







一. 问题描述
每个人都希望自己能获得更高的收入,而影响收入高低的因素有很多,能否通过大数据分析来找出对收入影响相对较大的因素?
二. 研究意义
如果我们知道对收入高低起决定性的作用,或者哪些因素组合在一起也能增大收入的可能性,那可以帮助很多人少走弯路,朝着正确的方向努力,早日达到目标。
三. 数据预处理
1. 选取数据集
本报告选取“adult”数据集,由美国人口普查数据集库抽取而来。
该数据集类变量为年收入是否超过50k,属性变量包含年龄,工种,学历,职业,人种等14个属性变量,其中有7个类别型变量。共有30000多条数据。
2. 预处理
由于capital-gain、capital-loss属性缺失70%以上的数据,所以选择删去这两个属性。
在其他类变量中,有缺少或异常属性400多条,占总数据比重较小,也选择删去。
四. 数据可视化
1.workclass
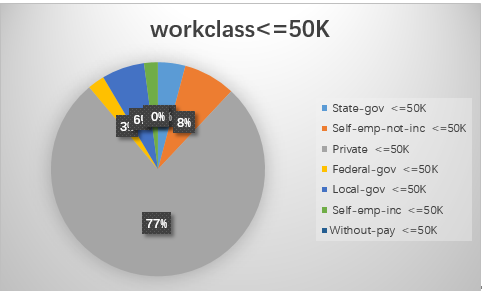
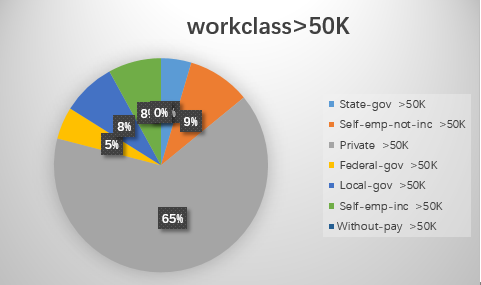
2.education
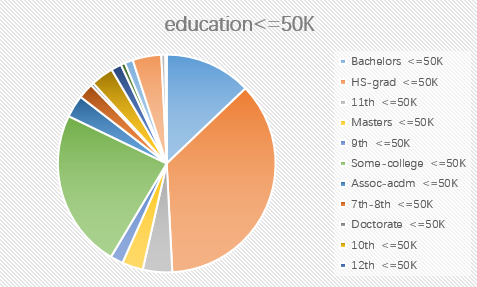
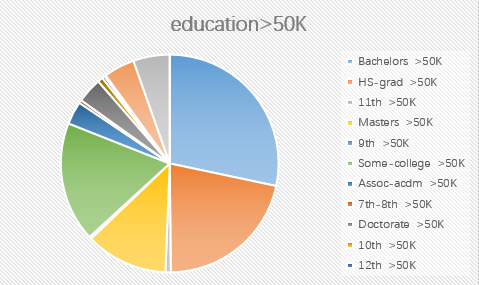
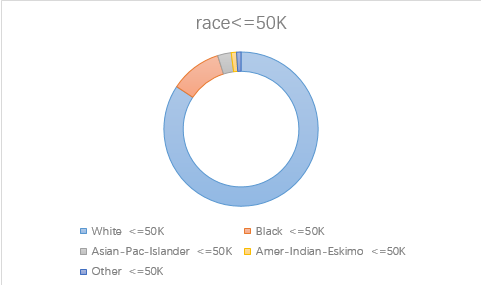
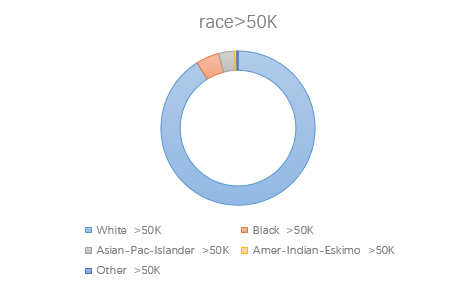
3.race
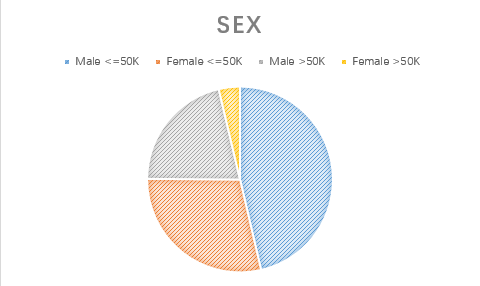
4.sex
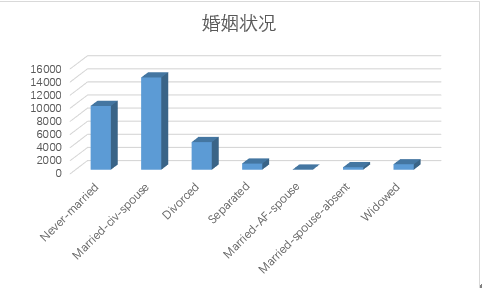
5.marital-status
五. 算法选取与实现
本次报告中选用决策树算法。决策树是一种依托决策而建立起来的一种树。在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某个可能的属性值,而每一个叶子节点则对应从根节点到该叶子节点所经历的路径所表示的对象的值。决策树仅有单一输出,如果有多个输出,可以分别建立独立的决策树以处理不同的输出。
由于数据量过大,普通决策树不能达到预期效果,所以再用预剪枝进行处理。预剪枝是在决策树生成过程中,在划分节点时,若该节点的划分没有提高其在训练集上的准确率,则不进行划分。
下面是预剪枝决策树程序
1. 计算数据集的基尼系数
def calcGini(dataSet): numEntries=len(dataSet) labelCounts={} #给所有可能分类创建字典 for featVec in dataSet: currentLabel=featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel]=0 labelCounts[currentLabel]+=1 Gini=1.0 #以2为底数计算香农熵 for key in labelCounts: prob = float(labelCounts[key])/numEntries Gini-=prob*prob return Gini
2. 对离散变量划分数据集,取出该特征取值为value的所有样本
def splitDataSet(dataSet,axis,value): retDataSet=[] for featVec in dataSet: if featVec[axis]==value: reducedFeatVec=featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet
3. 对连续变量划分数据集,direction规定划分的方向&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









