







urllib中的urlretrieve部分的代码:
urllib.urlretrieve(eachpic,'tring/pic/'+'1'+str(i)+str(u)+'.jpg')一直提示错误:
IOError:[Errno 2] No such file or directory:’tring/pic/100.jpg’
解决方案:
修改了文件存储目录写法,将
urllib.urlretrieve(eachpic,'tring/pic/'+'1'+str(i)+str(u)+'.jpg')改成
urllib.urlretrieve(eachpic,'pic/'+'1'+str(i)+str(u)+'.jpg’)就OK了。可能跟文件目录的结构有关系,文件目录结构如下:
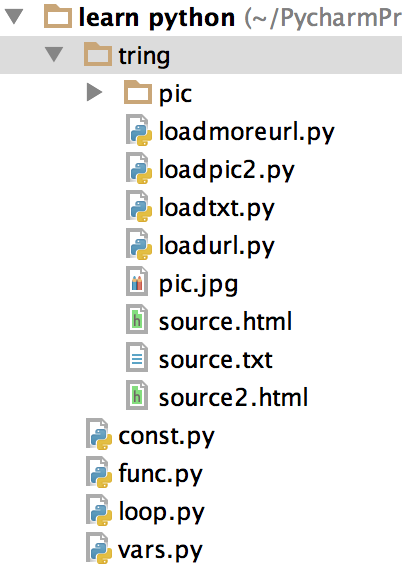
全部源代码:
#encoding:utf-8
import re
import urllib
t = 'http://www.baidu.com'
f = urllib.urlopen(t)
html = f.read()
html_url = re.findall('<li><a href="(.*?)" title=',html,re.S)
# title_c = re.findall('title="(.*?)" target=',html.re.S)
i = 0
for each in html_url:
p_url = 'http://www.baidu.com' + each
print p_url
pic_f = urllib.urlopen(p_url)
pic_html = pic_f.read()
pic_url = re.findall("<img src='(.*?)' >",pic_html,re.S)
u = 0
for eachpic in pic_url:
print eachpic
urllib.urlretrieve(eachpic,'pic/'+'1'+str(i)+str(u)+'.jpg')
u +=1
i +=1














 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









