







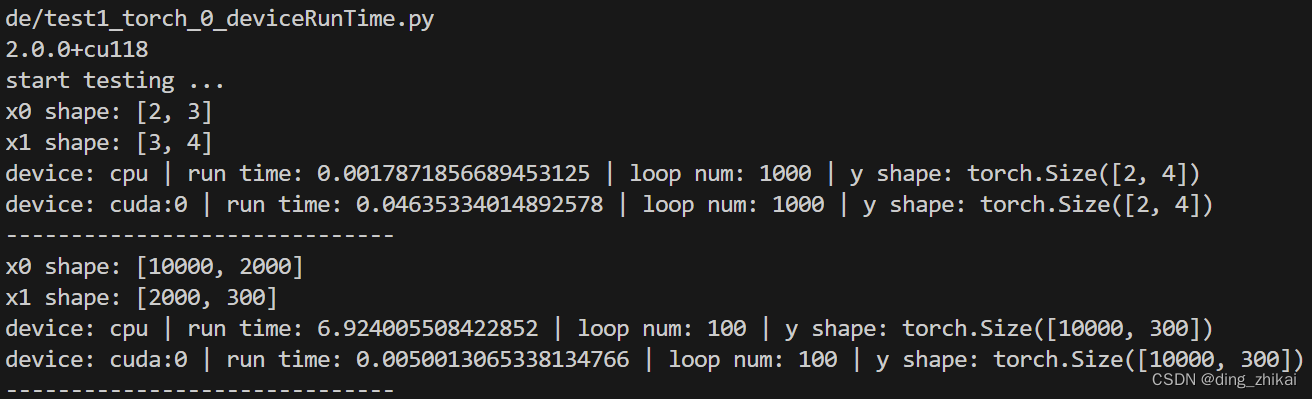
1. 结论
很小的矩阵运算 cpu 更快
大矩阵运算 gpu 快很多
2. 代码样例
#%% import
import torch
import time
print(torch.__version__)
#%% test funcs
def show_time_of_loopMatmulByDevice(loop_n, x0, x1, device_str="cpu"):
if loop_n < 1:
print("warn | bad loop num:", loop_n)
return
device = torch.device(device_str) # 指定 cpu 或 gpu
x0 = x0.to(device)
x1 = x1.to(device)
t0 = time.time()
for i in range(loop_n): # 循环多个 以便放大运行时间 且使结果更具说服力
y = torch.matmul(x0, x1)
t1 = time.time()
print("device:",y.device,"| run time:",t1-t0, "| loop num:",loop_n,"| y shape:",y.shape)
def test1(x0_shape, x1_shape, loop_n=100):
x0 = torch.randn(x0_shape[0],x0_shape[1])
x1 = torch.randn(x1_shape[0],x1_shape[1])
print("x0 shape:",x0_shape)
print("x1 shape:",x1_shape)
show_time_of_loopMatmulByDevice(loop_n, x0, x1, "cpu")
show_time_of_loopMatmulByDevice(loop_n, x0, x1, "cuda")
print("-"*30)
#%% main
if __name__ == "__main__":
print("start testing ...")
test1([2,3],[3,4],1000)
test1([10000,2000],[2000,300],100)
3. 运行结果















 3286
3286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









