






Pandas是一个非常好用的数据处理包,那么处理同样的数据,不同的方法其效率能差多少呢?
首先看一下数据的形式,很小的一组数据,不到34万行,10列。
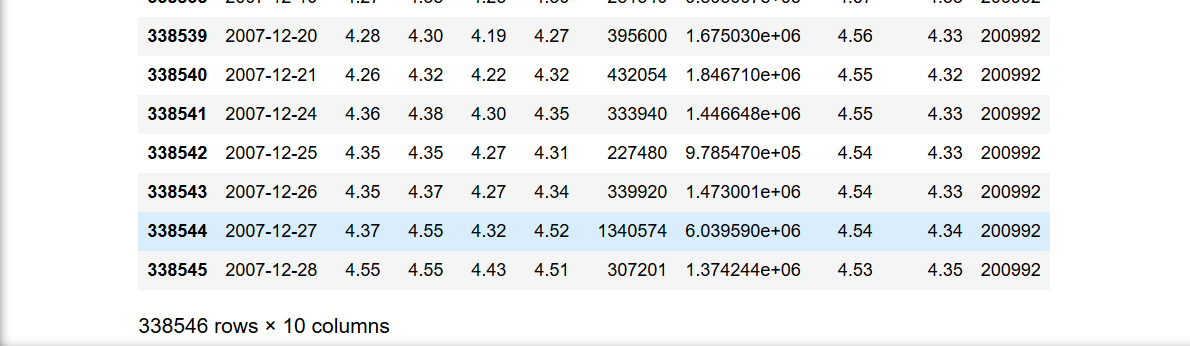
数据的处理方法也很简单,就是一个简单的条件语句if,用其中的一列,对比另外一列的大小,条件满足,在状态列表里加个1,条件不满足就加个0。
测试1:
利用最原始的方法,利用一个for循环,遍历整个 Dataframe:
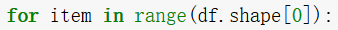
在每一次循环中,粗暴的在每一个if语句中使用一次df.loc定位函数的方式在整个Dataframe中提取需要的数据,基本上长这样:

程序一共12次条件判断,最后得到的结果简直令人发指(我差点等不及手动停止)-_-!

27分钟,简直。。。
测试2:
在痛苦等待之后,将程序改成先赋值,再调用的方式,既在每一次循环时,先统一对变量进行赋值:

然后在每一次条件语句中使用赋值后的变量进行条件判断:

同样是12次条件判断,可是结果却大大缩短,起码缩短到人类可以接受的程度-_-!

7分半钟,有没有感觉坐上了11路公交的感觉^_^
测试3:
前两种测试方法的思路是,每一次循环,找到Dataframe中相应的行,再从行中提取所需的数据进行比较。
第3次的测试方法有升级,首先在for循环之前,按照不同的数据列,提取出每一列的Series,再按照固定的顺序(因为是遍历),从每个Series中固定位置提取数据进行条件判断。
这种方法的好处是摒弃了对loc函数的调用。

同样是12次条件判断,这次的结果还是比较满意的^_^

计算时间缩短到1分半左右,这次有点开车兜风的感觉啦!但是能不能再快点呢??
测试4:
再往深走一步,我们知道,Pandas底层封装的是Numpy,通过Dataframe.values或Series.values就可以得到Pandas最底层的数据结构,它基本上长这样:

那么我们可不可以通过层层扒皮,在pandas最底层的结构上直接进行运算呢?答案当然是可以的。
通过对测试3的改进,我们在for循环之前将获得的Series通过Series.values的形式转换成Numpy的ndarray数组,再按照固定的顺序,从每个ndarray中固定位置提取数据进行条件判断:

同样的12次条件判断,同样的方法,仅仅将Series转化成ndarray,结果却出乎意料的不可思议(⊙o⊙)

34万行数据,12次条件判断,运行时间只需要3秒,是不是有坐火箭的感脚~_~
总结一下:
通过3次改进,将最原始的暴力数据提取法改进成为最终对ndarray数组的处理,将运算速度由接近30分钟缩短为3秒。
所以要想成数量级的提升Pandas的效率,应该直接从底层解决对ndarray的处理算法,在数据量大的时候,应尽量避免对df.loc/df.iloc类定位函数的调用。















 9242
9242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









