









在VMWare中构建第二、三台虚拟机,机器命名为Slave1、Slave2,如下图
在/etc/hostname中修改主机名
vim /etc/hostname修改为Master、Slave1、Slave2,重启后生效
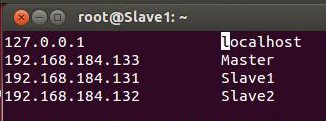
step1:在各主机中修改主机名与ip对应关系
打开/etc/hosts 修改成如下所示

测试连接Master
ping Master在Slave1、Slave2中增加所有ip与主机名
把Master下hosts也修改成上图所示
测试一下三台机器的通信
step2:SSH无密码验证配置
首先看下Master通过SSH访问Slave1的情况
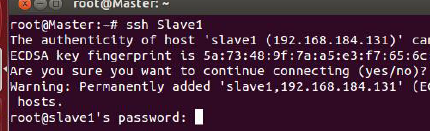
这时候是需要密码的
此时Slave1的id_rsa.pub传给Master,如下所示
cd /home/dida/.ssh
scp id_rsa.pub dida@Master:/home/dida/.ssh/id_rsa.pub.Slave1同时把Slave2的id_rsa.pub传给Master
cd /home/dida/.ssh
scp id_rsa.pub dida@Master:/home/dida/.ssh/id_rsa.pub.Slave2在Master上综合所有公匙
cat id_rsa.pub.Slave1 >> authorized_keys
cat id_rsa.pub.Slave2 >> authorized_keys注意,需要从哪个节点连接另外的节点,是把自己的公共密匙传给别人。
一般只需要把Master的公共密匙传给各Slave节点即可。
这时候,Slave1和Slave2节点已经可以SSH连接Master节点了,如果需要三节点互相通信,将Master的公匙信息authorized_keys复制到Slave1和Slave2的.ssh目录下:
scp authorized_keys dida@Slave1:/home/Slave1/.ssh/authorized_keys
scp authorized_keys dida@Slave2:/home/Slave2/.ssh/authorized_keys此时三节点可以通过SSH互相无密码连接了
step3:修改Master、Slave1、Slave2配置文件
hadoop版本为2.6,配置文件全部在hadoop/etc/hadoop/文件夹下
依次修改如下:
1、配置 hadoop-env.sh
export JAVA_HOME=/home/dida/jdk1.7.0_752、配置 yarn-env.sh
# some Java parameters
export JAVA_HOME=/home/dida/jdk1.7.0_753、配置 core-site.xml,新建tmp文件夹
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/dida/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.dida.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.dida.groups</name>
<value>*</value>
</property>
</configuration>4、配置 hdfs-site.xml,新建/dfs/name与/dfs/data文件夹
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/dida/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/dida/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>5、配置 mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xml"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>6、配置 yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>7、配置slaves文件(2.6好像是不用配置master文件的?反正我照着之前的还是新建了master并配置Master)
Slave1
Slave2将上述所有文件复制到所有节点相应文件夹下,配置工作就完成了
step4:验证配置
进入安装目录
cd ~/hadoop/ 格式化
namenode:./bin/hdfs namenode –format 启动hdfs
dida@Master:~/hadoop$ ./sbin/start-dfs.sh
15/04/04 10:26:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [Master]
Master: starting namenode, logging to /home/dida/hadoop/logs/hadoop-dida-namenode-Master.out
Slave2: starting datanode, logging to /home/dida/hadoop/logs/hadoop-dida-datanode-Slave2.out
Slave1: starting datanode, logging to /home/dida/hadoop/logs/hadoop-dida-datanode-Slave1.out
Starting secondary namenodes [Master]
Master: starting secondarynamenode, logging to /home/dida/hadoop/logs/hadoop-dida-secondarynamenode-Master.out
15/04/04 10:34:49 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable开启完成,查看进程
dida@Master:~/hadoop$ jps
3946 NameNode
4293 Jps
4158 SecondaryNameNode
Slave1、Slave2上面进程为: datenode启动yarn
dida@Master:~/hadoop$ ./sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/dida/hadoop/logs/yarn-dida-resourcemanager-Master.out
Slave1: starting nodemanager, logging to /home/dida/hadoop/logs/yarn-dida-nodemanager-Slave1.out
Slave2: starting nodemanager, logging to /home/dida/hadoop/logs/yarn-dida-nodemanager-Slave2.out查看进程
dida@Master:~/hadoop$ jps
3946 NameNode
4495 Jps
4158 SecondaryNameNode
4383 ResourceManager
Slave1、Slave2上面进程为: datenode nodemanager一些相关状态查询
查看集群状态:./bin/hdfs dfsadmin –report
查看文件块组成: ./bin/hdfsfsck/ -files -blocks
查看HDFS: http://Master:50070
查看RM: http://Master:8088 我就只看了下如下两个状态
1、查看集群状态
dida@Master:~/hadoop$ ./bin/hdfs dfsadmin -report
15/04/04 10:48:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: 39891361792 (37.15 GB)
Present Capacity: 27972059136 (26.05 GB)
DFS Remaining: 27972009984 (26.05 GB)
DFS Used: 49152 (48 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.109.130:50010 (Slave1)
Hostname: Slave1
Decommission Status : Normal
Configured Capacity: 19945680896 (18.58 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 6015664128 (5.60 GB)
DFS Remaining: 13929992192 (12.97 GB)
DFS Used%: 0.00%
DFS Remaining%: 69.84%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sat Apr 04 10:48:42 CST 2015
Name: 192.168.109.131:50010 (Slave2)
Hostname: Slave2
Decommission Status : Normal
Configured Capacity: 19945680896 (18.58 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 5903638528 (5.50 GB)
DFS Remaining: 14042017792 (13.08 GB)
DFS Used%: 0.00%
DFS Remaining%: 70.40%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sat Apr 04 10:48:43 CST 20152、查看HDFS
http://Master:50070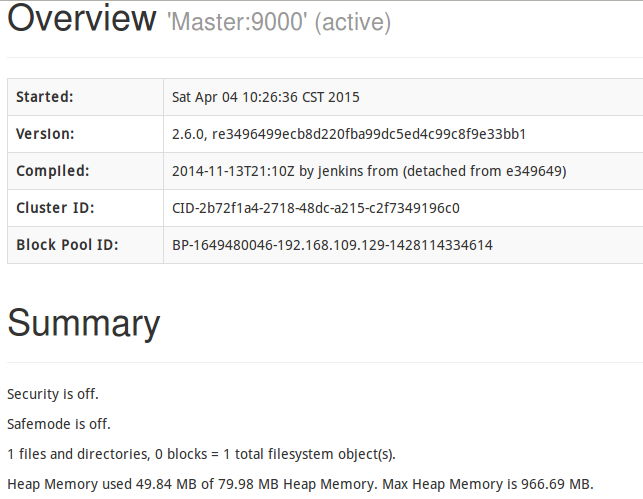
截图区域太小(随便截取了两块)
step5:运行WordCount历程
将文件上传至hadoop的/input下
dida@Master:~/hadoop/input$ hadoop fs -put ./* /input查看hadoop的文件系统目录
dida@Master:~/hadoop/input$ hadoop fs -ls /input
15/04/05 19:29:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 dida supergroup 26 2015-04-05 19:29 /input/f1
-rw-r--r-- 1 dida supergroup 38 2015-04-05 19:29 /input/f2运行示例程序(WordCount):
dida@Master:~/hadoop$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /input /output
15/04/05 19:32:27 INFO client.RMProxy: Connecting to ResourceManager at Master/192.168.109.129:8032
15/04/05 19:32:29 INFO input.FileInputFormat: Total input paths to process : 2
15/04/05 19:32:30 INFO mapreduce.JobSubmitter: number of splits:2
15/04/05 19:32:31 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1428231744993_0002
15/04/05 19:32:32 INFO impl.YarnClientImpl: Submitted application application_1428231744993_0002
15/04/05 19:32:32 INFO mapreduce.Job: The url to track the job: http://Master:8088/proxy/application_1428231744993_0002/
15/04/05 19:32:32 INFO mapreduce.Job: Running job: job_1428231744993_0002
15/04/05 19:32:45 INFO mapreduce.Job: Job job_1428231744993_0002 running in uber mode : false
15/04/05 19:32:45 INFO mapreduce.Job: map 0% reduce 0%
15/04/05 19:33:00 INFO mapreduce.Job: map 50% reduce 0%
15/04/05 19:33:04 INFO mapreduce.Job: map 100% reduce 0%
15/04/05 19:33:08 INFO mapreduce.Job: map 100% reduce 100%
15/04/05 19:33:08 INFO mapreduce.Job: Job job_1428231744993_0002 completed successfully
15/04/05 19:33:08 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=125
FILE: Number of bytes written=317729
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=248
HDFS: Number of bytes written=75
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=30554
Total time spent by all reduces in occupied slots (ms)=4923
Total time spent by all map tasks (ms)=30554
Total time spent by all reduce tasks (ms)=4923
Total vcore-seconds taken by all map tasks=30554
Total vcore-seconds taken by all reduce tasks=4923
Total megabyte-seconds taken by all map tasks=31287296
Total megabyte-seconds taken by all reduce tasks=5041152
Map-Reduce Framework
Map input records=4
Map output records=13
Map output bytes=115
Map output materialized bytes=131
Input split bytes=184
Combine input records=13
Combine output records=11
Reduce input groups=11
Reduce shuffle bytes=131
Reduce input records=11
Reduce output records=11
Spilled Records=22
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=1022
CPU time spent (ms)=17130
Physical memory (bytes) snapshot=403795968
Virtual memory (bytes) snapshot=1102848000
Total committed heap usage (bytes)=257892352
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=64
File Output Format Counters
Bytes Written=75如上显示的过程即表示一切正常
查看程序运行结果
dida@Master:~/hadoop$ hadoop fs -cat /output/part-r-00000
15/04/05 19:34:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
are 1
bye 2
do 1
going 1
hello 1
idon 1
to 1
what 1
world 2
you 1














 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









