






(1)python中函数定义方法:
def test(x): "The function definitions" x+=1 return x
def:定义函数的关键字;test:函数名;():内可定义形参;"":文档描述(非必要,建议函数添加描述信息)
x+=1:泛指代码块或程序处理逻辑;return:定义返回值
调用运行时,可以带参数也可以不带。不带参数即为:函数名()
(2)过程定义:过程就是简单特殊没有返回值的函数
def test01(): msg = '王强' print(msg)
对比
def test01(): msg = '王强' print(msg) def test02(): msg = 'wangqiang' print(msg) return msg def test03(): msg = 'WQ' print(msg) return 1,2,3,4,'a',['alex'],{'name':'alex'},None def test04(): msg = 'test04' print(msg) return {'name':'alex'} t1=test01() t2=test02() t3=test03() t4=test04() print(t1) print(t2) print(t3) print(t4)
输出结果为:
王强
wangqiang
WQ
test04
None
wangqiang
(1, 2, 3, 4, 'a', ['alex'], {'name': 'alex'}, None)
{'name': 'alex'}
返回值数=0:返回None;返回值数=1:返回object;返回值数>1:返回tuple
(3)函数参数
a.形参和实参
def calc(x,y): res=x**y return res res=calc(2,3) print(res)
其中,x,y是形参;2,3是实参。实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参
b.位置参数和关键字参数
def test(x,y,z): print(x) print(y) print(z) test(1,2,3)
test(x=1,y=2,z=3)
test(1,2,3)位置参数,必须一一对应,不能多也不能少;test(x=1,y=2,z=3)关键字参数,无须一一对应,不能多也不能少
当位置参数与关键字参数混合使用时,位置参数必须在关键字参数左边,否则报错,同时要求不能多也不能少
test(1,y=2,3)#报错 test(1,3,y=2)#报错 test(1,3,z=2,y=4)#报错,一个参数不能传两遍值 test(z=2,1,3)#报错 test(1,3,z=2)#正确
c.默认参数
def handle(x,type='mysql'): print(x) print(type) handle('hello') handle('hello',type='sqlite') handle('hello','wq')
type='myspl'默认参数;handle('hello','sqlite')位置参数和关键字参数;handle('hello','wq')位置参数
d.参数组:**字典 *列表
def test(x,*args):print(args) test(1,{'name':'wangqiang'},['wq',1,5,8])
输出结果为:({'name': 'wangqiang'}, ['wq', 1, 5, 8])。(多余的值全部以列表的形式进行传入)==>*args:传入列表或者元祖
def test(x,*args,**kwargs):
print(*args)
print(kwargs)
test(1,2,5,7,9,y=2,z=3)
输出结果为:
2 5 7 9
{'y': 2, 'z': 3} ==> **kwargs:传入字典
(3)局部变量和全局变量
name='王强' def change_name(): name='wangqiang' print('change_name',name) change_name() print(name)
其中,name='王强'为全局变量,在py文件中顶头写的变量,在任何位置可以随时调用
name='wangqiang'为局部变量,py文件中子程序中定义的变量,会缩进
输出结果为:
change_name wangqiang
王强
局部变量只在函数里面生效,不会改变全局变量。若改变全局变量,需要在函数中加入global name,即子程序中对变量的修改是对全局变量的修改
name='王强' def ifind(): global name name='quyao' print('ifind', name) def ufind(): print('ufind', name) ufind()
ifind()
输出结果为:
ufind 王强
ifind quyao
name='王强' def ifind(): global name #声明name就是全局变量那个name name='quyao' #对全局变量重新赋值 print('ifind', name) def ufind(): print('ufind', name)#无局部变量,读取已经重新赋值多的全局变量 ifind() ufind()
输出结果为:
ifind quyao
ufind quyao
如果函数中无global关键字,优先读取局部变量,无局部变量时能读取全局变量,但无法对全局变量重新赋值,但是对于可变类型,可以对内部元素进行操作(如对列表进行添加)
如果函数中有global关键字,变量本质上就是全局的那个变量,可读取可重新赋值全局变量
**********规则:全局变量变量名大写;局部变量变量名小写**********
函数与函数之间可以进行嵌套:解释器从上到下执行遇到函数默认不执行,只进行编译,只有在调用函数的时候才会去执行该函数
NAME='王强' #第一步 def abc(): name = 'wangqiang' #第三步 print(name) #第四步 def bcd(): name = 'wang' #第六步 print(name) #第七步 def cde(): name = 'qiang' #第十步 print(name) #第十一步 print(name) #第八步 cde() #第九步 bcd() #第五步 print(name) #第十二步 abc() #第二步
输出结果为:
wangqiang
wang
wang
qiang
wangqiang
NAME = "王强" def abc(): name = "wang" def bcd(): global NAME name = "qiang" bcd() print(name) print(NAME) abc() print(NAME)
输出结果为:
王强
wang
王强

NAME = "王强" def abc(): name = "wang" def bcd(): nonlocal name #nonlocal指定上一级变量,如果没有就继续往上直到找到为止 name = "qiang" bcd() print(name) print(NAME) abc() print(NAME)
输出结果为:
王强
qiang
王强
(4)递归
在函数内部,可以调用其他函数,递归是指在调用一个函数的过程中直接或间接调用自身本身这个函数
def calc(n): print(n) if int(n/2) == 0: return n res=calc(int(n / 2)) #又去调用自身这个函数了 return res calc(10)
输出结果为:
10
5
2
1
递归函数内部执行过程为:

(5)作用域
def test1(): print('in the test1') def test(): print('in the test') return test1 res=test() print(res())
运行结果为:
in the test
in the test1
None
结果none是因为test1函数没有返回值。若最后是print(res),就不会调用test1函数,输出结果则为:
in the test
<function test1 at 0x0000017B317CE048>(test1函数的内存地址)
name='王强' def foo(): name='wang' def bar(): name='qiang' print(name) def tt(): print(name) return tt return bar foo()()()
运行结果为:
qiang
qiang
foo()==>运行foo(),返回bar函数的内存地址;foo()()==>运行bar(),打印name并返回tt函数的内存地址;foo()()()==>运行tt(),打印name且无返回值
(6)匿名函数
匿名函数就是不需要显式的指定函数,关键字为lambda
name='wang' func=lambda x:x+'_qiang' res=func(name) print('匿名函数的运行结果',res)
输出结果为:
匿名函数的运行结果 wang_qiang。和下列命令输出结果相同:
name='wang' def change_name(x): return name+'_qiang' res=change_name(name) print(res)
(7)函数式编程
a.高阶函数
满足下列条件之一的函数,叫做高阶函数:函数接收的参数是一个函数名;返回值中包含函数
第一种,函数接收的参数是一个函数名
def foo(n): print(n) def bar(name): print('my name is %s' %name) foo(bar) foo(bar('王强'))
运行结果为:
<function bar at 0x00000157B9D8D1E0> (bar函数的内存地址)
my name is 王强
None (运行bar函数时没有return返回值)
第二种,返回值中包含函数
def bar(): print('from bar') def foo(): print('from foo') return bar foo()() def hanle(): print('from handle') return hanle handle()()
运行结果为:
from foo
from bar
from handle
from handle
其中,foo()和handle()都是高阶函数
b.map函数
arrary=[1,2,10,5,3,7] def add_one(x): return x + 1 def reduce_one(x): return x-1 def pf(x): return x**2 def map_test(func,arrary): ret=[] for i in array: res=func(i) ret.append(res) return ret print(map_test(add_one,arrary)) print(map_test(reduce_one,arrary)) print(map_test(pf,arrary))
运行结果为:
[2, 3, 11, 6, 4, 8]
[0, 1, 9, 4, 2, 6]
[1, 4, 100, 25, 9, 49]
若引入隐函数,则为
arrary=[1,2,10,5,3,7] def map_test(func,arrary): ret=[] for i in array: res=func(i) ret.append(res) return ret print(map_test(lambda x:x+1,arrary)) print(map_test(lambda x:x-1,arrary)) print(map_test(lambda x:x**2,arrary))
map(处理方法,可迭代对象),map函数实际上是将可迭代对象进行一个内部for循环,将给一个for循环的值交给前面的处理方法进行处理并输出结果
(处理序列中的每个元素,得到的结果是一个‘列表’,该‘列表’元素个数及位置与原来一样)
arrary=[1,2,10,5,3,7] print('内置函数map,处理结果',list(map(lambda x:x-1,arrary)))
map的处理方法不一定是匿名函数
arrary=[1,2,10,5,3,7] def reduce_one(x): return x-1 print('传的是有名函数',list(map(reduce_one,arrary)))
c.filter函数
filter(处理方法,可迭代对象),filter函数实际上是将可迭代对象进行一个内部for循环,将每一个for循环的值交给前面的处理方法进行处理,保留布尔值为true的结果
(遍历序列中的每个元素,判断每个元素得到布尔值,如果是True则留下来,得到新的'列表')
movie_people=['wang_qiang','wang_wang','王强','wang_yao'] print(list(filter(lambda n:not n.startswith('wang'),movie_people)))
运行结果为:['王强']
相当于内部for循环的程序
def filter_test(array): ret=[] for n in array: if not n.startswith('wang'): ret.append(n) return ret res=filter_test(movie_people) print(res)
d.reduce函数
reduce(处理方法,可迭代对象,初始值)
(处理一个序列,然后把序列进行合并操作)
num_1=[1,2,3,100]
from functools import reduce #python里需要内部调用reduce函数 print(reduce(lambda x,y:x+y,num_l))
相当于内部for循环的程序
num_l=[1,2,3,100] def reduce_test(array): res=0 for num in array: res+=num return res print(reduce_test(num_l))
(8)内置函数
abs():绝对值运算
print(abs(-1)) ==>1
all():将序列中的每个元素拿出来进行布尔值运算,判断最终是true还是false,当每个元素的布尔值全是真的时候才会返回true;如果可迭代对象为空,也是true
print(all([1,2,'1'])) ==>true
print(all([1,2,'1',''])) ==>false
print(all('')) ==>true
any():将序列中的每个元素拿出来进行布尔值运算,判断最终是true还是false,只要有一个为真,返回值就会是true
print(any([0,''])) ==>false
print(any([0,'',1])) ==>true
bool():布尔值运算。空,None,0的布尔值为False,其余都为True
print(bool(''))
print(bool(None))
print(bool(0))
bytes():字符串按编码规则转化为字节;decode解码;ascii不能编码中文
name='你好'
print(bytes(name,encoding='utf-8'))
print(bytes(name,encoding='utf-8').decode('utf-8'))
print(bytes(name,encoding='ascii')) #报错,ascii不能编码中文
chr():按ascii码表的顺序进行转换,显示ascii码表中对应的字符
print(chr(46))
ord():显示字符在ascii码表中对应的数字,与chr()功能相反
dir():显示某一对象里面都有哪些内置方法或属性
print(dir(dict))
divmod():分页功能,总共有n条记录,每一页放m条
print(divmod(10,3))
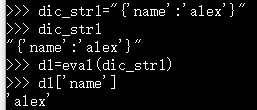
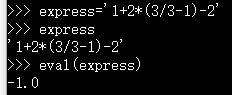
eval():把字符串中的数据结构提取出来;把字符串中的数学运算做一遍
hash():可hash的数据类型即不可变数据类型,包括字符串、元组;不可hash的数据类型即可变数据类型,包括列表、字典、集合
print(hash([1,2,'wang'])) ==>报错,列表是可变数据类型
print(hash('12sdf'))
help():内置方法及其用法解释,相比于dir()只是显示方法名称
print(help(all))
进制转换
print(bin(10))#10进制->2进制
print(hex(12))#10进制->16进制
print(oct(12))#10进制->8进制
m.isinstiance():判断输入的内容是不是某一特定的数据类型,输出结果为布尔值
print(isinstance(1,int))
print(isinstance('abc',str))
print(isinstance([],list))
print(isinstance({},dict))
print(isinstance({1,2},set))
globals()和locals():globals():显示全局变量(会包括一些内置变量);locals(): 显示局部变量。结果以字典的形式呈现
name='王强' def test(): age='18' print(globals()) print(locals()) test()
运行结果为:
{'__builtins__': <module 'builtins' (built-in)>, 'test': <function test at 0x00000206CE17F048>, 'name': '王强', '__cached__': None, '__file__': 'F:/Pathon/python全栈day11-20/python全栈s3 day16/python全栈s3 day16课上所有/python全栈s3 day16课上所有/内置函数.py', '__name__': '__main__', '__doc__': None, '__spec__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000206CE118940>}
{'age': '18'}
zip():将序列进行一一匹配,若不能对应则舍去
p={'name':'qiang','age':18,'gender':'men'}
print(list(zip(p.keys(),p.values())))
运行结果为:[('name', 'qiang'), ('gender', 'men'), ('age', 18)]
max(),min():求最大最小
max,min函数处理的是可迭代对象,相当于一个for循环取出来每一个元素进行比较,注意不同数据类型之间不可以比较,字典不可以比较;
元素和元素之间的比较,从第一个位置开始比较(字典无序故无法比),若这一位置比较出大小,后面的都不需要比较了,直接比出俩元素的大小
age_dic={'wang_age':18,'qiang_age':20,'qu_age':100,'yao_age':30}
print(max(zip(age_dic.values(),age_dic.keys())))
# print(max(age_dic)) #比较的是key
# print(max(age_dic.values())) #比较的是value,但是不知道是哪个key对应的
# print(max(zip(age_dic.values(),age_dic.keys()))) #结合zip使用
运行结果为:(100, 'qu_age')
pow():pow(x,y)表示x的y次幂;pow(x,y,z)表示x的y次幂得到的结果对z进行取余
reversed():反转
l=[1,2,3,4] print(list(reversed(l))) print(l)
运行结果为:[4,3,2,1]
round():四舍五入
slice():切片,可以设定切片的步长
l='hello' s1=slice(3,5) s2=slice(1,4,2) print(l[3:5]) print(l[s1]) print(l[s2])
运行结果为:
lo;lo;el
sorted():排序。本质就是在比较大小,不同类型之间不可以比较大小
people=[ {'name':'wangqiang','age':1000}, {'name':'wang','age':10000}, {'name':'qiang','age':9000}, {'name':'quyao','age':18}, ] print(sorted(people,key=lambda dic:dic['age']))
运行结果为:
[{'age': 18, 'name': 'wangqiang'}, {'age': 1000, 'name': 'wang'}, {'age': 9000, 'name': 'qiang'}, {'age': 10000, 'name': 'quyao'}]
type():判断数据类型
vars():没有参数,相当于locals(),显示局部变量,以列表的形式呈现;有参数,显示某一对象下面所有的方法,以字典的形式呈现















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









