以进行。一般来说Enqueue action是调度器配置必不可少的action。
场景
Enqueue action是调度流程中的准备阶段,只有当集群资源满足作业调度的最小资源请求,作业状态才可由”pending”变为”enqueue”。这样在AI/MPI/HPC这样的集群资源可能不足的高负荷的场景下,Enqueue action能够防止集群下有大量不能调度的pod,提高了调度器的性能。
Allocate
简介
Allocate action是调度流程中的正常分配步骤,用于处理在待调度Pod列表中具有资源申请量的Pod调度,是调度过程必不可少的action。这个过程包括作业的predicate和prioritize。使用predicateFn预选,过滤掉不能分配作业的node;使用NodeOrderFn打分来找到最适合的分配节点。
Allocate action遵循commit机制,当一个Pod的调度请求得到满足后,最终并不一定会为该Pod执行绑定动作,这一步骤还取决于Pod所在Job的gang约束是否得到满足。只有Pod所在Job的gang约束得到满足,Pod才可以被调度,否则,Pod不能够被调度。
场景
在集群混合业务场景中,Allocate的预选部分能够将特定的业务(AI、大数据、HPC、科学计算)按照所在namespace快速筛选、分类,对特定的业务进行快速、集中的调度。在Tensorflow、MPI等复杂计算场景中,单个作业中会有多个任务,Allocate action会遍历job下的多个task分配优选,为每个task找到最合适的node。
Preempt
简介
Preempt action是调度流程中的抢占步骤,用于处理高优先级调度问题。Preempt用于同一个Queue中job之间的抢占,或同一Job下Task之间的抢占。
场景
Queue内job抢占:一个公司中多个部门共用一个集群,每个部门可以映射成一个Queue,不同部门之间的资源不能互相抢占,这种机制能够很好的保证部门资源的隔离性。多业务类型混合场景中,基于Queue的机制满足了一类业务对于某一类资源的集中诉求,也能够兼顾集群的弹性。例如,AI业务组成的queue对集群GPU占比90%,其余图像类处理的业务组成的queue占集群GPU10%。前者占用了集群绝大部分GPU资源但是依然有一小部分资源可以处理其余类型的业务。
Job内task抢占:同一Job下通常可以有多个task,例如复杂的AI应用场景中,tf-job内部需要设置一个ps和多个worker,Preempt action就支持这种场景下多个worker之间的抢占。
Reserve
简介
Reserve action从v1.2开始已经被弃用,并且被SLA plugin替代。
Reserve action完成资源预留。将选中的目标作业与节点进行绑定。Reserve action、elect action 以及Reservation plugin组成了资源预留机制。Reserve action必须配置在allocate action之后。
场景
在实际应用中,常见以下两种场景:
在集群资源不足的情况下,假设处于待调度状态的作业A和B,A资源申请量小于B或A优先级高于B。基于默认调度策略,A将优先于B进行调度。在最坏的情况下,若后续持续有高优先级或申请资源量较少的作业加入待调度队列,B将长时间处于饥饿状态并永远等待下去。
在集群资源不足的情况下,假设存在待调度作业A和B。A优先级低于B但资源申请量小于B。在基于集群吞吐量和资源利用率为核心的调度策略下,A将优先被调度。在最坏的情况下,B将持续饥饿下去。
因此我们需要一种公平调度机制:保证因为某种原因长期饥饿达到临界状态之后被调度。作业预留机制的就是这样一种公平调度机制。
资源预留机制需要考虑节点选取、节点数量以及如何锁定节点。volcano资源预留机制采用节点组锁定的方式为目标作业预留资源,即选定一组符合某些约束条件的节点纳入节点组,节点组内的节点从纳入时刻起不再接受新作业投递,节点规格总和满足目标作业要求。需要强调的是,目标作业将可以在整个集群中进行调度,非目标作业仅可使用节点组外的节点进行调度。
Backfill
简介
Backfill action是调度流程中的回填步骤,处理待调度Pod列表中没有指明资源申请量的Pod调度,在对单个Pod执行调度动作的时候,遍历所有的节点,只要节点满足了Pod的调度请求,就将Pod调度到这个节点上。
场景
在一个集群中,主要资源被“胖业务”占用,例如AI模型的训练。Backfill action让集群可以快速调度诸如单次AI模型识别、小数据量通信的“小作业” 。Backfill能够提高集群吞吐量,提高资源利用率。















 3391
3391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









