






线性回归可以说是机器学习中最基本的问题类型了,这里就对线性回归的原理和算法做一个小结。
1. 线性回归的模型函数和损失函数由来
线性回归遇到的问题一般是这样的。我们有m个样本,每个样本对应于n维特征和一个结果输出,如下:
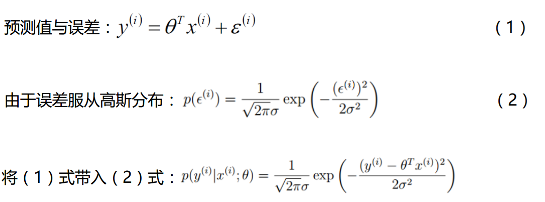


由上面推到,可知线性回归可以使用最小二乘法进行求解:
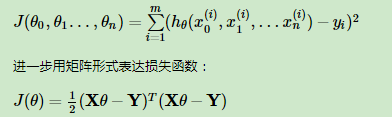
由于矩阵法表达比较的简洁,后面我们将统一采用矩阵方式表达模型函数和损失函数。
2. 线性回归的算法
可见另一篇文章: 最小二乘法(least squares)介绍
当然线性回归,还有其他的常用算法,比如牛顿法和拟牛顿法,这里不详细描述。
3. 线性回归的推广:多项式回归

4. 线性回归的推广:广义线性回归

5. 线性回归的正则化
为了防止模型的过拟合,我们在建立线性模型的时候经常需要加入正则化项。一般有L1正则化和L2正则化。
线性回归的L1正则化通常称为Lasso回归,它和一般线性回归的区别是在损失函数上增加了一个L1正则化的项,L1正则化的项有一个常数系数αα来调节损失函数的均方差项和正则化项的权重,具体Lasso回归的损失函数表达式如下:

Lasso回归可以使得一些特征的系数变小,甚至还是一些绝对值较小的系数直接变为0。增强模型的泛化能力。
Lasso回归的求解办法一般有坐标轴下降法(coordinate descent)和最小角回归法( Least Angle Regression)
线性回归的L2正则化通常称为Ridge回归,它和一般线性回归的区别是在损失函数上增加了一个L2正则化的项,和Lasso回归的区别是Ridge回归的正则化项是L2范数,而Lasso回归的正则化项是L1范数。具体Ridge回归的损失函数表达式如下:
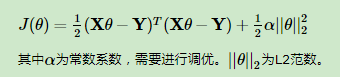
Ridge回归在不抛弃任何一个特征的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但和Lasso回归比,这会使得模型的特征留的特别多,模型解释性差。
Ridge回归的求解比较简单,一般用最小二乘法。这里给出用最小二乘法的矩阵推导形式,和普通线性回归类似。

除了上面这两种常见的线性回归正则化,还有一些其他的线性回归正则化算法,区别主要就在于正则化项的不同,和损失函数的优化方式不同,这里就不累述了。
来自 <https://www.cnblogs.com/pinard/p/6004041.html>
简单的测试代码:
建模的流程大三步:数据清理处理,模型选择,检验,下面以线性回归为例:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,linear_model
diabetes=datasets.load_diabetes() #加载数据
diabetes_X=diabetes.data[:,np.newaxis,2] #嵌套列表转化成列表
diabetes_X_train=diabetes_X[:-20] #剔除后面20个作为训练集
diabetes_X_test=diabetes_X[-20:] #剔除前面20个作为测试集合
diabetes_y_train=diabetes.target[:-20]
diabetes_y_test=diabetes.target[-20:]
regr=linear_model.LinearRegression() #创建线性回归对象
regr.fit(diabetes_X_train,diabetes_y_train) #将训练集放进去拟合
print("Coefficients:\n",regr.coef_) #输出系数
print("Residual sum of sqares:%.2f"
%np.mean((regr.predict(diabetes_X_test)-diabetes_y_test)**2)) #输出残差平方和
print("Variance score:%.2f" %regr.score(diabetes_X_test,diabetes_y_test)) #R^2
plt.scatter(diabetes_X_test,diabetes_y_test,color='black') #测试集散点图
plt.plot(diabetes_X_test,regr.predict(diabetes_X_test),color='blue',linewidth=3) #拟合方程
plt.title("The Linear Model")
plt.show()















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









