






转自:http://blog.csdn.net/haoyifen/article/details/54692503
kafka与其他消息队列不同的是, kafka的消费者状态由外部( 消费者本身或者类似于Zookeeper之类的外部存储 )进行维护, 所以kafka的消费就更加灵活, 但是也带来了很多的问题, 因为客户端消费超时被判定挂掉而消费者重新分配分区, 导致重复消费, 或者客户端挂掉而导致重复消费等问题.
本文内容简介
kafka的消费者有很多种不同的用法及模型. * 本文着重探讨0.9版本及之后的kafka新consumer API的手动提交和多线程的使用* . 对于外部存储offset, 手动偏移设置, 以及手动分区分配等不同消费者方案, 将在其他文章中介绍.
消费者在单线程下的使用
下面介绍单线程情况下自动提交和手动提交的两种消费者
1. 自动提交, 单线程poll, 然后消费
Properties props = new Properties();
props.put("bootstrap.servers", servers);
props.put("group.id", "autoCommitGroup");
//自动提交 props.put("enable.auto.commit", "true"); //自动提交时间间隔 props.put("auto.commit.interval.ms", "1000"); //key和value的序列化类 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); }
offset自动提交会让人产生误会, 其实并不是在后台提交, 而是在poll时才会进行offset提交.
2. 手动提交, 单线程poll, 读取一定量的数据后才提交offset
Properties props = new Properties();
props.put("bootstrap.servers", servers);
props.put("group.id", "manualOffsetControlTest");
//手动提交 props.put("enable.auto.commit", "false"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); //每次处理200条消息后才提交 final int minBatchSize = 200; //用于保存消息的list ArrayList<ConsumerRecord<String, String>> buffer = new ArrayList<>(); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { buffer.add(record); } //如果读取到的消息满了200条, 就进行处理 if (buffer.size() >= minBatchSize) { doSomething(buffer); //处理完之后进行提交 consumer.commitAsync(); //清除list, 继续接收 buffer.clear(); } }
新kafka消费者的版本特性
在接下来的探讨之前, 需要简单介绍一下kafka消费者的特性.
- kafka的0.9版本中重写了consumer API
- consumer维护了消费者当前消费状态, 不是线程安全的
- 新的consumer基于单线程模型, offset自动提交在poll方法中进行, 0.9–0.10.0.1, 客户端的心跳也是在poll中进行, 在0.10.1.0版本中, 客户端心跳在后台异步发送了
- 0.9版本不能设置每回poll返回的最大数据量, 所以poll一次会返回上一次消费位置到最新位置的数据, 或者最大的数据量. 在0.10.0.1版本及之后, 可以通过在consumer的props中设置max.poll.records来限制每回返回的最大数据条数.
我的设计
我所使用的kafka版本是0.10.0.1, 所以使用的是新版本的consumer API, 可以限制每回返回的最大数据条数, 但是心跳和自动提交都是在poll中进行的.
为了防止前面单线程中, 因为消息处理时间过长, poll的时间间隔很长, 导致不能及时在poll发送心跳, 且offset也不能提交, 客户端被超时被判断为挂掉, 未提交offset的消息会被其他消费者重新消费.
我的设计:
- 首先使用max.poll.records来限制每次poll返回的最大消息量
- 将消息的poll和消息的处理分隔开, 尽快的poll, 以发送心跳
- 每个处理线程只负责一个分区的处理, 当处理到一定的数量或者距离上一次处理一定的时间间隔后, 由poll线程进行提交offset.
代码架构如下图所示:
假设有两个消费者线程MsgReceiver, 分别分到了分区1和分区2, 分区3和分区4
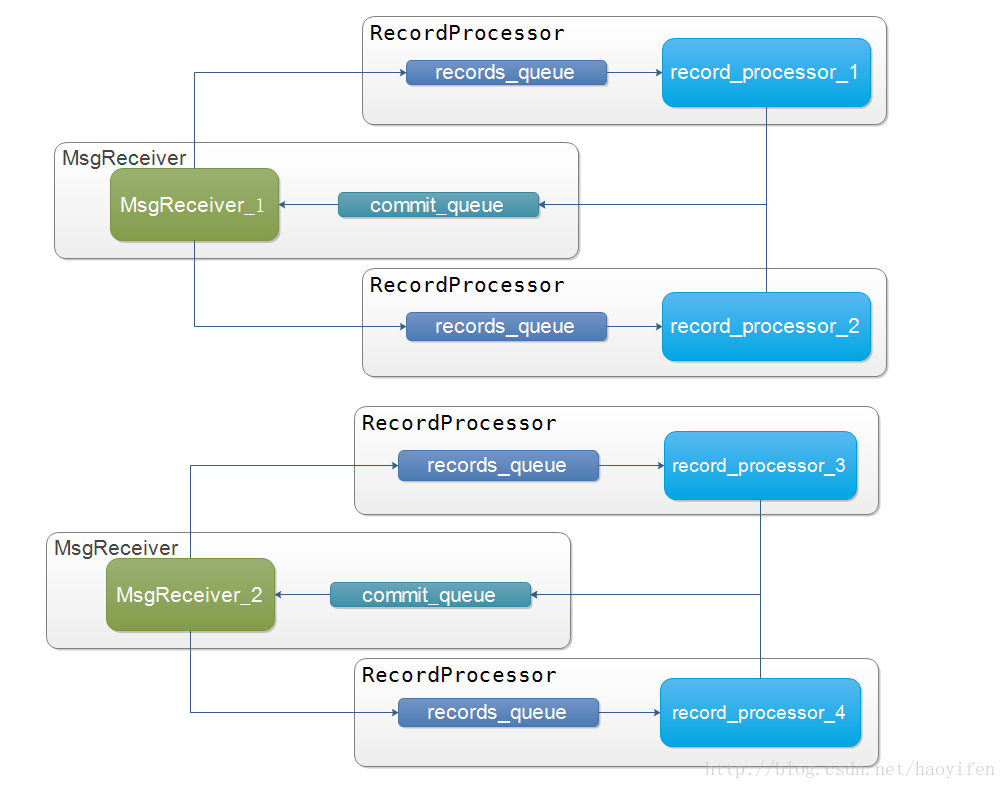
- 有多个消费者线程, 在while循环中poll消息
- 消费者根据分区将消息交给对应的record_processor线程进行处理, 即一个record_processor线程只处理一个分区的消息
- record_processor处理线程处理了一定条数的消息或者距离上一次处理消息过去一定时间后, 将当前分区的偏移量放至到consumer_queue中
- 消费者record_processor在poll前先读取commit_queue中的内容, 如果有的话, 则提交当中的偏移信息到kafka. 然后继续poll消息
代码实现
1. 消费者任务 MsgReceiver
public class MsgReceiver implements Runnable { private static final Logger logger = LoggerFactory.getLogger(MsgReceiver.class); private BlockingQueue<Map<TopicPartition, OffsetAndMetadata>> commitQueue = new LinkedBlockingQueue<>(); private Map<String, Object> consumerConfig; private String alarmTopic; private ConcurrentHashMap<TopicPartition, RecordProcessor> recordProcessorTasks; private ConcurrentHashMap<TopicPartition, Thread> recordProcessorThreads; public MsgReceiver(Map<String, Object> consumerConfig, String alarmTopic, ConcurrentHashMap<TopicPartition, RecordProcessor> recordProcessorTasks, ConcurrentHashMap<TopicPartition, Thread> recordProcessorThreads) { this.consumerConfig = consumerConfig; this.alarmTopic = alarmTopic; this.recordProcessorTasks = recordProcessorTasks; this.recordProcessorThreads = recordProcessorThreads; } @Override public void run() { //kafka Consumer是非线程安全的,所以需要每个线程建立一个consumer KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfig); consumer.subscribe(Arrays.asList(alarmTopic)); //检查线程中断标志是否设置, 如果设置则表示外界想要停止该任务,终止该任务 try { while (!Thread.currentThread().isInterrupted()) { try { //查看该消费者是否有需要提交的偏移信息, 使用非阻塞读取 Map<TopicPartition, OffsetAndMetadata> toCommit = commitQueue.poll(); if (toCommit != null) { logger.debug("commit TopicPartition offset to kafka: " + toCommit); consumer.commitSync(toCommit); } //最多轮询100ms ConsumerRecords<String, String> records = consumer.poll(100); if (records.count() > 0) { logger.debug("poll records size: " + records.count()); } for (final ConsumerRecord<String, String> record : records) { String topic = record.topic(); int partition = record.partition(); TopicPartition topicPartition = new TopicPartition(topic, partition); RecordProcessor processTask = recordProcessorTasks.get(topicPartition); //如果当前分区还没有开始消费, 则就没有消费任务在map中 if (processTask == null) { //生成新的处理任务和线程, 然后将其放入对应的map中进行保存 processTask = new RecordProcessor(commitQueue); recordProcessorTasks.put(topicPartition, processTask); Thread thread = new Thread(processTask); thread.setName("Thread-for " + topicPartition.toString()); logger.info("start Thread: " + thread.getName()); thread.start(); recordProcessorThreads.put(topicPartition, thread); } //将消息放到 processTask.addRecordToQueue(record); } } catch (Exception e) { e.printStackTrace(); logger.warn("MsgReceiver exception " + e + " ignore it"); } } } finally { consumer.close(); } } }
2. 消息处理任务 RecordProcessor
public class RecordProcessor implements Runnable { private static Logger logger = LoggerFactory.getLogger(RecordProcessor.class); //保存MsgReceiver线程发送过来的消息 private BlockingQueue<ConsumerRecord<String, String>> queue = new LinkedBlockingQueue<>(); //用于向consumer线程提交消费偏移的队列 private BlockingQueue<Map<TopicPartition, OffsetAndMetadata>> commitQueue; //上一次提交时间 private LocalDateTime lastTime = LocalDateTime.now(); //消费了20条数据, 就进行一次提交 private long commitLength = 20L; //距离上一次提交多久, 就提交一次 private Duration commitTime = Duration.standardSeconds(2); //当前该线程消费的数据条数 private int completeTask = 0; //保存上一条消费的数据 private ConsumerRecord<String, String> lastUncommittedRecord; //用于保存消费偏移量的queue, 由MsgReceiver提供 public RecordProcessor(BlockingQueue<Map<TopicPartition, OffsetAndMetadata>> commitQueue) { this.commitQueue = commitQueue; } @Override public void run() { try { while (!Thread.currentThread().isInterrupted()) { //有时间限制的poll, consumer发送消费过来的队列. 每个处理线程都有自己的队列. ConsumerRecord<String, String> record = queue.poll(100, TimeUnit.MICROSECONDS); if (record != null) { //处理过程 process(record); //完成任务数加1 this.completeTask++; //保存上一条处理记录 lastUncommittedRecord = record; } //提交偏移给consumer commitToQueue(); } } catch (InterruptedException e) { //线程被interrupt,直接退出 logger.info(Thread.currentThread() + "is interrupted"); } } private void process(ConsumerRecord<String, String> record) { System.out.println(record); } //将当前的消费偏移量放到queue中, 由MsgReceiver进行提交 private void commitToQueue() throws InterruptedException { //如果没有消费或者最后一条消费数据已经提交偏移信息, 则不提交偏移信息 if (lastUncommittedRecord == null) { return; } //如果消费了设定的条数, 比如又消费了commitLength消息 boolean arrivedCommitLength = this.completeTask % commitLength == 0; //获取当前时间, 看是否已经到了需要提交的时间 LocalDateTime currentTime = LocalDateTime.now(); boolean arrivedTime = currentTime.isAfter(lastTime.plus(commitTime)); //如果消费了设定条数, 或者到了设定时间, 那么就发送偏移到消费者, 由消费者非阻塞poll这个偏移信息队列, 进行提交 if (arrivedCommitLength || arrivedTime) { lastTime = currentTime; long offset = lastUncommittedRecord.offset(); int partition = lastUncommittedRecord.partition(); String topic = lastUncommittedRecord.topic(); TopicPartition topicPartition = new TopicPartition(topic, partition); logger.debug("partition: " + topicPartition + " submit offset: " + (offset + 1L) + " to consumer task"); Map<TopicPartition, OffsetAndMetadata> map = Collections.singletonMap(topicPartition, new OffsetAndMetadata(offset + 1L)); commitQueue.put(map); //置空 lastUncommittedRecord = null; } } //consumer线程向处理线程的队列中添加record public void addRecordToQueue(ConsumerRecord<String, String> record) { try { queue.put(record); } catch (InterruptedException e) { e.printStackTrace(); } } }
3. 管理对象
负责启动消费者线程MsgReceiver, 保存消费者线程MsgReceiver, 保存处理任务和线程RecordProcessor, 以及销毁这些线程
public class KafkaMultiProcessorTest {
private static final Logger logger = LoggerFactory.getLogger(KafkaMultiProcessor.class); //订阅的topic private String alarmTopic; //brokers地址 private String servers; //消费group private String group; //kafka消费者配置 private Map<String, Object> consumerConfig; private Thread[] threads; //保存处理任务和线程的map private ConcurrentHashMap<TopicPartition, RecordProcessor> recordProcessorTasks = new ConcurrentHashMap<>(); private ConcurrentHashMap<TopicPartition, Thread> recordProcessorThreads = new ConcurrentHashMap<>(); public static void main(String[] args) { KafkaMultiProcessorTest test = new KafkaMultiProcessorTest(); //....省略设置topic和group的代码 test.init(); } public void init() { consumerConfig = getConsumerConfig(); logger.debug("get kafka consumerConfig: " + consumerConfig.toString()); //创建threadsNum个线程用于读取kafka消息, 且位于同一个group中, 这个topic有12个分区, 最多12个consumer进行读取 int threadsNum = 3; logger.debug("create " + threadsNum + " threads to consume kafka warn msg"); threads = new Thread[threadsNum]; for (int i = 0; i < threadsNum; i++) { MsgReceiver msgReceiver = new MsgReceiver(consumerConfig, alarmTopic, recordProcessorTasks, recordProcessorThreads); Thread thread = new Thread(msgReceiver); threads[i] = thread; thread.setName("alarm msg consumer " + i); } //启动这几个线程 for (int i = 0; i < threadsNum; i++) { threads[i].start(); } logger.debug("finish creating" + threadsNum + " threads to consume kafka warn msg"); } //销毁启动的线程 public void destroy() { closeRecordProcessThreads(); closeKafkaConsumer(); } private void closeRecordProcessThreads() { logger.debug("start to interrupt record process threads"); for (Map.Entry<TopicPartition, Thread> entry : recordProcessorThreads.entrySet()) { Thread thread = entry.getValue(); thread.interrupt(); } logger.debug("finish interrupting record process threads"); } private void closeKafkaConsumer() { logger.debug("start to interrupt kafka consumer threads"); //使用interrupt中断线程, 在线程的执行方法中已经设置了响应中断信号 for (int i = 0; i < threads.length; i++) { threads[i].interrupt(); } logger.debug("finish interrupting consumer threads"); } //kafka consumer配置 private Map<String, Object> getConsumerConfig() { return ImmutableMap.<String, Object>builder() .put("bootstrap.servers", servers) .put("group.id", group) .put("enable.auto.commit", "false") .put("session.timeout.ms", "30000") .put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") .put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") .put("max.poll.records", 1000) .build(); } public void setAlarmTopic(String alarmTopic) { this.alarmTopic = alarmTopic; } public void setServers(String servers) { this.servers = servers; } public void setGroup(String group) { this.group = group; } }
不足
上面的代码还有不足, 可以看到处理任务和线程是保存在map中, 如果consumer因为有新机器的上线而重新分配分区, 而被剥夺了某个分区的消费, 对应的处理任务和线程并没有进行响应的销毁. 所以我们使用org.apache.kafka.clients.consumer.ConsumerRebalanceListener来对分区的调整进行响应.















 7727
7727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









