







1、http 协议
http 协议是一个超文本传输协议,位于应用层,所能包含的数据类型非常丰富(文字,图片,音频等等),最常见的就是应用在 web 浏览器中的,它的特性是请求 / 响应,客户端主动发起请求,服务端收到请求并处理,处理后返回客户端一个回应。
1.1、http 报文格式
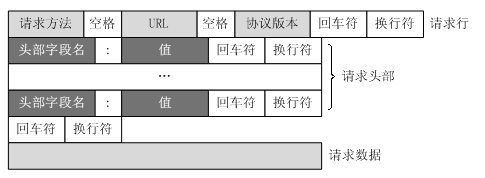
http 请求报文的格式如下,分三个部分:请求行,请求头部,请求数据。
图片来自:HTTP报文结构和内容(转) - myseries - 博客园
举个例子,http 请求报文如下:

http 响应报文的格式如下,分为三部分:状态行,响应头部,响应体。
图片来自:HTTP请求报文和响应报文详解 - 杨会清的个人网站

2、请求方法
2.1、get方法
get 方法用于获取具体资源的,比如获取一个 web 页面,请求数据为空,get 请求报文可以带上一些参数,但是这些参数放在 URL 里面,这样的话,除非将参数放进 URL 之前进行加密,否则参数就处于暴露状态,因此,get 方法不适用与传递隐秘数据,另外,浏览器对 URL 的长度是有限制的,因此,get 方法也不适用于传递大量数据。
2.2、post 方法 和 put 方法
这两种方法都可以在请求数据部分携带数据,可以携带大量数据,从技术角度讲,个人觉得这两种方法没有什么区别,只不过开发是一个遵循规则的过程,所以一定要遵循规则,语义上规定 post 方法用于在服务端创建一个资源,而 put 方法用于在服务端更新一个资源。另外,post 操作没有幂等性,put 操作有幂等性。
2.3、head 方法
head 方法用于查询请求某个资源的响应状态,服务端响应 head 请求时,只会返回状态行 + 响应头部(没有响应体),所以 head 方法高效轻便。
2.4、delete 方法
delete 方法用于删除某个资源。
2.5、options 方法
options 方法是一种探测性的请求,针对某个 URL,客户端发送 options 请求,浏览器会返回一个响应报文,告诉客户端这个 URL 的请求必须要遵守什么约束,比如:必须是哪些请求方法等等,在跨域中也会用到 options 请求,用于询问服务端是否允许本客户端访问。
2.6、trace 方法
很多地方就一句话:回显服务端收到的请求。如果不是提前已经了解了 trace 方法,否则根本看不懂这句话。客户端发起一个请求时,这个请求可能要经过一些安全监测或者过滤的节点。每个中间节点都可能会修改原始的HTTP请求。TRACE方法允许客户端在最终将请求发送给服务器时,看看它变成什么样子了。
2.7、connect 方法
connect 方法不是用于平时 web 网页开发的,而是用于代理服务器的,我们通过代理服务器就可以访问一些代理服务器才能访问的内容,代理服务器会监听某个端口,客户端通过TCP与代理服务器建立连接,客户端再向代理服务器发送 connect 方法的 http 请求报文,报文里包含了想要fq访问的那个服务器(假设是A)的域名,验证信息(账号,密码),验证信息是代理服务器来验证,如果代理服务器验证通过了,则返回通过信息给客户端,之后客户端就可以以一般的网页访问方式去访问A服务器了。
3、请求头部
1、User-Agent:用户代理,指客户端是什么类型的浏览器,如火狐、谷歌等等。
2、 Accept:客户端可识别的响应内容类型列表;星号 “ * ” 用于按范围将类型分组,用 “ / ” 指示可接受全部类型,用“ type/* ”指示可接受 type 类型的所有子类型;比如 Accept:text/xml(application/json)表示希望接受到的是xml(json)类型。
3、Accept-Language:客户端可以接受的语言是什么;
4、Accept-Encoding:浏览器声明自己接收的编码方法,通常指定压缩方法,支持什么压缩方法(gzip,deflate)。
5、Accept-Charset:客户端能接收的字符集是什么;
6、Host:客户端要请求访问的目的主机名,一般情况下是域名;http 请求行中都已经指明了 URL,还要 Host 字段干嘛呀?如果说服务端使用了虚拟主机技术,同一个IP地址和同一个端口对应着多个服务应用,URL 将域名解析成 IP 地址,通过 IP 地址找到服务主机,再通过端口号找到具体的服务应用,但是发现此时有多个服务应用,那到底是访问哪一个呀,这个时候就由 Host 字段来决定了,每个服务应用的域名肯定不一样(即多个域名绑定到同一个IP地址上),Host 字段就表明了要访问哪一个域名,这时候就知道要访问哪一个服务应用了。
7、Cookie:如果浏览器内有该域名的 Cookie 内容,那么此次请求的头部就会带上这些 Cookie。
8、Authorization:用于身份认证,一般 web 项目的话,都是用 Cookie 来做认证,而 Authorization 用于 pc 端上的客户端应用程序与服务端的身份认证,客户端将身份认证信息(账号,密码或者 token)经过编码后放在 Authorization 处,发给服务端,服务端进行认证。
9、Cache-Control:客户端(浏览器)缓存机制,将从服务端获取到的数据(资源)缓存在本地,下一次再发起数据请求时,可以先查看本地的缓存中是否有,数据是否还可用,如果是的话,浏览器就会把请求拦截下, 不让请求发送出去,而是直接从本地缓存中获取即可。如果 Cache-Control :no-cache 表示禁止使用本地缓存,即每次都是要去请求服务端,从服务端获取数据,如果 Cache-Control:max-age = 0 表示用户发起资源请求时(本地缓存中有),只是服务端询问浏览器本地缓存中的该资源是否还可以用(有效吗?资源有更新吗?),服务端就检查,如果可用,则返回 304 状态,浏览器就知道可以从本地缓存里获取资源了,如果返回的是 200 状态,说明本地资源不可用了,响应报文中就一定包含了新的可用的资源,浏览器就知道要从响应报文中去获取资源了。
10、Connection:http 默认是长连接(短连接是浏览器先向服务端发起TCP连接请求,建立连接后,发起一次请求过去,服务端返回响应报文就关闭连接,这就是短连接,好处是不过多占用服务端资源,坏处是频繁TCP连接浪费资源和时间,Connection :close 就表示告诉服务端,此次请求是短连接,你返回响应后就关闭连接吧),默认长连接的意思就是,即便 http 请求报文中的头部没有包含 Connection 字段,服务端也默认按长连接处理,但是这个连接不可能一直这样占着吧,什么时候断开呢?这个时候就有个最大空闲时间来控制,如果在最大空闲时间内浏览器都没有向服务端发起过请求,那么服务端自动关闭连接。Connection:keep-Alive = 60 表示最大空闲时间为 60 秒,默认就是 60 秒。
如果有很多浏览器都是活跃的,一直保持着长连接,那服务端的连接数量一旦被耗光,那别的用户就没法连接上服务端了,形成拒绝服务攻击,所以服务端要设计成分布式集群,增强并发处理能力。
11、Content-Length:请求报文中请求数据内容的长度,单位字节。
12、Content-Type:请求报文中请求数据的类型,比如:application/x-www-form-urlencoded、application/json、text/xml。
13、Date:请求报文发送的时间,可以被用来判断数据或者资源的新鲜度。
14、Expect:此处请求(带上 Expect 字段)只是告诉服务端,浏览器期待的是什么状态码,如果不是那个状态码,浏览器是不会进行剩余的请求的,而是只会进行新的任务请求。举个例子,post 请求提交一个非常大的数据,有可能服务端不会接受这么大的数据,所以我们在直接 post 之前,可以先发送一个带有 Expect 字段的请求,询问服务端是否可以接受,如果可以,那么服务端返回浏览器期待的那个状态码,浏览器才会执行 post 请求。 Expect: 100-continue 表明期待 100 状态码。
15、From:告诉服务端,用户的电子邮件地址。
16、If-Match:指定的是 Etge 值,服务器会检查这个值与浏览器要请求的资源的 Etge 值是否一致,只有一致时,才允许访问,否则响应412。 Etge 值可以代表资源是否变动过。
17、If-None-Match:与 If-Match 恰恰相反,只有当 Etge 值不一致时,才允许访问。
18、If-Modified-Since:指定的是一个时间点,告诉服务端,浏览器要请求的资源必须在此时间点之后修改过的。否则响应 304。
19、If-Unmodified-Since:与 If-Modified-Since 恰恰相反。
20、Range:设置一个范围,表示请求资源的该范围内的部分,范围格式为:单位=起始-末尾,单位常见为 bytes,表示按字节,比如 bytes=1000-3000,请求资源的第1000个字节到3000个字节的内容。bytes=1000-,表示请求资源第1000个字节到资源末尾。如果浏览器请求的范围有效,则服务端响应306,否则响应416或者响应200表示忽略。
21、If-Range:设置为一个 Etag 值或者时间点,与 Range 字段一起使用,目的是让服务端判断请求的部分资源是否被修改过了,如果没有,服务端就返回 Range 指定的范围,如果有,服务端返回整个资源给浏览器。
22、Max-Forwards:通过 TRACE 方法或 OPTIONS 方法,发送含有首部字段 Max-Forwards 的请求时,该字段以十进制整数形式指定可经过的服务器最大数目。服务器在往下一个服务器转发请求之前,会将 Max-Forwards 的值减一后重新赋值。当服务器接收到 Max-Forwards 值为 0 的请求时,则不再进行转发。而是直接返回响应。 使用 HTTP协议通信时,请求可能会经过代理等多台服务器。途中,如果代理服务器由于某些原因导致请求转发失败,客户端也就等不到服务器返回的响应了。对此,我们无从可知。 可以灵活使用首部字段 Max-Forwards 字段值为 0 ,服务器就会立即返回响应,由此我们至少可以对以那台服务器为终点的传输路径的通信状况有所把握。
23、Proxy-Authorization:和 Authorization 功能一样,只不过此认证是浏览器与代理服务端的。
24、Referer:为一个 url 值,表示从此请求是从哪个页面发出的,比如我们请求了一个 html 页面,但是此页面中又有其它的请求需要发送出去,那么发送出去的请求的 Referer 字段就是该 html 页面的 url。当然也可以不设置 Referer 值。
4、响应头部
1、Accept-Ranges:表示服务端是否支持范围请求,如果是none,表示不支持,如果是单位,比如bytes,就表示支持范围请求,以字节为单位。问题来了?什么是范围请求:即能够请求服务端上的某个资源的一部分(按照范围来划分),比如当下载一个文件时,已经下载了一部分,但是突然断网,此时,如果服务端支持范围请求的话,电脑连上网后,能够接着之前断开的位置继续下载剩下的部分,而不是重头开始下载文件。
2、Age:表示服务端多久之前创建的此响应,单位为秒。
3、Etge:Etge 值是唯一标识资源的,同一个资源发生变动之后,Etge 值也会改变,就好像 java 中的 hashcode 一样。服务端告诉浏览器,你请求的资源的 Etge 值为多少。
4、Location:表示一个 url 值,告诉浏览器:你要访问的资源不在我这,而是在这个 Location 指定的位置,你去访问吧。浏览器会自动重新向 url 发起请求。此功能一般用于重定向。
5、Retry-After:表示一个时间值或者时间点,告诉浏览器:你要在多久之后再请求,或者在哪个时间点之后再请求。
6、Server:表示服务端的http应用程序的信息,比如容器是什么(Tomcat、Apache等)、版本是多少,是 unix 吗?。
7、WWW-Authenticate:告诉浏览器需要提供认证信息。
8、Cache-Control、Connection、Date 都与请求头部的一样。
9、Warning:警告信息。
10、Upgrade:告诉浏览器升级为其它协议。
5、http 响应状态码
200:客户端请求成功,并接收到服务端的响应。
301:客户端请求的资源已经被移动到别处了,服务端会将资源的新地址 url 设置到响应头部的 location 变量,如果客户端是浏览器,那么会自动使用新地址去请求资源。
302:与 301 类似,只是 location 变量包含的是临时的 url 地址。
304:在使用缓存机制的情况下,客户端请求资源时,请求头会带上资源的本地缓存情况,服务器以此来判断客户端的资源缓存是否仍然有效,如果有效,那么服务端响应304,告诉客户端可以直接使用你的本地缓存,如果无效,服务端会返回最新的资源给客户端,响应为200。
401:当客户端请求访问一个需要认证的页面时,需要在请求头中携带认证信息,如果没有,服务端会响应401,表示告诉客户端,你未认证。比如你还没有登录某个系统,你就直接访问某个页面,就会让你先去认证,只要你再次携带上正确的认证信息,那就可以了。
403:当客户端请求访问一个需要权限的页面时,一般需要携带唯一标识信息,服务端根据你的唯一标识去查询你是否有访问该页面的权限,如果没有,就直接响应403,告诉客户端,我知道你想访问哪个页面,但是你没有权限,所以禁止你访问。比如你已经登录了某个系统,但是你只是个普通用户,只有部分权限,当你访问了一个高级用户才能访问的页面时,就会禁止访问。
401 和 403 可能有些混淆,但是如果用过权限框架的话,就能够明白两者的区别, 401 代表没有认证,403 代表没有权限,认证和权限是两回事。
404:客户端请求的资源在服务端找不到。
500:客户端请求的资源是存在的,只是服务端在处理客户端请求时发生了bug,属于服务器内部错误,响应为 500。
502:bad gateway,如果客户端与服务端之间有代理网关的话,那可能是网关出错(访问不到目标服务)导致的,如果没有的话,可能是服务端的连接数太多,导致无法正常响应客户端的请求。
100:场景为客户端发送一个请求,头部包含 Expect::100-continue,表示本次请求期待得到一个响应码为 100 的请求,什么情况下客户端会发送这样的请求呢?当客户端需要去尝试获得服务端的允许时(比如上传个大文件,可以先发送一个此请求去询问服务端是否允许),就可以发送一个这样的请求去尝试询问,如果服务端同意了,就会响应一个 100 ,客户端收到 100 后,就会继续发送后续的请求了。
101:服务端已经同意客户端的切换协议请求,并响应 101 告诉客户端。














 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









