





编码 面试
如何更快地准备面试编码?
编码面试每天都在变得越来越困难。 几年前,重新整理关键数据结构并进行50-75个练习题已经足够进行面试。 如今,每个人都可以访问大量的编码问题,而且他们也变得更加困难。 整个面试过程变得更具竞争力。
在这篇文章中,我想分享一个我为编写采访面试所遵循的策略。 我的软件工程生涯大约有15年,其中我已经换过5次工作。 我给出了大约30个面试循环,其中包含120多个面试。 我也有一些坐在桌子另一边的经验。 我参加了200多次编码面试和100多次系统设计面试。
我认为自己是位相当聪明的工程师,但是在白板上解决编码问题时遇到了挑战,尤其是在有人在评估我的面试环境中。 为了解决这个问题,我一直在花一些时间进行准备和练习。 我没有意识到的是,在准备过程中,我遵循的是系统的方法。
每天练习两个小时,我就能解决12-15个问题。 这意味着我可以在一个月内解决350多个问题。 使用此例程,我能够对FAANG(Facebook,Apple,Amazon,Netflix,Google)进行采访。
我如何全职工作每天练习12个以上的编码问题? 好吧,我不是在解决编码问题,而是尝试将问题“映射”到我之前已经解决的已知问题。
我曾经阅读过一个问题,花了几分钟时间将其映射到我之前见过的类似问题。 如果我可以映射它,那么我只关注与父问题相比该问题所具有的不同约束 。
如果这是一个新问题,那么我将尝试解决该问题,并四处阅读以找到其他人用来配置其算法的明智方法。 随着时间的推移,我开发了一套问题模式,这些模式帮助我快速地将问题“映射”到一个已知的模式。 以下是这些模式的一些示例:
- 如果给定的输入已排序(数组,列表或矩阵),那么我们将使用二进制搜索的一种变体或“ 两指针”策略。
- 如果我们要处理'n'个元素中top / maximum / minimum / closest'k'元素,则将使用
Heap。 - 如果我们需要尝试输入的所有组合(或排列),则可以使用递归Backtracking或迭代的“ 广度优先”搜索 。
遵循这种基于模式的方法可以帮助我节省很多准备时间。 一旦您熟悉了模式,就可以解决许多问题。 除此之外,这种策略使我对解决未知问题充满信心,因为我一直在努力将未知问题映射到已知问题。
在剩下的文章中,我将分享一段时间以来收集到的所有模式,并介绍一些示例问题。 有关这些模式及其解决方案相关问题的详细讨论,请参阅Grokking the Coding Interview 。

问题陈述:在给定的Bitonic数组中找到最大值。 如果阵列先单调递增然后单调递减,则该阵列被视为双调阵。 单调增加或减少意味着对于数组arr[i] != arr[i+1]中的任何索引i。
示例 : 输入 :[1、3、8、12、4、2], 输出 :12
解决方案:双音阵列是有序阵列; 唯一的区别是,其第一部分以升序排序,第二部分以降序排序。 我们可以使用二进制搜索的变体来解决此问题。 请记住,在二进制搜索中,我们具有start , end和middle索引,并且在每一步中,我们都通过移动start或end减小搜索空间。 由于没有两个连续的数字相同(因为数组是单调递增或递减的),因此每当我们计算Binary Search的middle索引时,我们就可以比较索引middle和middle+1指出的数字,以发现我们是否位于上升或下降部分。 所以:
- 如果
arr[middle] > arr[middle + 1],则我们位于双音阵列的第二个(降序)部分。 因此,我们所需的数字可以由middle指出,也可以在middle之前。 这意味着我们将要做:end = middle。 - 如果
arr[middle] <= arr[middle + 1],则我们位于双音数组的第一(升序)部分。 因此,所需的数字将在middle。 这意味着我们将要做:start = middle + 1。
我们可以在start == end时中断。 由于上述两点, start和end都将指向Bitonic数组的最大数目。
代码:这是解决此问题的Java代码:
class MaxInBitonicArray {
public static int findMax ( int [] arr) {
int start = 0 , end = arr.length - 1 ;
while (start < end) {
int mid = start + (end - start) / 2 ;
if (arr[mid] > arr[mid + 1 ]) {
end = mid;
} else {
start = mid + 1 ;
}
}
// at the end of the while loop, 'start == end'
return arr[start];
}
public static void main (String[] args) {
System.out.println(MaxInBitonicArray.findMax( new int [] { 1 , 3 , 8 , 12 , 4 , 2 }));
System.out.println(MaxInBitonicArray.findMax( new int [] { 3 , 8 , 3 , 1 }));
System.out.println(MaxInBitonicArray.findMax( new int [] { 1 , 3 , 8 , 12 }));
System.out.println(MaxInBitonicArray.findMax( new int [] { 10 , 9 , 8 }));
}
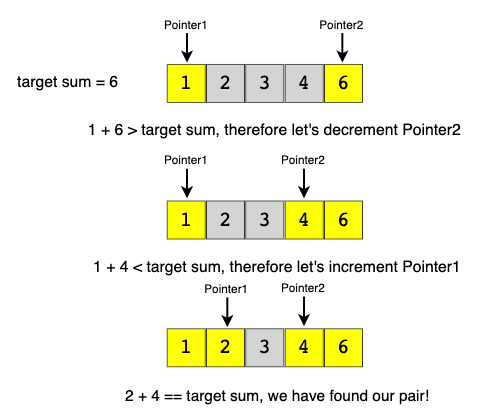
}两个指针的样本问题: 与目标总和配对
问题陈述:给定一个有序数字数组和一个目标总和,请在该数组中找到一对总和等于给定target的对 。
编写一个函数以返回两个数字(即该对)的索引,以使它们加起来成为给定的目标。
例: 输入 :[1,2,3,4,6], 目标 = 6, 输出 :[1,3](索引1和3的数字加起来为6:2 + 4 = 6)
解决方案:由于给定的数组已排序,因此蛮力解决方案可能是遍历该数组,一次获取一个数字,然后通过Binary Search搜索第二个数字。 该算法的时间复杂度将为O(N * logN)。 我们可以做得更好吗?
我们可以遵循“ 两个指针”方法。 我们将从一个指向数组开头的指针开始,另一个指向数组结尾的指针开始。 在每一步中,我们都会看到两个指针所指向的数字是否加起来等于目标总和。 如果他们这样做,我们就找到了一对。 否则,我们将执行以下两项操作之一:
- 如果两个指针所指向的两个数字的和大于目标和,则意味着我们需要一个对和较小的对。 因此,要尝试更多对,我们可以减少端点指针。
- 如果两个指针所指向的两个数字的和小于目标和,则意味着我们需要一个具有更大和的对。 因此,要尝试更多对,我们可以增加起始指针。
这是上述示例的该算法的直观表示:
代码:这是我们的算法的样子:
class PairWithTargetSum {
public static int [] search( int [] arr, int targetSum) {
int left = 0 , right = arr.length - 1 ;
while (left < right) {
// comparing the sum of two numbers to the 'targetSum' can cause integer overflow
// so, we will try to find a target difference instead
int targetDiff = targetSum - arr[left];
if (targetDiff == arr[right])
return new int [] { left, right }; // found the pair
if (targetDiff > arr[right])
left++; // we need a pair with a bigger sum
else
right--; // we need a pair with a smaller sum
}
return new int [] { - 1 , - 1 };
}
public static void main (String[] args) {
int [] result = PairWithTargetSum.search( new int [] { 1 , 2 , 3 , 4 , 6 }, 6 );
System.out.println( "Pair with target sum: [" + result[ 0 ] + ", " + result[ 1 ] + "]" );
result = PairWithTargetSum.search( new int [] { 2 , 5 , 9 , 11 }, 11 );
System.out.println( "Pair with target sum: [" + result[ 0 ] + ", " + result[ 1 ] + "]" );
}
}
示例问题: “ K”最接近原点的点
问题陈述:给定2D平面中的点阵列,找到距原点最近的'K'个点。
示例: 输入 :点= [[1,2],[1,3]],K = 1, 输出 :[[1,2]]
解:一个点P(x,y)距原点的欧几里得距离可以通过以下公式计算:
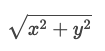
我们可以使用最大堆来找到最接近原点的“ K”点。 我们可以从堆中的第一个“ K”点开始。 在遍历其余点时,如果某个点(例如“ P”)比最大堆的顶部更靠近原点,我们将从堆中移除该顶部并添加“ P”以始终保持最接近点在堆中。
代码:这是我们的算法的样子:
import java.util.*;
class Point {
int x;
int y;
public Point ( int x, int y) {
this .x = x;
this .y = y;
}
public int distFromOrigin () {
// ignoring sqrt
return (x * x) + (y * y);
}
}
class KClosestPointsToOrigin {
public static List<Point> findClosestPoints (Point[] points, int k) {
PriorityQueue<Point> maxHeap = new PriorityQueue<>(
(p1, p2) -> p2.distFromOrigin() - p1.distFromOrigin());
// put first 'k' points in the max heap
for ( int i = 0 ; i < k; i++)
maxHeap.add(points[i]);
// go through the remaining points of the input array, if a point is closer to
// the origin than the top point of the max-heap, remove the top point from
// heap and add the point from the input array
for ( int i = k; i < points.length; i++) {
if (points[i].distFromOrigin() < maxHeap.peek().distFromOrigin()) {
maxHeap.poll();
maxHeap.add(points[i]);
}
}
// the heap has 'k' points closest to the origin, return them in a list
return new ArrayList<>(maxHeap);
}
public static void main (String[] args) {
Point[] points = new Point[] { new Point( 1 , 3 ), new Point( 3 , 4 ), new Point( 2 , - 1 ) };
List<Point> result = KClosestPointsToOrigin.findClosestPoints(points, 2 );
System.out.print( "Here are the k points closest the origin: " );
for (Point p : result)
System.out.print( "[" + p.x + " , " + p.y + "] " );
}
}
示例问题: 子集
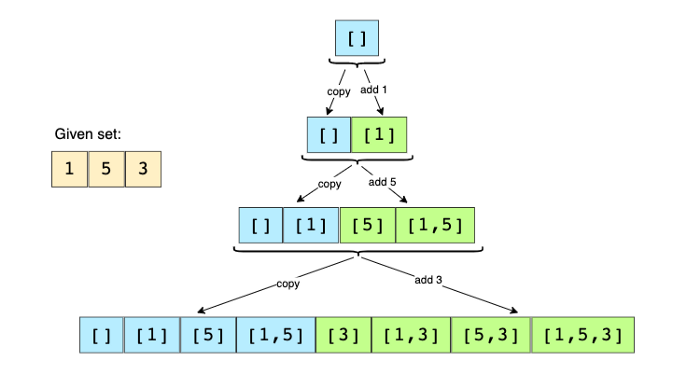
问题陈述 :给定具有不同元素的集合,找到其所有不同的子集。
示例: 输入 :[1,5,3], 输出 :[],[1],[5],[3],[1,5],[1,3],[5,3],[1, 5,3]
解决方案:要生成给定集合的所有子集,我们可以使用广度优先搜索(BFS)方法。 我们可以从一个空集开始,一个接一个地遍历所有数字,然后将它们添加到现有集中以创建新的子集。
让我们以上述示例为例,介绍算法的每个步骤:
给定的集合:[1、5、3]
- 从一个空集开始:[[]]
- 将第一个数字(1)添加到所有现有的子集以创建新的子集:[[], [1]] ;
- 将第二个数字(5)添加到所有现有子集:[[],[1], [5],[1,5] ];
- 将第三个数字(3)添加到所有现有子集:[[],[1],[5],[1,5], [3],[1,3],[5,3],[1, 5,3] ]。
这是上述步骤的直观表示:
代码:这是我们的算法的样子:
import java.util.*;
class Subsets {
public static List<List<Integer>> findSubsets( int [] nums) {
List<List<Integer>> subsets = new ArrayList<>();
// start by adding the empty subset
subsets.add( new ArrayList<>());
for ( int currentNumber : nums) {
// we will take all existing subsets and insert the current number in them to
// create new subsets
int n = subsets.size();
for ( int i = 0 ; i < n; i++) {
// create a new subset from the existing subset and
// insert the current element to it
List<Integer> set = new ArrayList<>(subsets.get(i));
set.add(currentNumber);
subsets.add(set);
}
}
return subsets;
}
public static void main (String[] args) {
List<List<Integer>> result = Subsets.findSubsets( new int [] { 1 , 3 });
System.out.println( "Here is the list of subsets: " + result);
result = Subsets.findSubsets( new int [] { 1 , 5 , 3 });
System.out.println( "Here is the list of subsets: " + result);
}
}示例问题: 二叉树路径总和
问题陈述 :给定一棵二叉树和一个数字“ S”,请确定该树是否具有从根到叶的路径,以使该路径的所有节点值之和等于“ S”。
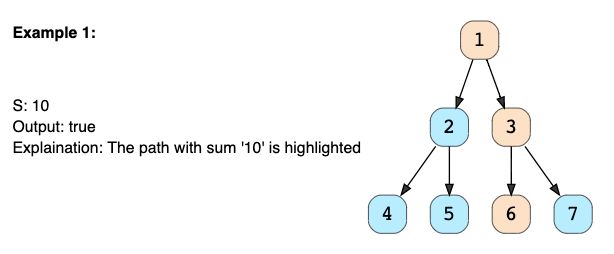
解决方案:在尝试搜索从根到叶的路径时,我们可以使用深度优先搜索(DFS)技术来解决此问题。
要以DFS方式递归遍历二叉树,我们可以从根开始,在每一步中,进行两个递归调用,一个用于左边,另一个用于右边的孩子。
这是解决“二叉树路径和”问题的步骤:
- 从树的根启动DFS。
- 如果当前节点不是叶节点,请执行以下两项操作:a)从给定的数字中减去当前节点的值以获得新的总和=>
S = S - node.value,b)对两个节点都进行两次递归调用上一步中计算出的具有新编号的当前节点的子级。 - 在每一步中,查看正在访问的当前节点是否为叶节点,并且其值是否等于给定的数字“ S”。 如果这两个条件都成立,则我们找到了所需的从根到叶的路径,因此返回
true。 - 如果当前节点是叶子,但是其值不等于给定的数字“ S”,则返回false。
代码:这是我们的算法的样子:
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode( int x) {
val = x;
}
};
class TreePathSum {
public static boolean hasPath (TreeNode root, int sum) {
if (root == null )
return false ;
// if current node is a leaf and its value is equal to the sum, we've found a path
if (root.val == sum && root.left == null && root.right == null )
return true ;
// recursively call to traverse the left and right sub-tree
// return true if any of the two recursive call return true
return hasPath(root.left, sum - root.val) || hasPath(root.right, sum - root.val);
}
public static void main (String[] args) {
TreeNode root = new TreeNode( 12 );
root.left = new TreeNode( 7 );
root.right = new TreeNode( 1 );
root.left.left = new TreeNode( 9 );
root.right.left = new TreeNode( 10 );
root.right.right = new TreeNode( 5 );
System.out.println( "Tree has path: " + TreePathSum.hasPath(root, 23 ));
System.out.println( "Tree has path: " + TreePathSum.hasPath(root, 16 ));
}
}





遵循这些模式,极大地节省了我的编码面试准备时间。 看一下编码访谈 和Growking动态编程模式用于访谈 查找更多此类模式及其样本问题。
翻译自: https://hackernoon.com/the-ultimate-strategy-to-preparing-for-the-coding-interview-yxts3zbg
编码 面试















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









