







ConcurrentHashMap是Java1.5中引用的一个线程安全的支持高并发的HashMap集合类。这篇文章总结了ConcurrentHashMap的内部实现原理,是对于自己理解后的一些整理。
1.HashTable与ConcurrentHashMap的对比
HashTable本身是线程安全的,写过Java程序的都知道通过加Synchronized关键字实现线程安全,这样对整张表加锁实现同步的一个缺陷就在于使程序的效率变得很低。这就是为什么Java中会在1.5后引入ConcurrentHashMap的原因。
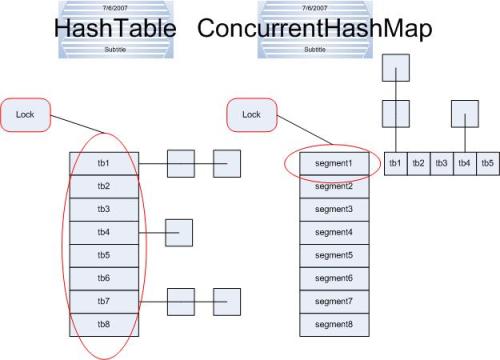
从图中可以看出,HashTable的锁加在整个Hash表上,而ConcurrentHashMap将锁加在segment上(每个段上),这样我们在对segment1操作的时候,同时也可以对segment2中的数据操作,这样效率就会高很多。
2.ConcurrentHashMap的内部结构
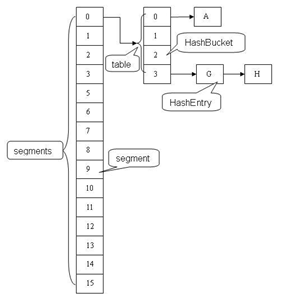
ConcurrentHashMap主要有三大结构:整个Hash表,segment(段),HashEntry(节点)。每个segment就相当于一个HashTable。
(1)HashEntry类
每个HashEntry代表Hash表中的一个节点,在其定义的结构中可以看到,除了value值没有定义final,其余的都定义为final类型,我们知道Java中关键词final修饰的域成为最终域。用关键词final修饰的变量一旦赋值,就不能改变,也称为修饰的标识为常量。这就意味着我们删除或者增加一个节点的时候,就必须从头开始重新建立Hash链,因为next引用值需要改变。
static final class HashEntry<K,V> {
final K key; // 声明 key 为 final 型
final int hash; // 声明 hash 值为 final 型
volatile V value; // 声明 value 为 volatile 型
final HashEntry<K,V> next; // 声明 next 为 final 型
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}由于这样的特性,所以插入Hash链中的数据都是从头开始插入的。例如将A,B,C插入空桶中,插入后的结构为:

(2)segment类
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
count 变量是一个计数器,它表示每个 Segment 对象管理的 table 数组(若干个 HashEntry 组成的链表)包含的 HashEntry 对象的个数。每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的总数。注意,之所以在每个 Segment 对象中包含一个计数器,而不是在 ConcurrentHashMap 中使用全局的计数器,是为了避免出现“热点域”而影响 ConcurrentHashMap 的并发性。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static f 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









