







ARM_v8_architecture_Programmer Guide
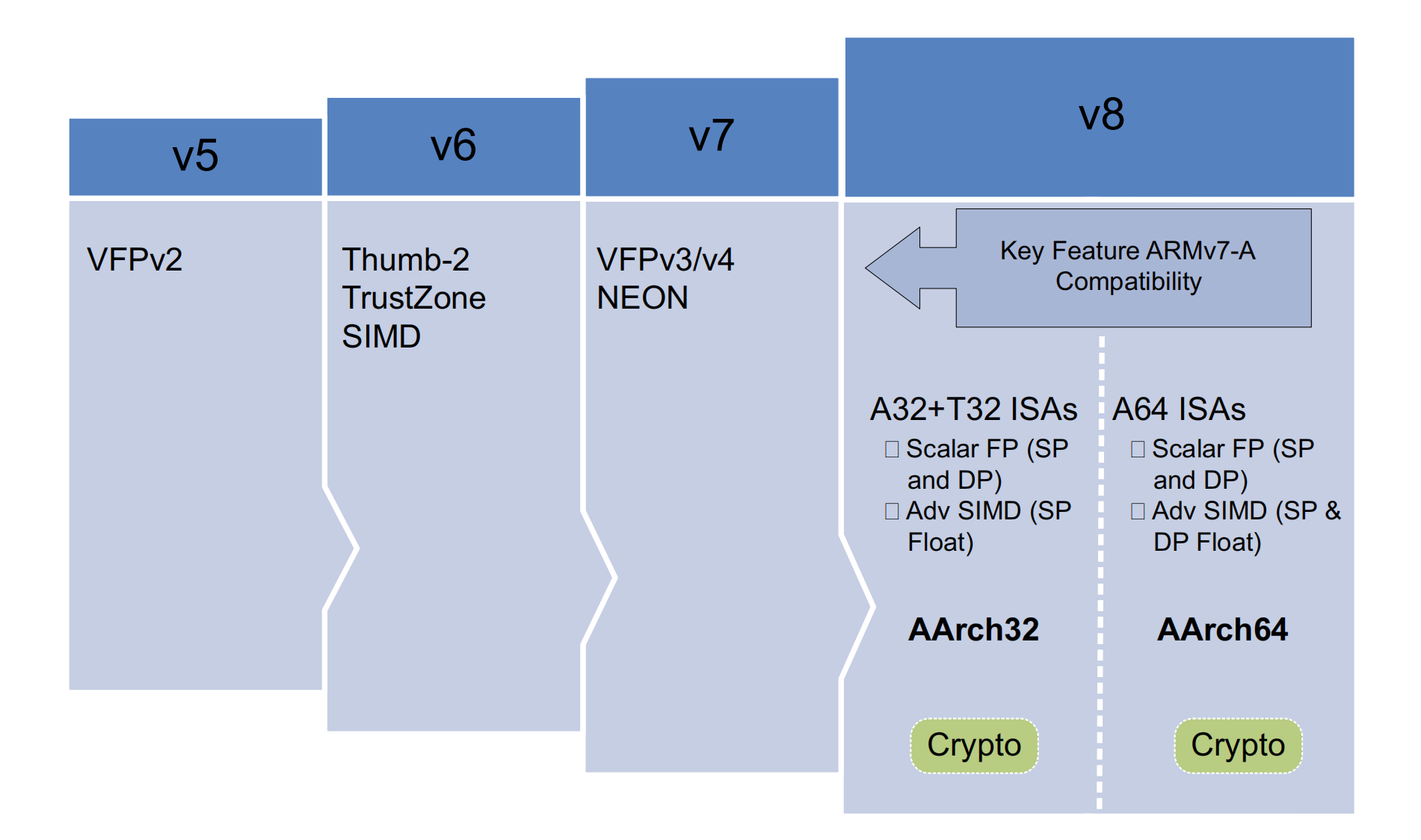
ARM架构的历史可以追溯到1985年,但它并非一成不变。相反,自早期的ARM内核问世以来,它经历了巨大的发展,每一步都在不断增加新的特性和功能。
ARMv4及更早版本
这些早期处理器仅使用ARM 32位指令集。
ARMv4T
ARMv4T架构在ARM 32位指令集的基础上增加了Thumb 16位指令集。这是首个被广泛授权使用的架构,由ARM7TDMI®和ARM9TDMI®处理器实现。
ARMv5TE
ARMv5TE架构针对数字信号处理(DSP)类型的操作、饱和算术运算以及ARM与Thumb指令集的交互工作进行了改进。ARM926EJ - S®处理器实现了该架构。
ARMv6
ARMv6进行了多项改进,包括支持非对齐内存访问、对内存架构进行重大更改以及支持多处理器。此外,还支持在32位寄存器内对字节或半字进行单指令多数据(SIMD)操作。ARM1136JF - S®处理器实现了该架构。ARMv6架构还提供了一些可选扩展,特别是Thumb - 2和安全扩展(TrustZone®)。Thumb - 2将Thumb扩展为包含16位和32位指令的混合长度指令集。
ARMv7 - A
ARMv7 - A架构强制要求使用Thumb - 2扩展,并增加了高级SIMD扩展(NEON)。在ARMv7之前,所有内核基本上都遵循相同的架构或特性集。为了更好地满足日益多样化的应用需求,ARM引入了一组架构配置文件:
-
ARMv7 - A:提供支持诸如Linux等平台操作系统所需的所有特性。
-
ARMv7 - R:提供可预测的实时高性能。
-
ARMv7 - M:目标应用为深度嵌入式微控制器。
ARM还为ARMv6架构添加了M配置文件,以便为旧架构增添新特性。ARMv6M配置文件被用于低成本、低功耗的微处理器。
2.1 ARMv8-A
ARMv8 - A架构是面向应用程序配置文件的最新一代ARM架构。“ARMv8”这一名称用于描述整个架构,该架构如今同时支持32位执行和64位执行。它引入了使用64位宽寄存器执行操作的能力,同时还保留了与现有ARMv7软件的向后兼容性。
ARMv8 - A架构引入了一系列变革,使得设计出性能大幅提升的处理器成为可能。
-
大物理地址
这让处理器能够访问超过4GB的物理内存。
-
64位虚拟寻址
这使得虚拟内存能够突破4GB的限制。对于使用内存映射文件输入/输出或稀疏寻址的现代桌面和服务器软件而言,这一点至关重要。
-
自动事件信号机制
这有助于实现节能高效的高性能自旋锁。
-
更大的寄存器组
31个64位通用寄存器能够提升性能并减少栈的使用。
-
高效的64位立即数生成
减少了对文字池的需求。
-
大的程序计数器(PC)相对寻址范围
拥有正负4GB的寻址范围,可在共享库和位置无关可执行文件中实现高效的数据寻址。
-
额外的16KB和64KB转换粒度
这降低了转换后备缓冲器(TLB)的缺失率以及页表遍历的深度。
-
新的异常模型
这降低了操作系统和虚拟机管理程序软件的复杂度。
-
高效的缓存管理
用户空间的缓存操作提高了动态代码生成的效率。利用数据缓存清零指令能够快速清除数据缓存。
-
硬件加速的加密功能
使软件加密性能提升3到10倍。这对于小粒度的解密和加密也很有用,因为这些操作规模太小,无法高效地卸载到硬件加速器上处理,例如HTTPS协议相关的加密解密。
-
加载获取(Load - Acquire)、存储释放(Store - Release)指令
专为C++11、C11和Java内存模型设计。它们通过消除显式的内存屏障指令,提高了线程安全代码的性能。
-
NEON双精度浮点高级单指令多数据(SIMD)
这使得SIMD向量化能够应用于更广泛的算法集合,例如科学计算、高性能计算(HPC)和超级计算机领域。
2.2ARMv8-A Processor properties
表2 - 1对比了ARM公司支持ARMv8 - A架构的处理器实现的各项特性。
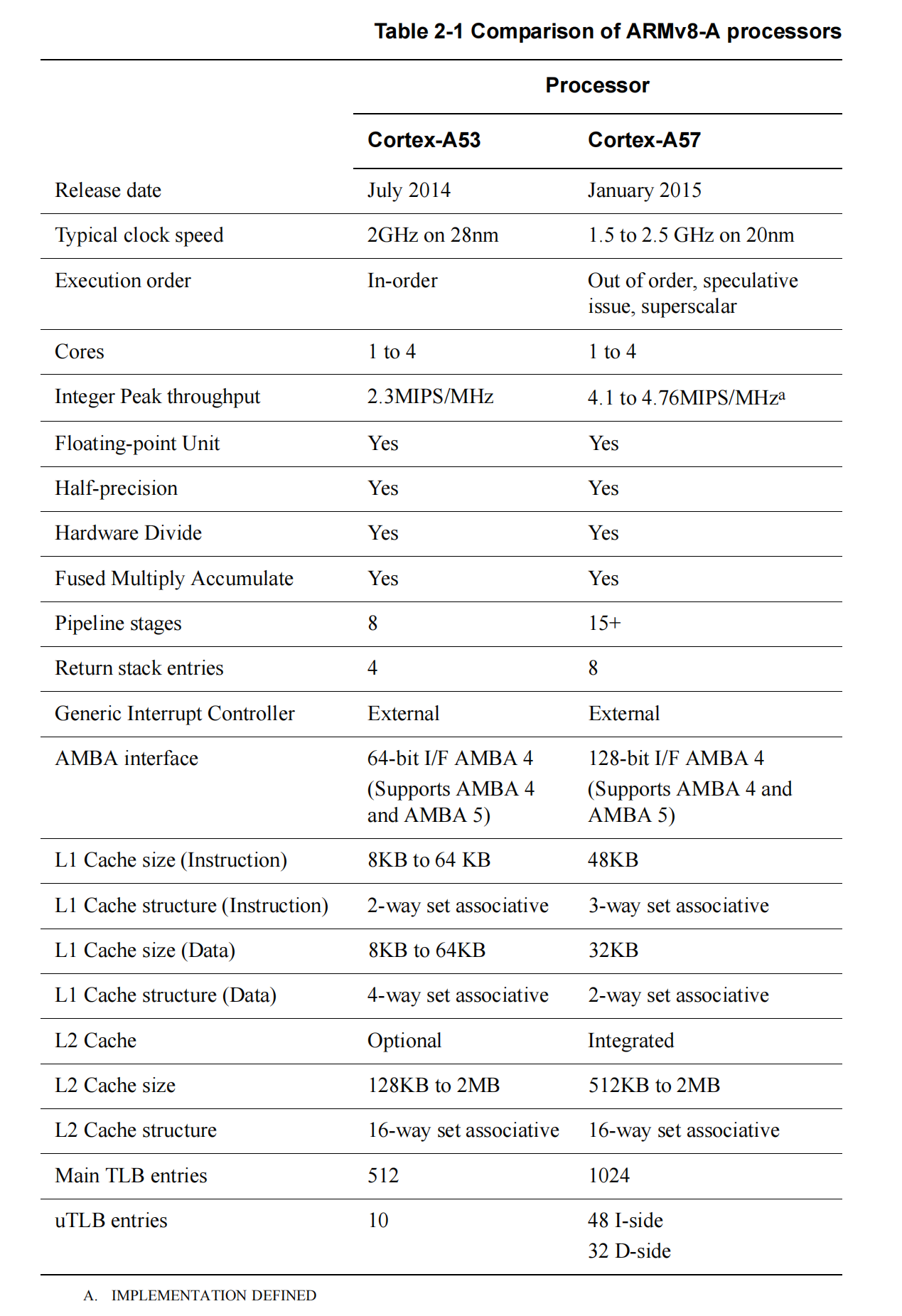
表内容对比
| 特性 | Cortex - A53 | Cortex - A57 |
|---|---|---|
| 发布日期 | 2014年7月 | 2015年1月 |
| 典型时钟速度 | 28纳米工艺下可达2GHz | 20纳米工艺下1.5至2.5GHz |
| 执行顺序 | 按序执行 | 乱序执行、推测发射、超标量 |
| 核心数量 | 1至4个 | 1至4个 |
| 整数峰值吞吐量 | 2.3 MIPS/MHz | 4.1至4.76 MIPS/MHza a. 具体实现定义 |
| 浮点单元 | 有 | 有 |
| 半精度支持 | 支持 | 支持 |
| 硬件除法 | 支持 | 支持 |
| 融合乘加运算 | 支持 | 支持 |
| 流水线级数 | 8级 | 15级以上 |
| 返回栈条目数 | 4个 | 8个 |
| 通用中断控制器 | 外部 | 外部 |
| AMBA接口 | 64位接口AMBA 4(支持AMBA 4和AMBA 5) | 128位接口AMBA 4(支持AMBA 4和AMBA 5) |
| L1缓存大小(指令) | 8KB至64KB | 48KB |
| L1缓存结构(指令) | 2路组相联 | 3路组相联 |
| L1缓存大小(数据) | 8KB至64KB | 32KB |
| L1缓存结构(数据) | 4路组相联 | 2路组相联 |
| L2缓存 | 可选 | 集成 |
| L2缓存大小 | 128KB至2MB | 512KB至2MB |
| L2缓存结构 | 16路组相联 | 16路组相联 |
| 主TLB条目数 | 512个 | 1024个 |
| uTLB条目数 | 10个 | 指令侧48个 数据侧32个 |
2.2.1 ARMv8 processors
本节介绍了实现ARMv8 - A架构的各个处理器。在每种情况下,仅提供了一般性的描述。如需获取每个处理器的更详细信息,请参阅第2 - 5页的表2 - 1。
Cortex - A53处理器
Cortex - A53处理器是一款中低端、低功耗的处理器,在单个集群中拥有1到4个核心,每个核心都配备一个一级(L1)缓存子系统、一个可选的集成式通用中断控制器v3/4(GICv3/4)接口,以及一个可选的二级(L2)缓存控制器。
Cortex - A53处理器是一款能效极高的处理器,能够支持32位和64位代码。与极为成功的Cortex - A7处理器相比,它的性能有显著提升。它既可以作为独立的应用处理器来部署,也可以与Cortex - A57处理器以大小核(big.LITTLE)架构进行配对,从而实现最佳性能、可扩展性和能源效率。
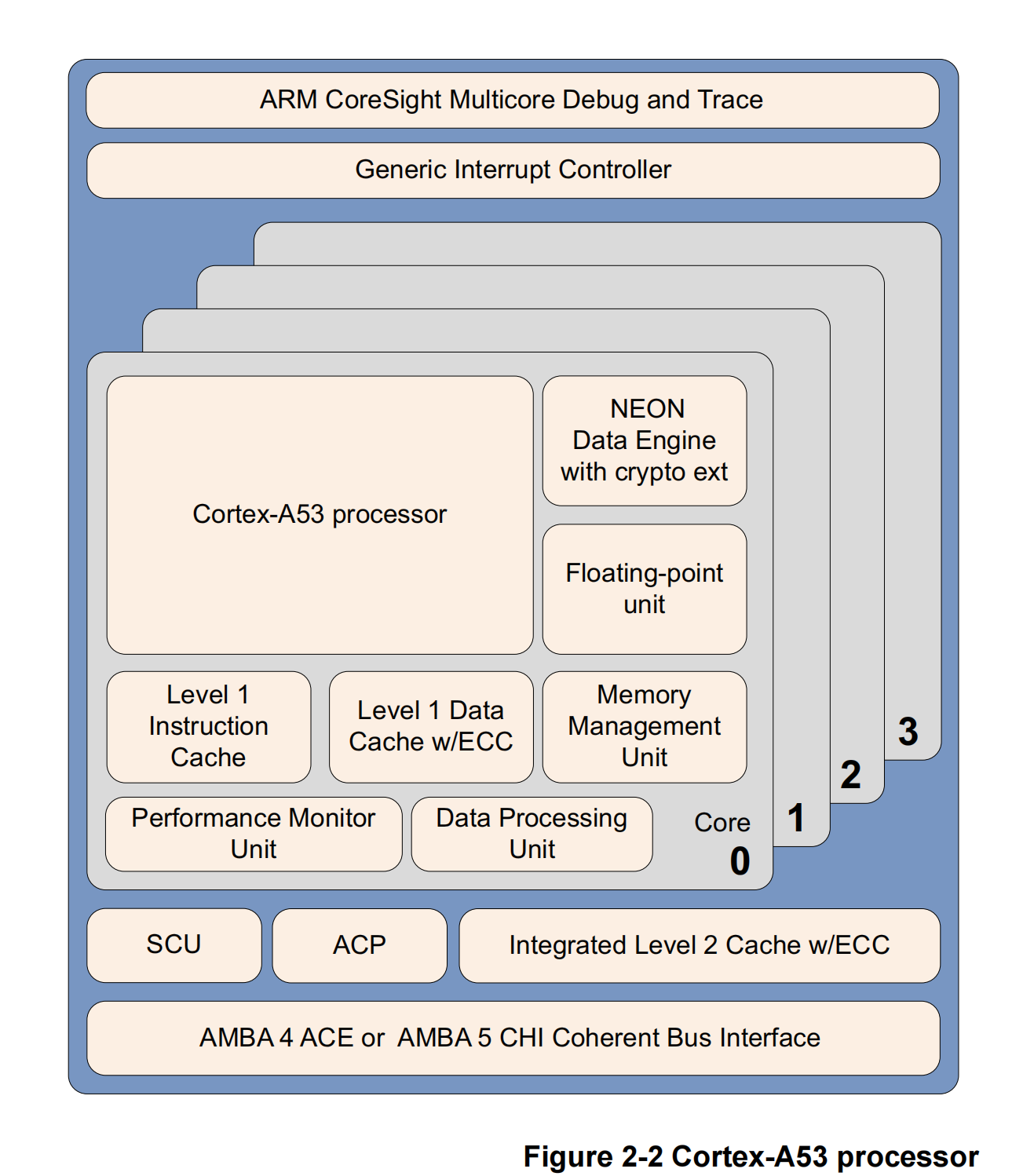
Cortex - A53处理器具备以下特性:
-
按序执行的八级流水线。
-
通过采用分层时钟门控、电源域和先进的保留模式,降低了功耗。
-
通过复制执行资源和采用双指令解码器,提高了双指令发射能力。
-
经过功耗优化的二级(L2)缓存设计,可降低延迟,并在性能和效率之间实现平衡。
Cortex - A57处理器
Cortex - A57处理器面向移动和企业计算应用,包括对计算要求较高的64位应用,如高端计算机、平板电脑和服务器产品。它可以与Cortex - A53处理器搭配,组成ARM大小核(big.LITTLE)架构,以实现可扩展的性能和更高效的能源利用。
Cortex - A57处理器的特点是能与其他处理器实现缓存一致性互操作,其中包括ARM Mali™系列图形处理单元(GPU),可用于GPU计算,并且为高性能企业应用提供可选的可靠性和可扩展性特性。与ARMv7 Cortex - A15处理器相比,它能显著提升性能,同时具备更高的能效水平。该处理器加入了加密扩展功能,与上一代处理器相比,其加密算法的性能提升了10倍。
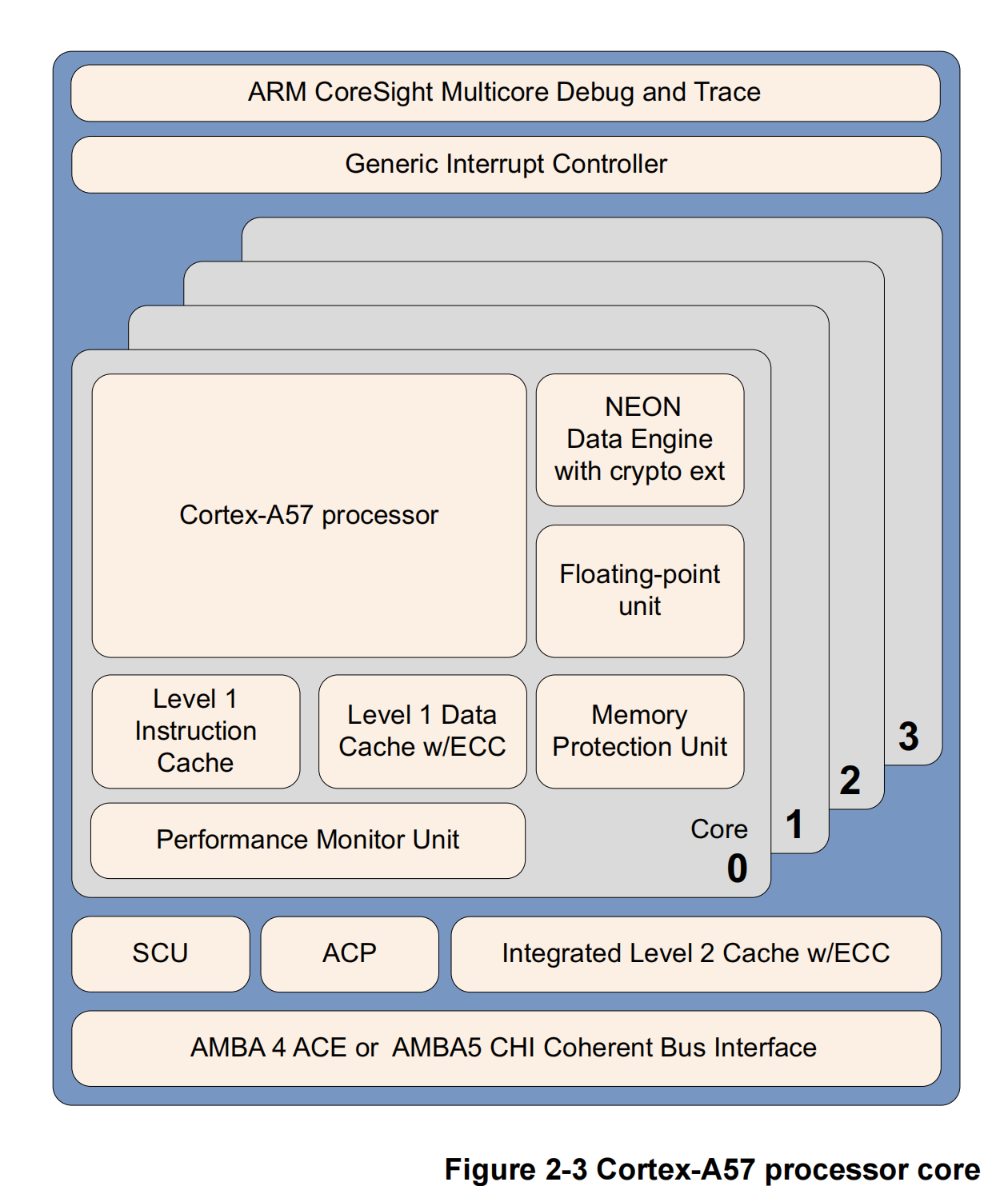
Cortex - A57 处理器
Cortex - A57 处理器全面实现了 ARMv8 - A 架构。它支持在单个集群内进行 1 到 4 核的多处理多核运算。通过 AMBA5 CHI 或 AMBA 4 ACE 技术,还可以实现多个具备一致性的对称多处理(SMP)集群。借助 CoreSight 技术可进行调试和追踪。
Cortex - A57 处理器具备以下特性:
-
乱序执行的 15 级以上流水线。
-
节能特性包括路预测、标签缩减和缓存查找抑制。
-
通过复制执行资源提高了指令峰值吞吐量。采用本地化解码、3 路解码带宽的功耗优化型指令解码方式。
-
经过性能优化的二级(L2)缓存设计,可使集群中的多个核心同时访问 L2 缓存。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











