






Scrapy安装及demo测试笔记
2016年09月01日 16:34:00 panguoyuan 阅读数:1903
Scrapy安装及demo测试笔记
一、环境搭建
- 安装scrapy:pip install scrapy
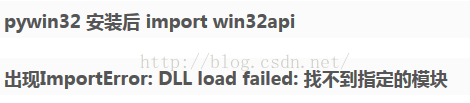
2.安装:PyWin32,可以从网上载已编译好的安装包:http://www.lfd.uci.edu/%7Egohlke/pythonlibs/#pywin32
安装完之后会报如下错误
解决办法,把以下两个文件拷贝到C:\Windows\System32目录下
二、创建scrapy工程(在此用网上别人提供的例子)
1.cmd的方式进到某个指定目录(d:/tmp/)下执行:scrapy startproject myscrapy,命令执行完之后,生成的目录结构如下
2.设置items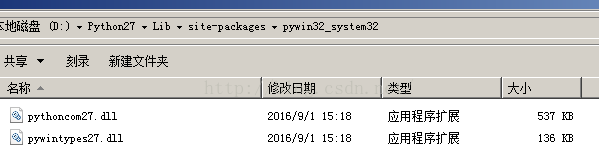
# -- coding: utf-8 --
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class MyscrapyItem(scrapy.Item):
news_title = scrapy.Field() #南邮新闻标题
news_date = scrapy.Field() #南邮新闻时间
news_url = scrapy.Field() #南邮新闻的详细链接
3.编写 spider
# -- coding: utf-8 --
mport scrapy
from myscrapy.items import MyscrapyItem
import logging
class myscrapySpider(scrapy.Spider):
name = "myscrapy"
allowed_domains = ["njupt.edu.cn"]
start_urls = [
"http://news.njupt.edu.cn/s/222/t/1100/p/1/c/6866/i/1/list.htm",
]
def parse(self, response):
news_page_num = 14
page_num = 386
if response.status == 200:
for i in range(2,page_num+1):
for j in range(1,news_page_num+1):
item = MyscrapyItem()
item['news_url'],item['news_title'],item['news_date'] = response.xpath(
"//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/font/text()"
"|//div[@id='newslist']/table[1]/tr["+str(j)+"]//td[@class='postTime']/text()"
"|//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/@href").extract()
yield item
next_page_url = "http://news.njupt.edu.cn/s/222/t/1100/p/1/c/6866/i/"+str(i)+"/list.htm"
yield scrapy.Request(next_page_url,callback=self.parse_news)
def parse_news(self, response):
news_page_num = 14
if response.status == 200:
for j in range(1,news_page_num+1):
item = MyscrapyItem()
item['news_url'],item['news_title'],item['news_date'] = response.xpath(
"//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/font/text()"
"|//div[@id='newslist']/table[1]/tr["+str(j)+"]//td[@class='postTime']/text()"
"|//div[@id='newslist']/table[1]/tr["+str(j)+"]//a/@href").extract()
yield item4.编写pipelines
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.htmlimport json
class MyscrapyPipeline(object):
def init(self):
self.file = open('myscrapy.txt',mode='wb')
def process_item(self, item, spider):
self.file.write(item['news_title'].encode("GBK"))
self.file.write("\n")
self.file.write(item['news_date'].encode("GBK"))
self.file.write("\n")
self.file.write(item['news_url'].encode("GBK"))
self.file.write("\n")
return item
5.编写settings.py
# -- coding: utf-8 --
# Scrapy settings for myscrapy project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'myscrapy'
SPIDER_MODULES = ['myscrapy.spiders']
NEWSPIDER_MODULE = 'myscrapy.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'myscrapy (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'myscrapy.middlewares.MyCustomSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'myscrapy.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
TEM_PIPELINES = {
'myscrapy.pipelines.MyscrapyPipeline': 1,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
6.进到D:\tmp\myscrapy\myscrapy\spiders启动爬虫并查看结果:scrapy crawl myscrapy














 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









