







 本文介绍了Hadoop中Writable接口的重要性和作用,详细讲解了序列化和反序列化概念,以及Hadoop为何不采用Java自带序列化机制的原因。文中讨论了Writable类的字节长度,并对比了定长和变长Writable类型的特点。此外,还解析了Writable接口的源码,强调了write和readFields方法在序列化和反序列化过程中的作用。最后,提到在自定义MapReduce框架的key或value时如何使用Writable接口,并指出key通常需要实现WritableComparable接口以支持排序。
本文介绍了Hadoop中Writable接口的重要性和作用,详细讲解了序列化和反序列化概念,以及Hadoop为何不采用Java自带序列化机制的原因。文中讨论了Writable类的字节长度,并对比了定长和变长Writable类型的特点。此外,还解析了Writable接口的源码,强调了write和readFields方法在序列化和反序列化过程中的作用。最后,提到在自定义MapReduce框架的key或value时如何使用Writable接口,并指出key通常需要实现WritableComparable接口以支持排序。
序列化和反序列化
序列化: 将数据结构或对象转换成二进制串的过程。以便在网络上传输或者写入到硬盘进行永久存储
反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
在Hadoop中,主要应用于进程通信和永久存储。进程将对象序列化为字节流,通过网络传输到另一进程,另一进程接收到字节流,通过反序列化转回到结构化对象,以达到进程间通信。Mapper、Combine、Reduce等过程中,都需要使用序列化和反序列化技术。它也是hadoop的核心技术之一,Writable是hadoop序列化实现。
hadoop 中Writable简介
由于java序列化机制计算量开销大,且序列化的结果体积大太。Hadoop在集群之间进行通讯或者RPC调用的时候,需要序列化,而且要求序列化要快,且体积要小,占用带宽要小,所以不适合Hadoop。因此,Hadoop拥有一套自己序列化机制。
hadoop中并没有使用Java自带的基本数据类型,而是自己开发了一套数据类型进行数据的传输。Hadoop提供了多种Writable,包括常见的基本类型和集合类型。这些类位于org.apache.hadoop.io包中。Writable接口是一个序列化对象的接口,可以将数据写入流或者从流中读出。
Writable类占用的字节长度
下面的表格显示的是Hadoop对Java基本类型包装后相应的Writable类占用的字节长度:
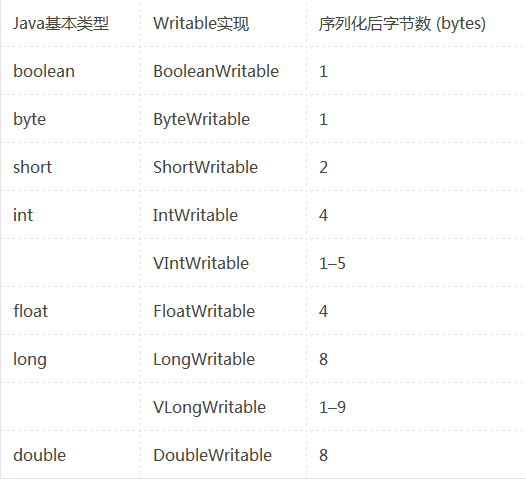
对于整数类型有两种Writable类型可以选择,一种是定长(fixed-length),IntWritable和LongWritable;另一种是变长(variable-length),VIntWritable和VLongWritable。定长的Writable类型适合数值均匀分布的情形,而变长的Writable类型适合数值分布不均匀的情形并且数值不要超过当前类型的取值范围,一般情况下变长的Writable类型更节省空间。
Wratable类的结构
图片下载后观看比较清楚:

Writable 接口源码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









