








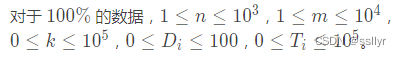
分析
这道题我调了5h。。。
一个很显然的思路,加速器应该惠及尽量多的游客,也就是只要计算出在每个站点使用加速器对答案的贡献,就直接贪心即可。
先说要记录的几个量:每个站点最后一个到车站的游客开始等车的时间(late),到每个站的时间(key),某站下车的人数(down)。
求法:late打擂台即可,key需要递推,因为不能确定是人先到齐还是车等人到,所以 k e y [ i ] = m a x ( k e y [ i − 1 ] , l a t e [ i − 1 ] ) + d [ i − 1 ] key[i]=max(key[i-1],late[i-1])+d[i-1] key[i]=max(key[i−1],late[i−1])+d[i−1] ,down开桶统计就行。
然后枚举每个加速器和每个站(
n
∗
k
n*k
n∗k 可以过),因为对于一个加速器,ta能影响到的站点只有在这个站后面人在等车的站,原因显然 :如果你加速了早点到了还是要等一个人慢吞吞地上车,等于浪费时间,还不如不用加速器。所以在判断的时候一个加速器能影响到出现“车等人”情况的站的前面。这一点是写题的时候没想到的。
只要每用一个加速器就更新一次key,最后统计答案累加每个人的就可以了。
上代码
感动中国
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
typedef long long ll;
struct node
{
int t,u,v;
}a[10010];
int n,m,k;
int d[1010],down[1010],key[1010],late[1010];
/*l->r,距离,某站后下车人数,到某站的时间,某站最晚上车的人的时间*/
ll total;
int main()
{
// freopen("a.in","r",stdin);
// freopen("a.out","w",stdout);
cin>>n>>m>>k;
for(int i=1;i<=n-1;i++)
{
scanf("%d",&d[i]);
}
for(int i=1;i<=m;i++)
{
scanf("%d%d%d",&a[i].t,&a[i].u,&a[i].v);
down[a[i].v]++;
late[a[i].u]=max(late[a[i].u],a[i].t);
}
// for(int i=1;i<=n-1;i++) cout<<down[i]<<' ';
// cout<<endl;
// for(int i=1;i<=n-1;i++) cout<<late[i]<<' ';
// cout<<endl;
key[1]=0;
for(int i=2;i<=n;i++)
{
key[i]=max(key[i-1],late[i-1])+d[i-1];
}
// for(int i=1;i<=n;i++) cout<<key[i]<<' ';
// cout<<endl;
while(k--)
{
int mx=0,mxp=0;
for(int i=1;i<n;i++)
{
if(d[i]<=0) continue;
int w=0;
for(int j=i+1;j<=n;j++)
{
w+=down[j];
if(key[j]<=late[j]) break;
}
if(w>mx)
{
mx=w;
mxp=i;
}
}
d[mxp]--;
for(int i=mxp+1;i<=n;i++)
{
key[i]=max(key[i-1],late[i-1])+d[i-1];
if(key[i]<late[i]) break;
}
}
for(int i=1;i<=m;i++)
{
total+=(key[a[i].v]-a[i].t);
}
cout<<total;
return 0;
}















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









