






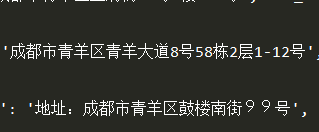
先来看一个截图,爬虫得到的结果,里面99的字体貌似有点奇怪,刚开始以为是不同的字体,在Excel里选中调整字体时发现没有变化,后来经过大佬指点,才知道是全角数字(原谅我小白无知)。为了统一起见,把所有的全角字符转换为半角字符,然后再做处理。既然是在爬虫里面,那可以直接用代码转换了,但是以前存起来的数据用代码转就有点繁琐了,所以在Excel里解决就好。下面介绍两种方法,分别用Python和Excel。
首先介绍一下什么是全角和半角:全角字符unicode编码从65281~65374 (十六进制 0xFF01 ~ 0xFF5E),半角字符unicode编码从33~126 (十六进制 0x21~ 0x7E),空格比较特殊,全角为 12288(0x3000),半角为 32(0x20)。除空格外,全角/半角按unicode编码排序在顺序上是对应的(半角 + 65248 = 全角)。那代码就好写了。
1. Python全角转半角
1 def DBC2SBC(ustring): 2 n = [] 3 # python3现在已经将unichr和chr合并,所以网上的代码已经不合适 4 for char in ustring: 5 num = ord(char) 6 if num == 0x3000: 7 num = 32 8 elif 0xFF01 <= num <= 0xFF5E: 9 num -= 0xfee0 10 num = chr(num) 11 n.append(num) 12 return ''.join(n) 13 14 if __name__ == '__main__': 15 a = '《中文》(213)' 16 print(a) 17 print(DBC2SBC(a))
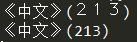
由于所有中文占两个字节,只能由全角表示,所以没有变化,里面的全角数字变为半角数字,但是中文括号也跟着变化了。要是想保留文本中的中文括号那就像空格一样单独处理,中文符号和英文符号的对应关系查不到的话没关系,把所有的对应关系打印出来看就是。
1 for i in range(33,127): 2 print(i,chr(i),i+65248,chr(i+65248))
2. 在Excel里转换全角数字和半角数字
在想要转化的一个单元格后面输入=ASC()就可转化一个单元格,然后点住黑色十字指针往下拉就可以将一列全部转化。图中的D8是想要转化的那一个单元格编号。

最后说一句,win10默认的拼音输入法没有开启全角输入方式,所以先要去输入法设置里改一下。
















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









