





如何在没有那些讨厌的数据库的情况下收集数据。
Web抓取是创建动态网站的好方法,而无需联系数据库以获取信息。
要开始进行网络抓取,您应该知道网站的结构。 如果右键单击页面,然后单击检查(在Chrome上),则可以看到开发人员工具。
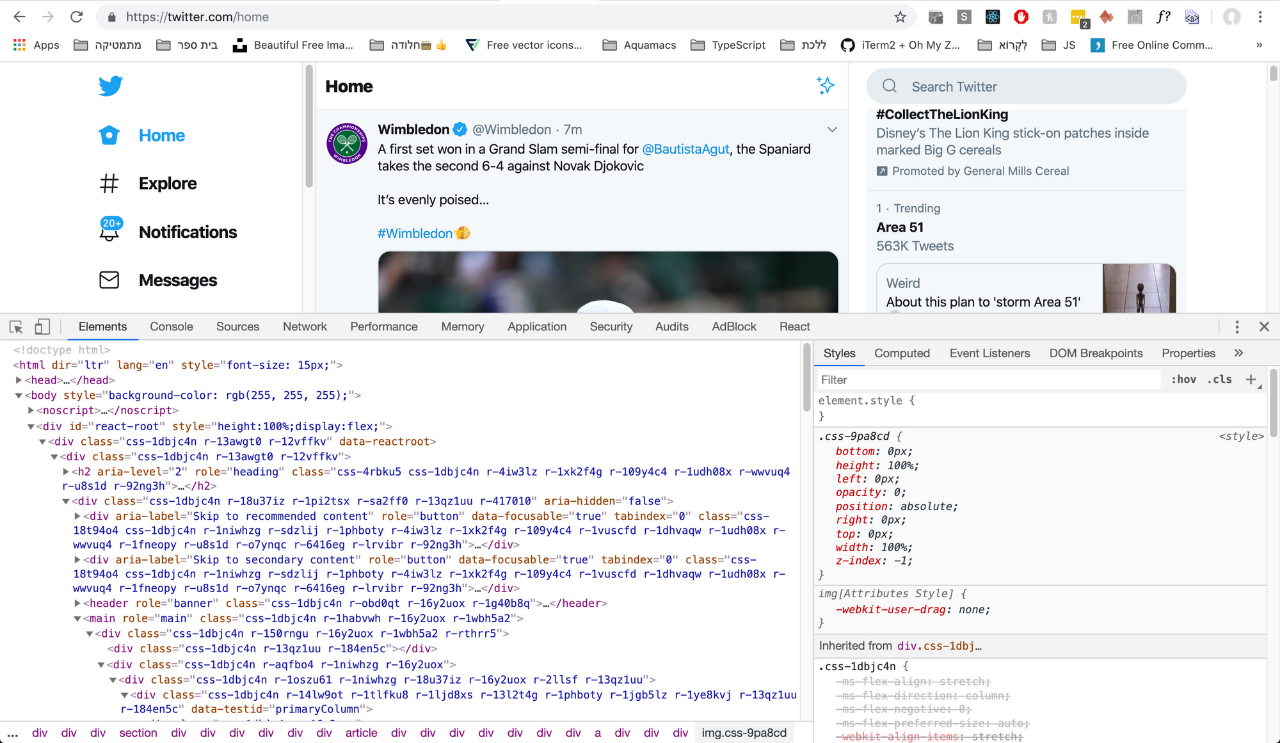
这向您显示了网站HTML / CSS / JavaScript代码的结构,以及网络性能,错误,安全性等等。
现在,假设我想在JavaScript控制台中以编程方式获取您在Twitter上看到的第一张图像。
好吧,我可以右键单击图像,单击检查,右键单击开发工具中的元素,然后复制CSS选择器。
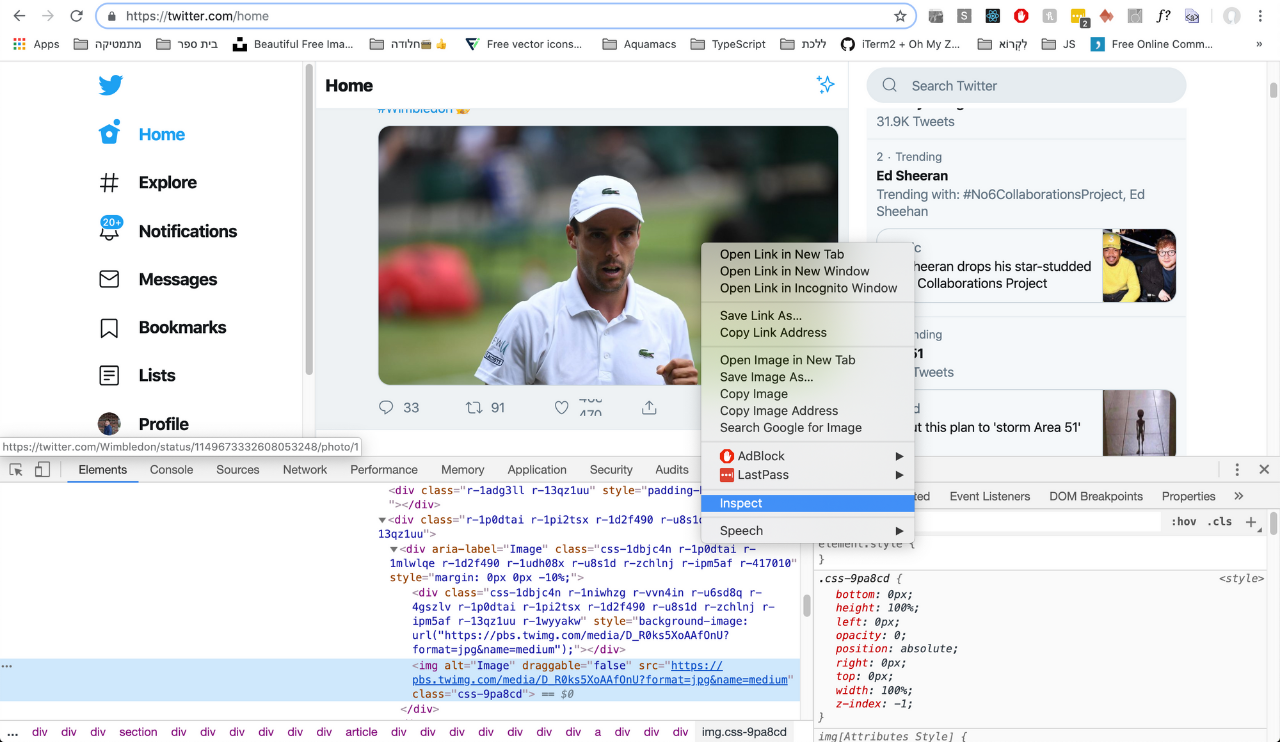
然后,我可以执行一个document.querySelector(<<SELECTOR>>).src ,这将为我提供所需图像的URL,并且可以在网页上使用它,例如:

这是网页抓取! 我无需访问数据库就可以从网站收集数据(图像)。 但这非常繁琐且冗长,因此为了更有效地进行网络抓取,我使用了Node.js和Puppeteer。
如果您还不了解, Node.js是一个运行时环境,它允许JavaScript在服务器端运行。 Puppeteer是Google编写的“无头Chrome节点API”(基本上,它允许您在服务器上编写DOM JavaScript代码)。
仅供参考,因为我喜欢TypeScript,所以我将在该项目中使用该语言。 如果要使用TypeScript,请在系统上安装它。 如果在终端上运行tsc -v产生打字稿版本,那就太好了!
好的,首先,请确保您在系统上安装了Node.js和npm(节点程序包管理器)。 如果通过运行以下command not found的command not found或相关内容,建议您查看有关如何安装Node的本文。
$ npm -v # should be6.0 .0 or higher $ node -v # should be 9.0 .0 or higher大! 让我们开始一个新项目并安装依赖项:
$ mkdir Web-Scraping-101 && cd Web-Scraping -101
$ npm init # go through all defaults
$ npm i puppeteer # the google npm scraping package
$ tsc --init # initialize typescript
$ npm i @types/puppeteer # type declarations 现在,在您选择的文本编辑器中打开文件夹。 将tsconfig.json文件中的outDir选项编辑为./build并取消注释该行,因此如下所示:
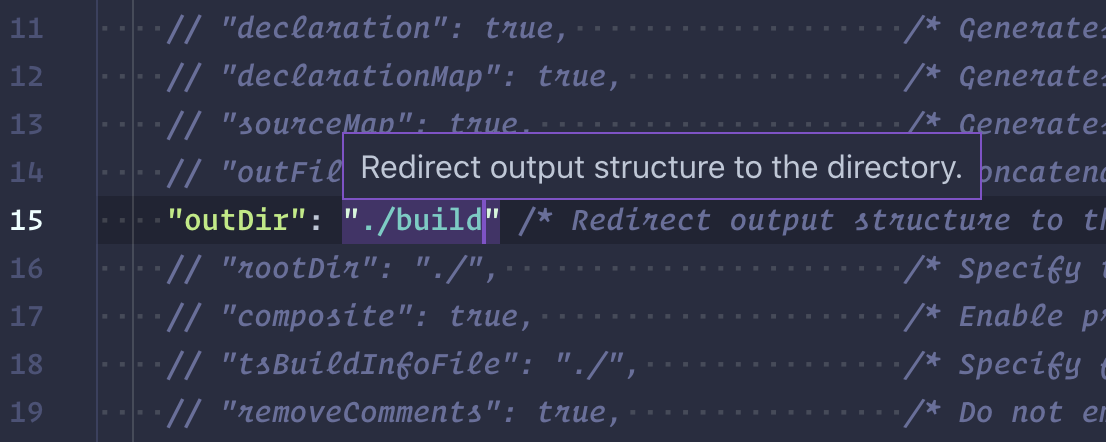
在文件夹的根目录中创建一个新文件: touch app.ts
在app.ts中添加:
console .log( "Twitter, here we come" ); 要运行此命令,请在终端中输入: tsc && node build/app.js
注意 : tsc将所有TypeScript文件构建到配置文件中定义的outDir目录中,并且node运行单个JavaScript文件。
如果您在终端中看到“ Twitter,我们来了” ,则说明它正常工作!
现在,我们将开始实际使用Puppeteer进行抓取。 将此样板app.ts代码添加到app.ts文件中:
import puppeteer from "puppeteer" ; // import the npm package that we installed
( async () => {
// the rest of the code must be enclosed in an `async` function to be able to `await` for results
const browser = await puppeteer.launch(); // launches an "invisible" chromium browser
const page = await browser.newPage(); // takes the browser to a new tab (page)
await page.goto( "https://example.com" ); // takes the page to a specific url
// Get the "viewport" of the page,
// as reported by the page.
// NOTE: Anything inside of the `evaluate` function is DOM manipulation.
// No variables outside of the evaluate function can go in, and none can come out without being returned inside of the return object.
const dimensions = await page.evaluate( () => {
return {
// use DOM manipulation to access the width and height of the page
// if you want to get elements out of the DOM and into the node js code, return theme here
width: document .documentElement.clientWidth,
height : document .documentElement.clientHeight,
deviceScaleFactor : window .devicePixelRatio
};
});
// print out the DOM data
console .log( "Dimensions:" , dimensions);
// remember to close the broser (invisible chromium)
await browser.close();
})();请通读上面注释的代码,以了解发生了什么。
既然您已经了解了如何访问网页,使用DOM操作收集信息并将该信息带回Node js程序,我们就可以抓取Twitter。
首先,将await page.goto("https://example.com")编辑为await page.goto("https://twitter.com") 。
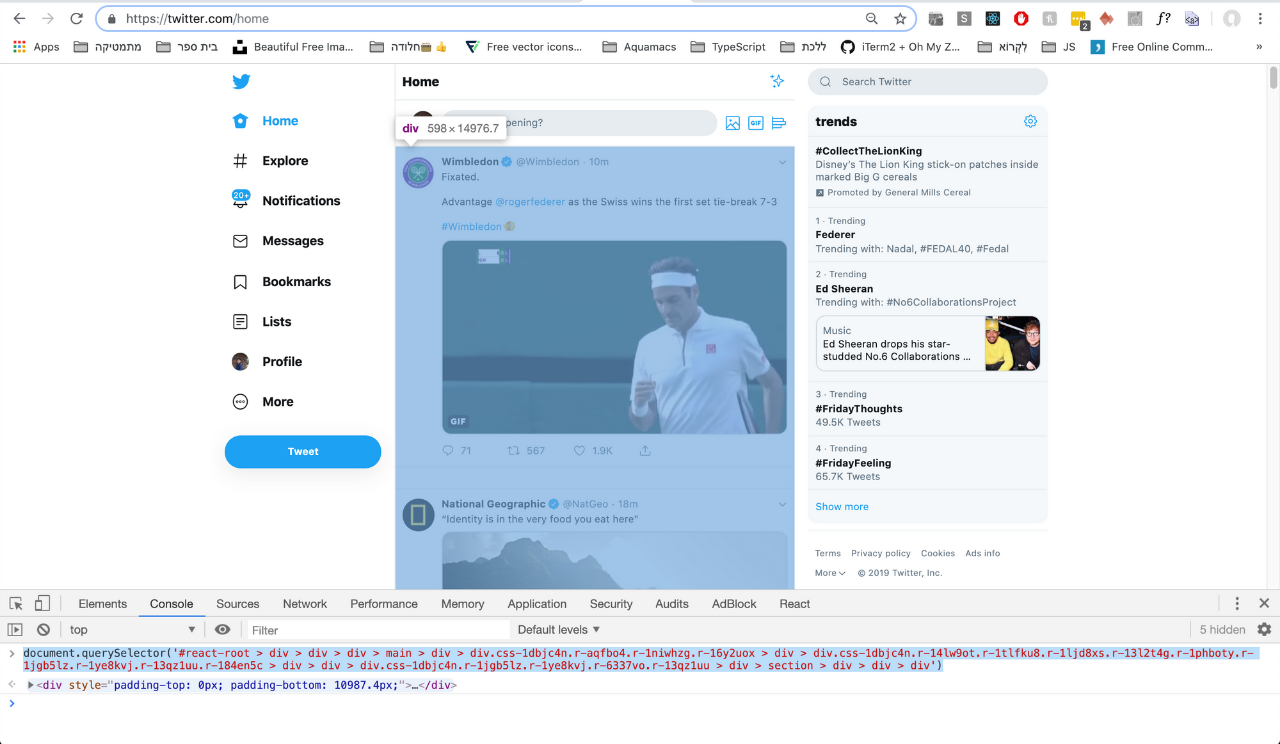
接下来,我们需要能够从中间一栏(实际的Twitter feed)获取帖子。 经过一番调查后,我发现此选择器实际上是为中间列供稿选择div选择器:
document .querySelector( "#react-root > div > div > div > main > div > div.css-1dbjc4n.r-aqfbo4.r-1niwhzg.r-16y2uox > div > div.css-1dbjc4n.r-14lw9ot.r-1tlfku8.r-1ljd8xs.r-13l2t4g.r-1phboty.r-1jgb5lz.r-1ye8kvj.r-13qz1uu.r-184en5c > div > div > div.css-1dbjc4n.r-1jgb5lz.r-1ye8kvj.r-6337vo.r-13qz1uu > div > section > div > div > div" );
// the above returns the div for the middle column twitter feed这是代表的图像:
为了从中间列获取所有图像,我最终对page.evaluate()函数执行了此操作:
const dimensions = await page.evaluate( () => {
let sources = []; // an array of the links to each image
document .querySelectorAll(
"#react-root > div > div > div > main > div > div.css-1dbjc4n.r-aqfbo4.r-1niwhzg.r-16y2uox > div > div.css-1dbjc4n.r-14lw9ot.r-1tlfku8.r-1ljd8xs.r-13l2t4g.r-1phboty.r-1jgb5lz.r-1ye8kvj.r-13qz1uu.r-184en5c > div > div > div.css-1dbjc4n.r-1jgb5lz.r-1ye8kvj.r-6337vo.r-13qz1uu > div > section > div > div > div img"
).forEach( img => {
if (img.src) {
sources.push(img)
}
});
return {
sources
}
} 现在,如果要编译所有图像源的列表并将其打印到控制台,我要做的就是在page.evaluate()函数外部编写此代码:
console .log(dimensions.sources);你去! 您刚刚从Twitter提要中抓取了图像数据。
最后的挑战是获取这些数据并将其集成到Express.js服务器中,这样,当用户转到根站点时,就会向他们显示所有这些已抓取的图像。
资源资源
谢谢阅读!
翻译自: https://hackernoon.com/data-scraping-in-nodejs-101-m32oi31yl















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









