






序列化概念
- 序列化(Serialization)是指把结构化对象转化为字节流。
- 反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。
- Java序列化(java.io.Serializable)
Hadoop序列化的特点
- 序列化格式特点:
- 紧凑:高效使用存储空间。
- 快速:读写数据的额外开销小
- 可扩展:可透明地读取老格式的数据
- 互操作:支持多语言的交互
- Hadoop的序列化格式:Writable
Hadoop序列化的作用
- 序列化在分布式环境的两大作用:进程间通信,永久存储。
- Hadoop节点间通信。
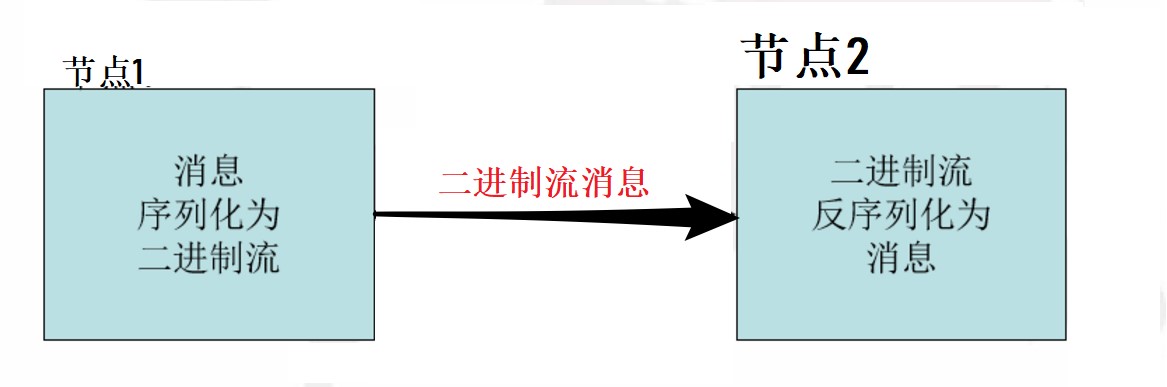
Writable接口
Writable接口, 是根据 DataInput 和 DataOutput 实现的简单、有效的序列化对象.MR的任意Key和Value必须实现Writable接口.

MR的任意key必须实现WritableComparable接口

常用的Writable实现类
Text一般认为它等价于java.lang.String的Writable。针对UTF-8序列。
例:
Text test = new Text("test");
IntWritable one = new IntWritable(1);


自定义Writable类
- Writable
- write 是把每个对象序列化到输出流
- readFields是把输入流字节反序列化

- 实现WritableComparable.
- Java值对象的比较:一般需要重写toString(),hashCode(),equals()方法
MapReduce输入的处理类
- 1、FileInputFormat:
- FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
- 2、InputFormat:
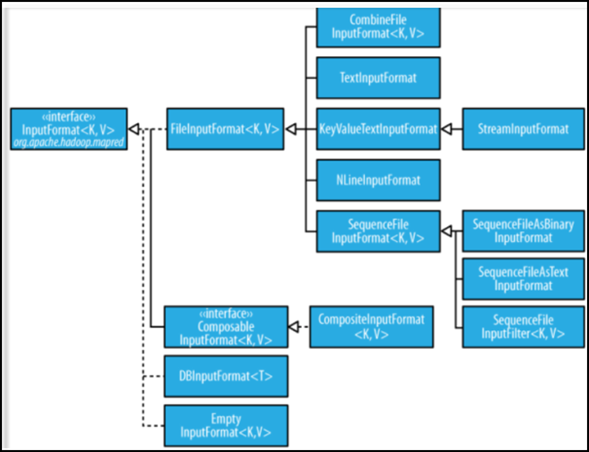
- InputFormat 负责处理MR的输入部分.有三个作用:
- 验证作业的输入是否规范.
- 把输入文件切分成InputSplit.
- 提供RecordReader 的实现类,把InputSplit读到Mapper中进行处理.
- InputFormat 负责处理MR的输入部分.有三个作用:
- 3、InputSplit:
- 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
- FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
- 如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
- 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。
- 例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
- 4、TextInputFormat:
- TextInputformat是默认的处理类,处理普通文本文件。
- 文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
- 默认以\n或回车键作为一行记录。
- TextInputFormat继承了FileInputFormat。
InputFormat类的层次结构
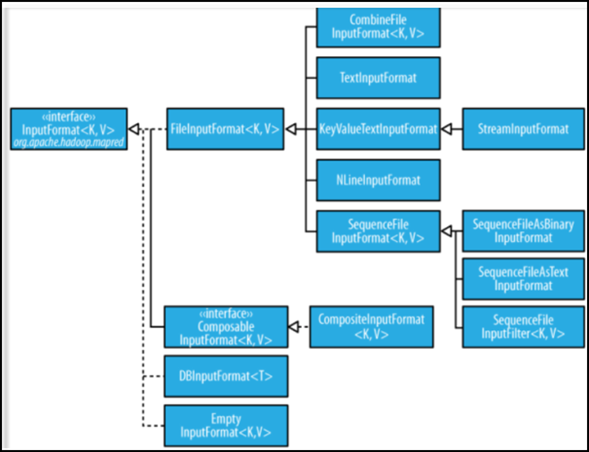
其他输入类
- 1、CombineFileInputFormat
- 相对于大量的小文件来说,hadoop更合适处理少量的大文件。
- CombineFileInputFormat可以缓解这个问题,它是针对小文件而设计的。
- 2、KeyValueTextInputFormat
- 当输入数据的每一行是两列,并用tab分离的形式的时候,KeyValueTextInputformat处理这种格式的文件非常适合。
- 3、NLineInputformat
- NLineInputformat可以控制在每个split中数据的行数。
- 4、SequenceFileInputformat
- 当输入文件格式是sequencefile的时候,要使用SequenceFileInputformat作为输入。
自定义输入格式
- 1、继承FileInputFormat基类。
- 2、重写里面的getSplits(JobContext context)方法。
- 3、重写createRecordReader(InputSplit split,TaskAttemptContext context)方法。
Hadoop的输出
- 1、TextOutputformat
- 默认的输出格式,key和value中间值用tab隔开的。
- 2、SequenceFileOutputformat
- 将key和value以sequencefile格式输出。
- 3、SequenceFileAsOutputFormat
- 将key和value以原始二进制的格式输出。
- 4、MapFileOutputFormat
- 将key和value写入MapFile中。由于MapFile中的key是有序的,所以写入的时候必须保证记录是按key值顺序写入的。
- 5、MultipleOutputFormat
- 默认情况下一个reducer会产生一个输出,但是有些时候我们想一个reducer产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。
案例实现:
数据
136315798506613726230503248124681200
1363157995052138265441012640200
1363157991076139264356561321512200
1363154400022139262511062400200
13631579930441821157596115272106200
13631579950748413841341161432200
1363157993055135604396581116954200
13631579950331592013325731562936200
1363157983019137191994192400200
1363157984041136605779916960690200
13631579730981501368585836593538200
1363157986029159890021191938180200
1363157992093135604396589184938200
136315798604113480253104180180200
13631579840401360284656519382910200
13726230503248124681sum
DataBean类
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class DataBean implements Writable{
//电话号码
private String phone;
//上行流量
private Long upPayLoad;
//下行流量
private Long downPayLoad;
//总流量
private Long totalPayLoad;
public DataBean(){}
public DataBean(String phone,Long upPayLoad, Long downPayLoad) {
super();
this.phone=phone;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
this.totalPayLoad=upPayLoad+downPayLoad;
}
/**
* 序列化
* 注意:序列化和反序列化的顺序和类型必须一致
*/
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(phone);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
out.writeLong(totalPayLoad);
}
/**
* 反序列化
*/
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.phone=in.readUTF();
this.upPayLoad=in.readLong();
this.downPayLoad=in.readLong();
this.totalPayLoad=in.readLong();
}
@Override
public String toString() {
return upPayLoad +"\t"+ downPayLoad +"\t"+ totalPayLoad;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public Long getUpPayLoad() {
return upPayLoad;
}
public void setUpPayLoad(Long upPayLoad) {
this.upPayLoad = upPayLoad;
}
public Long getDownPayLoad() {
return downPayLoad;
}
public void setDownPayLoad(Long downPayLoad) {
this.downPayLoad = downPayLoad;
}
public Long getTotalPayLoad() {
return totalPayLoad;
}
public void setTotalPayLoad(Long totalPayLoad) {
this.totalPayLoad = totalPayLoad;
}
}
DataCount类
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DataCount {
public static void main(String[] args) throws IOException, ClassNotFoundException,
InterruptedException {
// TODO Auto-generated method stub
Job job=Job.getInstance(new Configuration());
job.setJarByClass(DataCount.class);
job.setMapperClass(DataCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataBean.class);
FileInputFormat.setInputPaths(job, args[0]);
job.setReducerClass(DataCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataBean.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class DataCountMapper extends Mapper<LongWritable, Text, Text, DataBean>{
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, DataBean>.Context context)
throws IOException, InterruptedException {
String hang=value.toString();
String[] strings=hang.split("\t");
String phone=strings[1];
long up=Long.parseLong(strings[2]);
long down=Long.parseLong(strings[3]);
DataBean dataBean=new DataBean(phone,up, down);
context.write(new Text(phone), dataBean);
}
}
public static class DataCountReducer extends Reducer<Text, DataBean, Text, DataBean>{
@Override
protected void reduce(Text k2, Iterable<DataBean> v2,
Reducer<Text, DataBean, Text, DataBean>.Context context)
throws IOException, InterruptedException {
long upSum=0;
long downSum=0;
for(DataBean dataBean:v2){
upSum += dataBean.getUpPayLoad();
downSum += dataBean.getDownPayLoad();
}
DataBean dataBean=new DataBean(k2.toString(),upSum,downSum);
context.write(new Text(k2), dataBean);
}
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









