






 本文介绍了如何使用Keras的一维卷积(Conv1D)进行文本分类。通过imdb_cnn.py示例,展示了数据预处理、模型构建以及各层的作用。在模型中,Embedding层将文本转换为固定长度的向量,Dropout层防止过拟合,Conv1D层用于特征提取,GlobalMaxPooling1D提取最大特征,最后通过全连接层和激活函数完成分类任务。
本文介绍了如何使用Keras的一维卷积(Conv1D)进行文本分类。通过imdb_cnn.py示例,展示了数据预处理、模型构建以及各层的作用。在模型中,Embedding层将文本转换为固定长度的向量,Dropout层防止过拟合,Conv1D层用于特征提取,GlobalMaxPooling1D提取最大特征,最后通过全连接层和激活函数完成分类任务。
最近,我跑一些Keras的例子,入门NLP。
今天,跑了imdb_cnn.py,是一维卷积做文本分类。
imdb.load_data之后,x_train和x_test每一样本为list,或者理解为一个向量,代表一个文本;y_train和y_test每一样本为int64整数,取值为0或者1,0代表文本的评价为“不好”,1代表文本的评价为“好”。训练样本集和测试样本集的容量为25000。
sequence.pad_sequences对样本进行padding处理,因为每一样本的长度不定,比如x_train[0]为218,x_train[1]为189,padding之后,长度固定了。x_train的shape为(25000, 400)。pad_sequences参考Keras文档(英文,中文),按照代码,那就是每一样本的长度不足400,前面补零。
model.Sequential()创建序贯模型。模型涉及Embedding、Dropout、Conv1D、GlobalMaxPooling1D、Dense和Activation层。模型如下:
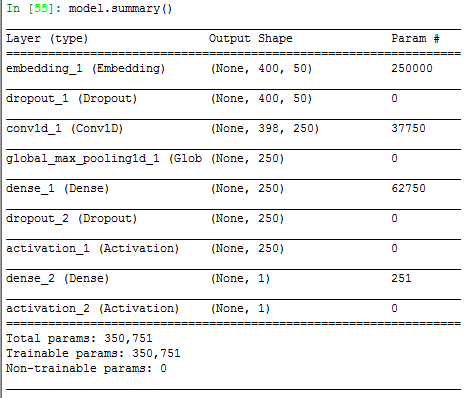
说一说,各层的计算和作用。
第一层是Embedding层,把正整数映射为固定长度的向量,正整数可以理解为一个个词,也就是400代表文本有400个词,然后把400个词映射到每个词长度为50的向量。所以,一共400*50维。这里是word embedding或者新兴的word2vec吧。主要完成文本向量化、语言向量化,或者叫做数字化,供后面计算之用。
第二层是Dropout层,取消某些神经元的学习。读了给出的参考文献。。。对于没有nlp和rnn基础的人,尴看。。。这里应该对应里面的“4.2 Word Embeddings Dropout”。Dropout主要是CV里面为了防止过拟合的层。据了解,在rnn中,其效果不行,主要是姿势不对吧。上面的(400, 50)为embedding matrix。论文里面说,上一层的参数在语言应用是参数最多的层,又经常没有被正则化。因此对one-hot encoded vectors进行dropout。“This in effect is identical to dropping words at random throughout the input sentence, and can also be interpreted as encouraging the model to not “depend” on single words for its output”。“For T << V it is therefore more efficient to first map the words to the word embeddings, and only then to zero-out word embeddings based on their word type”。所以,第一层和第二层一般一起用。
第三层是Conv层,特征提取层。398=(400-3)/1+1,3为滤波器大小,步长为1。37750参数为3*50*250+250得到的。
第四层是全局池化层,也就是每一个长度为398的向量取最大值。
第五层是全连接层,参数为250*250+250=62750。
第六层是Dropout层,对全连接层进行过拟合防止。
第七层为relu激活。第八层为全连接层,参数为250+1=251。第九层为sigmoid激活或者映射到概率。















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









