






全名:TUNA-Net: Task-oriented UNsupervised Adversarial Network for Disease Recognition in Cross-Domain Chest X-rays
Abstract:
作者通过研究领域自适应问题来解决数据集不够的问题。为了解决常规领域自适应方法的问题(忽略了类特有的语义信息),作者提出了一个网络叫做TUNA-Net。它能够通过不同损失函数保留低级,高级语义和中级特征信息。它在很多数据集上取得了很好的效果,甚至和有监督的方法效果接近。
Introduction:
第一段:有监督自适应虽然效果不错,但是在每个新的领域中获取数据是非常麻烦的,需要专业的医生进行处理。所以无监督自适应在医疗图像处理中获得了广泛的应用。
第二段:对抗自适应方法(GAN等)也取得了很多成果。
第三段:以前的方法都是用于处理有限的领域变化或者边沿清晰,位置固定的大器官,然而它们不能保存器官损伤或异常的类特定语义信息。所以它们的方法是不足够的。
第四段:作者提出了一个面向人物的无监督对抗网络(TUNA-net)。作者在成年人和儿童的胸部X光两个域上实现了这个网络。TUNA-net由一个具有类感知语义约束模块的循环翻译框架组成。它能够合成真实的图片,保存类特有的语义信息,学习中级特征。优化目标函数并推广到无监督域。
Method
Problem Formulation
只用源域的图片和标签去预测目标域的图片和标签。直接在源域上训练并应用于目标域效果会下降,作者使用了非匹配的图像翻译来减轻这个现象。同时,作者在翻译的不同阶段添加约束,以保留图像的特征。
总体框架

Pixel-level image-to-image translation with unpaired images
给出两个来自不同域的非匹配图像,作者使用了Cycle-GAN来学习两个映射。
对于两个不同的域A,P,学习两个不同的生成器,其中一个如下

同理,将A,P互换可以得到另一个生成器的公式。
同时,采用 cycle consistency loss 来保证翻译回来的图片和原图可以对应。
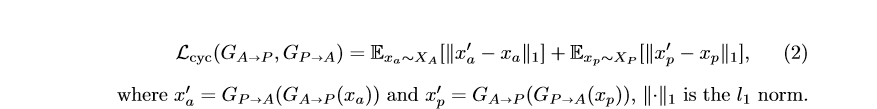
这种方法可以保证生成以假乱真的图片,但是并不能保证高级语义被保留。有疾病(如lung opacities)的肺部图片可能会被翻译成无病的。
2.3 High-level class-specific semantics modelling
在源域上的学习使用的是交叉熵(带权重的)

为了保证在目标域翻译的图像标签与源域相同,采用了下面的损失函数,最后一部分是为了保证两个分类器分类结果相近:
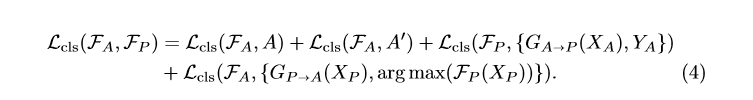
2.4 Mid-level feature regularization
作者提出了一个新的loss,对源模型和目标目标模型中间每一个卷积层的输出做如下操作来保证中层信息不丢失:
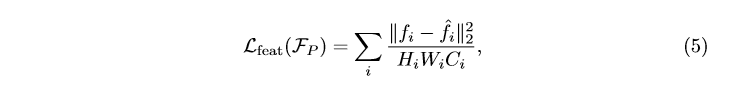
实际上就是欧几里得距离。

2.5 Final objective and implementation details
最终的损失函数

一些实验的细节

Experiments & Conclusion
略














 4296
4296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









