







需要解决的问题描述:
用户购买物品数据集,每行存储数据格式(user_id,item_id,category_id,ratings,helpfulness,timestamp)
数据事例:
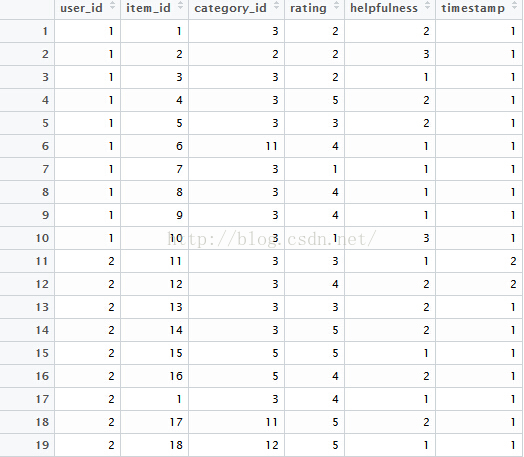
去除那些item_id只出现过一次的行。 问题的规模:922267obs of 2 variables
查找过资料发现如下两个方法:
1.定义一个函数
deleteuniquelines <- function(x) {# x为输入的数据框
stand.col <- x[, 1] # 设根据x的第一列进行删除操作 x[,1]中1为第一列 2为第二列 以此类推
count <- table(stand.col) #table函数可以得到每个上述列每个数所出现的频数
if (all(count < 2)) stop("no repeated records")
else {
ind <- sapply(stand.col, function(t) ifelse(count[as.character(t)] > 1, TRUE, FALSE))
}
return(x[ind, ])
}
test <- data.frame(name = c(1, 1, 2, 3, 3), score = c(2, 2, 3, 2, 4))#测试用例
deleteuniqueli
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









