






没啥技术含量,大家都说没用,只不过算法还有点意思。自己憋出来的,不知道是不是跟别人的一样。做递归得到子文件夹以及文件并不难,但是能够打印出树形,层次关系展示出来,有些难度。
比如
1--1
2--1
2
3--1
2
3
3--1
2
3
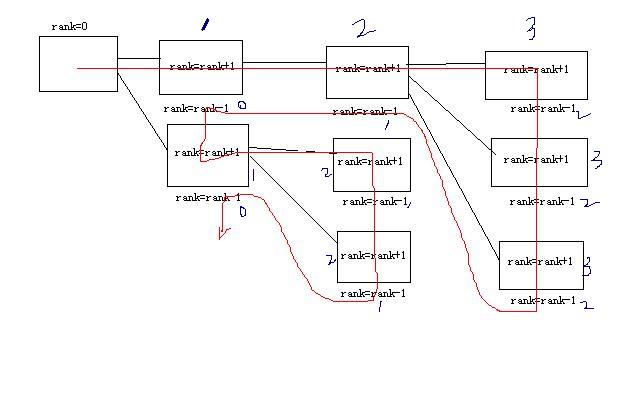
交错的层级关系,刚开始感觉很乱没有想明白,后来终于抓住了关键。只要算出每个层次的深度,就好办了。
我定义了一个rank,进入一个子文件夹时,让rank+1,遍历完子文件夹rank就-1。
如图充分说明了递归、遍历的顺序以及rank值变化:(丑了点。。。)
下面放代码:
生成树如下。没有微软tree生成的好。。。。。。。
















 4557
4557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









