







论文来自:
<LLaVA-Med: Training a Large Language-and-Vision
Assistant for Biomedicine in One Day>,2023, NeurIPS.
1. 概述
1.1 背景和动机
通用领域的大规模视觉-语言模型(VLM)虽能处理日常图文,但在医学影像场景下往往缺乏专业性。现有医学视觉问答(VQA)大多将问题视为分类任务,无法满足“开放式”对话需求。因此,通过LLM微调的生物医学聊天机器人(Biomedical Chatbots)具备研究价值。
LLaVA‑Med 的创新不在于改造模型,而是通过设计微调数据集,让7B的LLM具备医学问答与对话水平。
1.2 两类跨模态任务
-
Image Captioning(图像字幕生成)
- 定义: 为给定的图像自动生成一段自然语言描述性的文字(即字幕或标题),来概括图像的内容。
- 输入: 一张图像 ; 输出: 一段描述图像内容的自然语言文本。
- 目标: 生成一段流畅、准确且与图像内容相符的文字描述 (capturing the main objects, attributes, and their relationships in the image.)
- 评测方法:BLEU(文本相似度指标评估)
-
Visual Question Answering (VQA, 视觉问答)
- 定义: 根据用户提出的关于图像的自然语言问题,对给定的图像提供一个准确的自然语言回答。
- 输入: 一张图像和一个关于该图像的自然语言问题。输出: 关于图像中问题的自然语言答案。
- 目标: 理解图像内容以及问题的含义,并结合两者进行推理,给出准确、简洁的答案。这通常需要模型具备识别图像中的对象、属性、关系,甚至需要一定的常识知识。
- 评测方法: Accuracy(答案准确性,大模型评估)
1.3 医学图像介绍
1.3.1 Chest X-Ray(CXR,胸部 X 光片)
-
利用低剂量 X 光透过人体,根据组织密度在底片上形成衬度差异。
-
骨骼高度吸收显白,肺野低密度显暗。
-
穿透胸部来生成心脏、肺、骨骼(如肋骨、胸骨、脊柱)和胸部血管的二维图像。
主要用于诊断与胸部相关的疾病,如肺炎、肺结核、气胸、肺水肿、心脏扩大等。
1.3.2 CT (Computed Tomography, 计算机断层扫描)
-
X 光源与探测器环绕身体旋转,获取多个投影后重建出连续体层切片
-
提供比 CXR 更精细的断层/横截面切片的解剖信息。比CXR更清晰、更详细的骨骼、血管和软组织图像。
-
CT 扫描可以从不同角度获取一系列图像,由计算机重建出身体内的立体图像。
用于检查盆腔、胸腹部、颅脑、骨骼、血管及肿瘤病灶的三维定位与评估;常用于急诊创伤、肺结节筛查、肝脏病变检测等 。
1.3.3 MRI (Magnetic Resonance Imaging, 磁共振成像)
-
利用强磁场与射频脉冲使人体内水氢核共振,再接收松弛信号重建图像。
-
相比 CT,MRI 等电离辐射(X 射线),MRI软组织对比度更高。
检测大脑、脊髓、神经、肌肉、韧带、盆腔等软组织结构。常用于检查神经系统疾病、肌肉骨骼问题、肿瘤以及其他软组织异常。
1.3.4 Pathology Images (病理)
在显微镜下以高倍放大观察细胞形态与组织结构,用于肿瘤分级、炎症或感染诊断等, 可分为两种:
- 组织病理(Histopathology):
将活检或切除的组织做石蜡包埋、切片、染色(如 H&E)。
- 宏观病理(Gross Pathology):
对手术标本或尸检标本进行肉眼拍照,记录组织或器官的大小、形状、颜色、质地及病灶分布。
2.数据集 PMC‑15M
2.1 简介
PubMed Central Open Access 是开源医学/生物论文集合,这些文章中通常会包含图表、组织病理图、CT/MRI 等医学影像,以及作者写的图注和正文引用。
PMC‑15M 是本文贡献的数据集,是当前规模最大、覆盖最广的生物医学图文对数据集之一,涵盖大量真实科研论文中的图像、图注(caption)以及正文上下文句子(citances)。
PMC‑15M 从PubMed Central (PMC) 全文数据库中自动抽取得到的一个大规模《图像–文本》数据集,包含超过 1500 万对图像和相应的文字描述。
2.2 构建方法
该数据集由GPT‑4 自动生成,由于GPT‑4 只接收文字,为模仿真实“看图问诊”效果,对GPT-4输入图像、其Caption及上下文,让GPT-4输出 2–4 轮问答即:
- 输入
- 是对每篇文章抽取所有包含图像的图(figure)
- 抓取对应的 图注(caption)
- 抽取正文中提及图号的语句(称为 in-line mentions 或 citances);
另外还有以下特性:
- 这里从 PMC‑15M 中筛选只包含单图(single plot)的论文图像,确保一张图片对应一个图注。
- 模态均衡:按 CXR、CT、MRI、组织病理、宏观病理 五大常见模态,各采约 12 000 对,合计 60 000 对 (图像+图注)。
将上述内容形成一个三元组:[图像, 图注, 上下文]。
- 输出
2-4轮问答,用户问、助手答,并交替出现,JSON格式如下:
{
"image": "path/to/image.png", // 图像路径
"caption": "Figure caption text...", // 图注
"context": "Additional sentences...", // (可选)原文中提及该图的上下文句子
"conversations": [
{
"from": "human",
"value": "Where is the lesion located?"
},
{
"from": "gpt",
"value": "The lesion is located in the posterior aspect of the right upper lobe of the lung."
},
{
"from": "human",
"value": "Is it extending into the chest wall?"
},
{
"from": "gpt",
"value": "Yes, the CT scan suggests..."
}
// …更多轮对话
]
}
2.3 数据量
有三个量级用于实验比较,前两个仅包含caption, 最后一个包含论文中对该图的描述(即上下文):
-
10K
-
60K
-
60K-IM (inline mentions 即包含上下文语句)
具体案例如图所示:

- 上半部分是GPT-4的输入:
从PubMed Central 某篇论文中提取的生物医学图像,及其Caption, 及论文中提及该图像的上下文(figure mentions)
- 下半部分是从GPT-4的输出
生成的对话数据,通常包含2-4轮对话
2.4 数据集分析
数据的统计分析有三个子图:
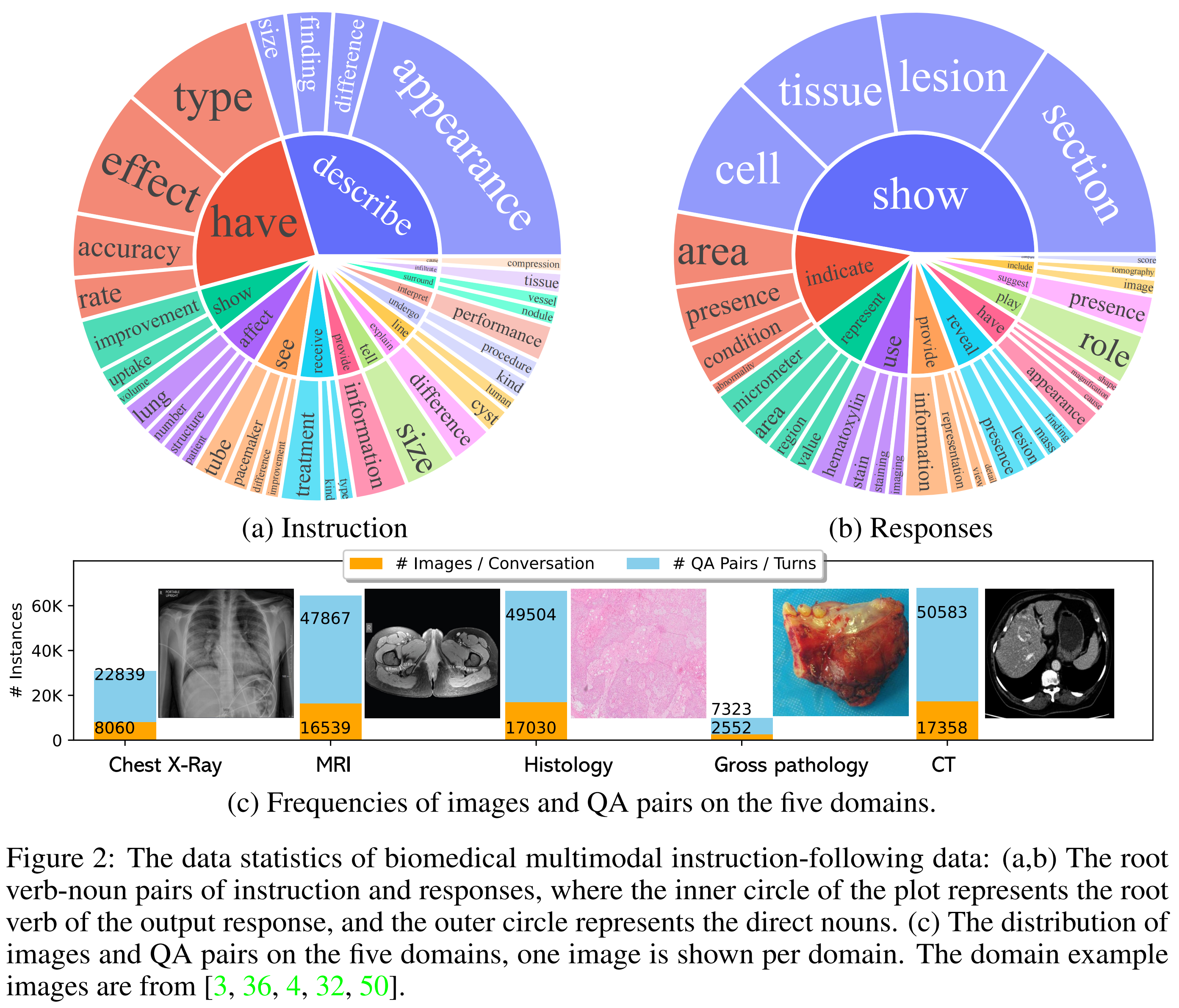
分别从<语言学特征>和<领域分布>两个角度展示了数据的结构和覆盖范围:
- a图
是Instruction指令的(动词-名词)统计。其中,内圈是动词(verbs),外圈是与之搭配的名词(nouns)。
这些是用户在训练数据中对图像发出的“请求”或“任务”类型。
例如:
内圈动词 “describe” 对应的外圈名词可能是:image, finding, appearance;
“explain” 可能与 difference, improvement 等词组合,说明用户请求模型“描述图像”、“解释发现”、“说明差异”等,反映出训练数据中任务的多样性和实际应用场景的覆盖面。
- b图
是Responses,即助手的回答(动词-名词)对,与(a)结构一样,但这是 GPT-4 回答中最常出现的动词-名词对。
展现了模型生成回复中常用的表达方式。
例如:回答中常用动词如:show, indicate, suggest, represent;名词如:lesion, tissue, mass, region, finding, presence。显示出模型回答中常提及病变、组织结构、异常区域等关键医学实体,具备一定的专业深度。
- c 图
问答对在五个医学子领域的分布,横轴是五个最常见的医学成像模态(即图像来源):
- Chest X-Ray
- CT(Computed Tomography)
- MRI(Magnetic Resonance Imaging)
- Histology(组织病理)
- Gross Pathology(大体病理图像)
每类展示了,图像数量,相应生成的 QA 对数量,这里某些图像应该有多轮对话,覆盖多种医学影像类型。
3.模型微调
论文比较的方法是Visual Med‑Alpaca,相比Visual Med‑Alpaca 仅用 54K 有限领域样本,LLaVA‑Med 用了 60K + 600K 两级数据,覆盖多类图像数据。
与LLaVA类似,采用两阶段微调策略,且为每个阶段制作对应微调数据集:
3.1 概念对齐(Concept Alignment)
即让模型理解图像所映射的医学术语,实现图像描述
从PMC-15M(1500万+生物医学图文对)中抽取 60 万(600K)对图文,设定“请描述这张图像”类指令,只更新图像→文本映射层,使模型快速学会医学术语对应的视觉特征。
- 符号表示
这里设生物医学图像为 X v X_v Xv, 对应的人类描述(Caption)为 X c X_c Xc,并设计一个图像表述指令 X q X_q Xq (即:“请描述这张图像”),这里一轮指令微调(Instruction)的样本为:
Human: X_q, X_v <stop> \n
Assistant: X_c <Strop> \n
- X q X_q Xq的两套问题模板:
30 词阈值由来:在 PMC‑15M 中约25%的图注短于 30 词,用这一截断就能自然区分“短小概括 vs. 详细叙述”的训练样本 ,因此:
- 对小于 30 词的短图注,采“简洁描述”问题,让模型既学会用一句话概括

-
对30 词以上的长图注,采“详细描述”问题,让模型学会展开多层次细节

-
阶段任务
-
快速扩展医用视觉词汇:人类医生在写图注(Caption)时会用到大量专业术语 (如“ground‑glass opacity”、“pneumothorax”)
-
模型通过“看到图像→输出图注”把这些新词和对应视觉特征对齐。
-
均衡复杂度与效率:600K 样本覆盖了 PMC‑15M 里丰富的病症、模态、解剖结构,足够多样;却又控制在一次 epoch 即可完成的规模,保持训练时间可控(约 7 h on 8×A100) 。
-
-
模型冻结策略
-
此阶段冻结视觉编码器和语言模型,仅更新“连接投影层”(将视觉特征映射到语言前缀的线性层),网络学到的是“如何把新视觉概念映射到已有词向量空间”,无需耗费资源微调整个大模型。
-
模型微调1轮后,能对从肺部 X 光到显微病理的各种医学影像做出专业的粗粒度描述。后续阶段会在此基础上教它做开放式、多轮对话式的问答。
-
3.2 开放式指令微调(Instruction Tuning)
这一阶段的目标是让模型学会按照各种用户指令,以对话形式“看图答题”。
- GPT4生成数据集
借助 GPT-4 对图文对进行“自指导”以生成多轮问答式指令数据集(60K 样本),再用此数据集完成端到端微调,次步仅冻结视觉编码器。
- 数据集:从 PMC‑15M 中筛选只包含单图(single plot)的图像,确保一张图片对应一个图注。
- 模态均衡:按 CXR、CT、MRI、组织病理、宏观病理 五大常见模态,各采约 12 000 对,合计 60 000 对 (图像+图注)
由于图注(Caption)往往过简,不足以支撑多轮对话,从论文正文中,抓取“Figure X 被提及那几句话”(citances),一并作为 GPT‑4 的 prompt 上下文,让它“假装看到了图像”能多角度发问和答。
- Instruction‑Tuning
上一阶段微调后的模型,缺乏交互性,不能应对用户提问。
所以需要多轮、开放式问答的数据,让模型学会
“接收用户问题→结合图像信息→给出针对性回复”
3.3 微调方法
模型训练流程的概览图如下:
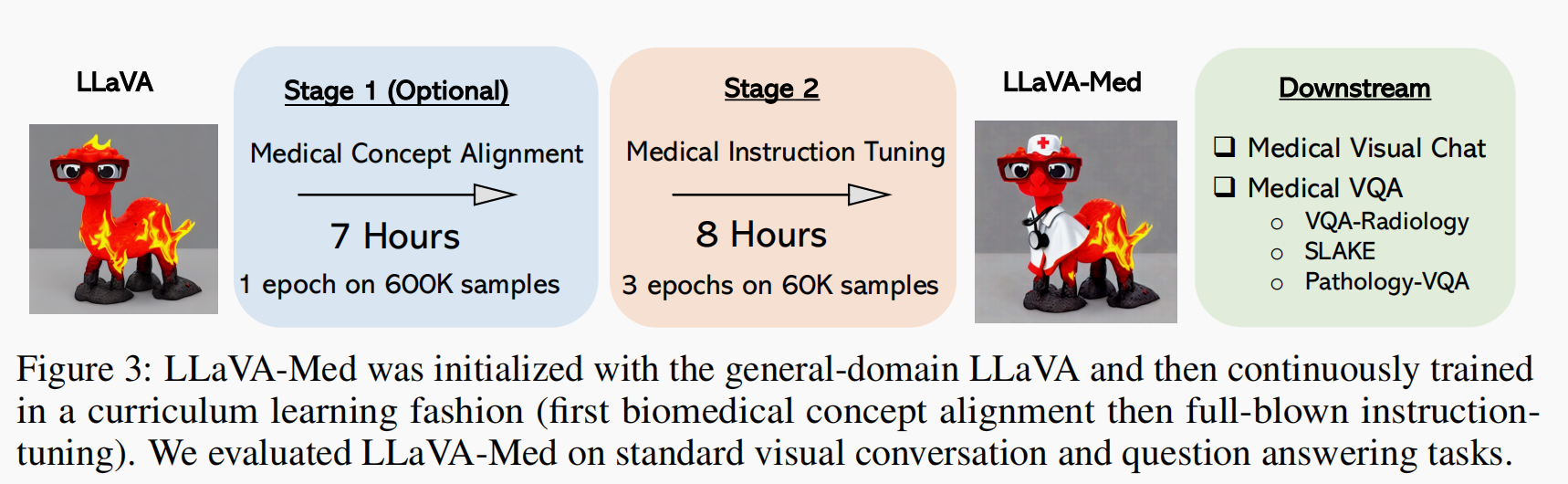
图中展示论文提出方法是如何将通用多模态模型(LLaVA)迁移并适配到生物医学领域。
- 微调前
模型初始化为(LLaVA),即开源的通用多模态模型 LLaVA (包括 CLIP 图像编码器和 Vicuna 语言模型)。
该模型原本是为通用图像-语言任务训练的,对医学图像不熟悉。
微调平台:8张 A100 40GB GPU
-
1阶段微调 (Stage 1 ,Optional)
-
训练时间:(600K样本,1 epoch)约 7小时
-
目标:医学概念对齐(Biomedical Concept Alignment),
-
数据量:600K 图像-图注对(来自 PMC-15M)
-
指令简单:类似 “请描述这张图像”
-
模型训练:投影层
-
训练任务:预测原始图注(Caption)
-
让模型对“肺部、肿瘤、病灶、染色”等医学术语和图像内容建立初步对齐感知;
该阶段对已经有一定视觉-语言对齐能力的模型是可选的(非必要)。
-
2阶段微调 (Stage 2 — Curriculum Learning from LLaVA to LLaVA-Med)
-
训练时间:(60K样本,3 epoch)约 8小时
-
数据量:60K 或 60K-IM(带 inline mentions)指令数据
-
数据形式:多轮问答(instruction-following)
-
模型训练:冻结视觉编码器, 微调语言模型 + 投影层
-
训练任务:学会多轮问答、根据医学图像指令做推理、判断、解释
-
-
微调后(模型评估)
-
多模态对话能力:构建 193 问评测集,GPT-4 作为参考,LLaVA-Med 在“开放式对话”得分≈50%,远超原版 LLaVA 。
-
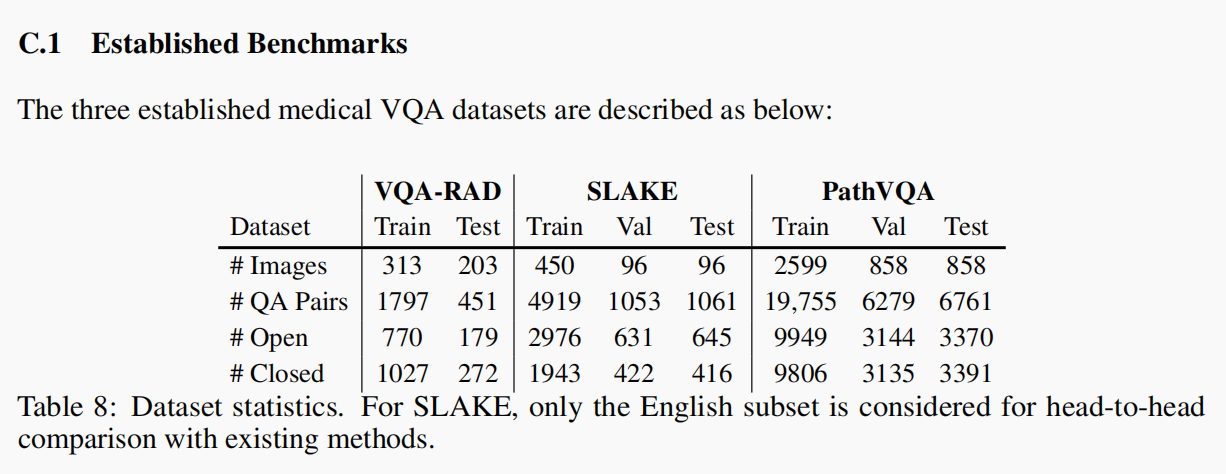
VQA 基准:在 VQA-RAD、SLAKE、PathVQA 三项公开数据集上,对比有监督 SOTA 方法,LLaVA-Med 在若干指标上(如闭集问答准确率、开放式问答召回率)实现新高 。
-
-
微调后(适配下游任务):
-
Medical Visual Chat(多轮医学图像对话任务)
-
Medical VQA:
-
VQA-RAD(放射学图问答)
-
图像类型:X光、CT、MRI
-
问题类型:开放式 + 是非题 + 问答题
-
数据规模:
-
图像数量:315 张
-
问题数QA(总):3,515 , (训练集: 1797,开放型/封闭式问题各一半)
-
特点:大多数是短语或一句话, 适合小模型训练(精调)
-
-
-
SLAKE (中文-英文双语数据集)
-
图像类型:X光为主,也有CT等
-
特点:每个问题配有对应的语义标签 + 可解释图谱(知识增强)
-
数据规模:
-
图像数:642 张
-
问题数:约7000 个, (训练集:4,919 , 开放型问题为主)
-
-
特点:多语言推理,训练跨语言能力
-
-
PathVQA(病理图像问答)
-
图像类型:病理切片、组织学图像
-
问题类型:视觉结构识别 + 医学概念推理
-
数据规模:
-
图像数:4,998 张
-
问题数:32,799 个 (训练集19,755,开放型/封闭式问题各一半)
-
-
复杂任务建模(大数据建模)
-
-
-
文中在附录有列出表格:
4.实验解读
4.1 定量分析
4.1.1 多轮对话的主观评分(表1)
通过GPT-4给不同结果打分,根据专业性、准确性、流畅性、合理性进行主观打分,具体结果如下:
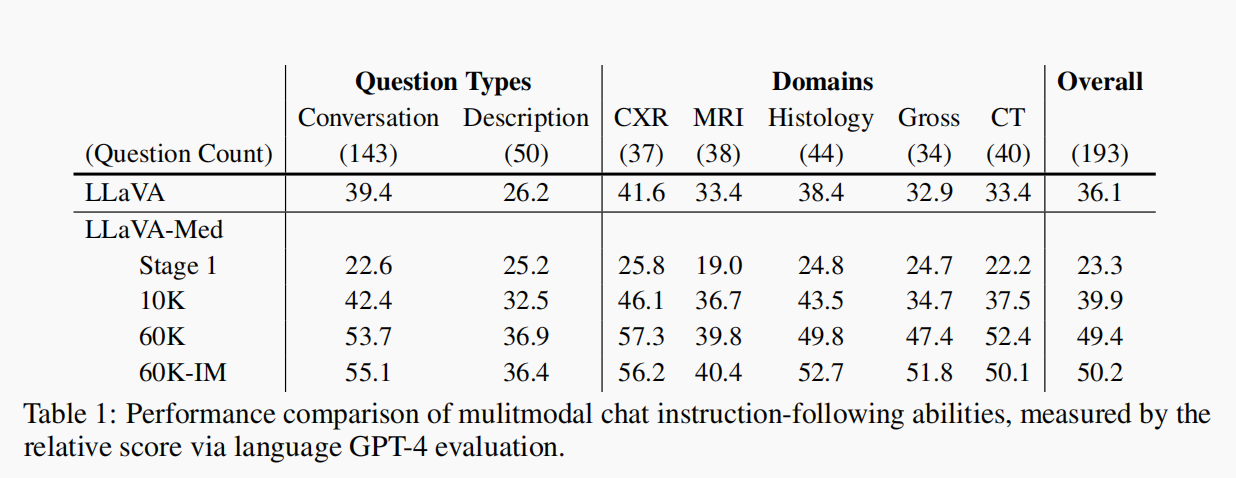
4.1.2 真实数据集的监督微调(表3)
该部分在:
- 开放式问题(Open)上评估 Recall:回答中是否覆盖了 Ground Truth 的关键词(即信息召回情况)。
- 封闭式问题(Closed), 即选择类问题,评估准确率Accuracy,即选择题答对的次数。
有以下两个结论:
- 从基础 LLaVA 到 LLaVA-Med 有显著提升,加入 inline mentions(IM) 更进一步提升。
- 微调 9 epoch 后几乎翻倍,达到 73.9 的平均 recall,体现出训练数据 + 精调的巨大效果。
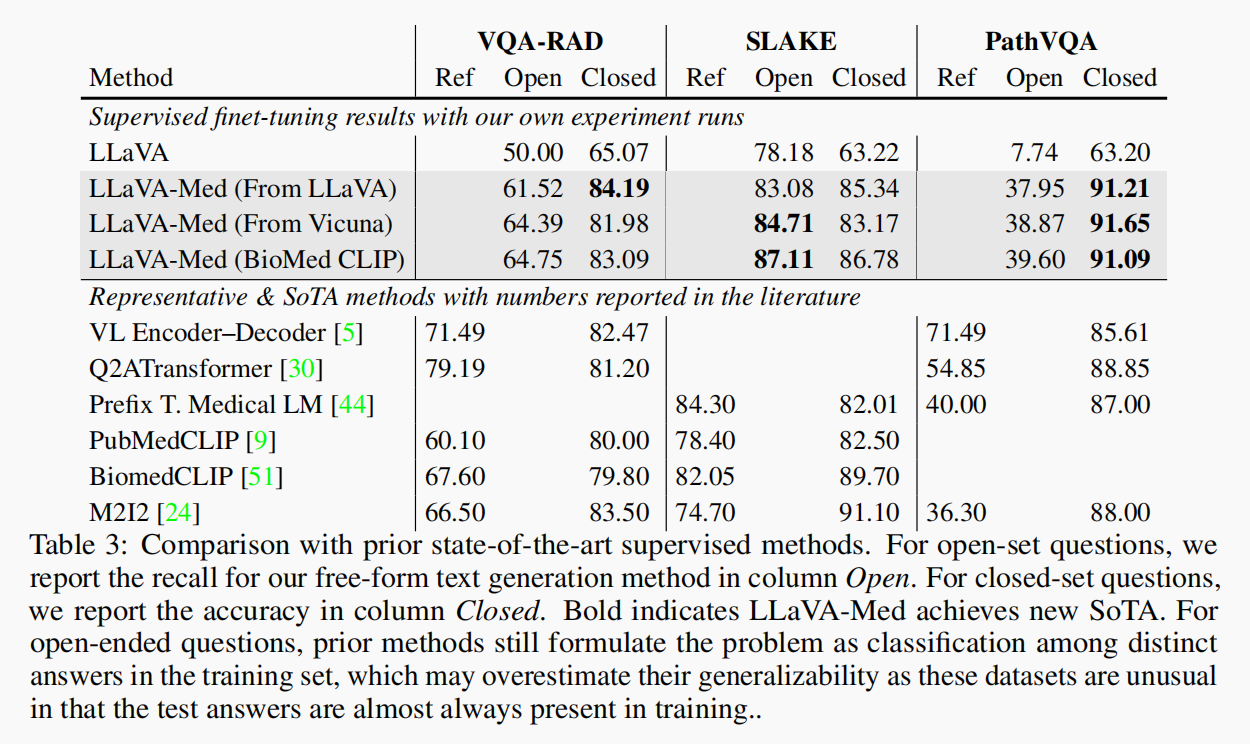
这里可以发现, 在封闭式问题上,模型回答准确率高达90%
4.1.3 微调各阶段与迭代次数影响(表4)
图a中:
- 1阶段微调数据来自 PubMed(image + caption)
- 2阶段微调数据来自GPT-4合成(Instruct 数据)
- BioMed 的视觉编码器性能最佳
图b中:
- 无1阶段,性能影响不大
- 仅在视觉编码器训练时,1阶段能提升性能
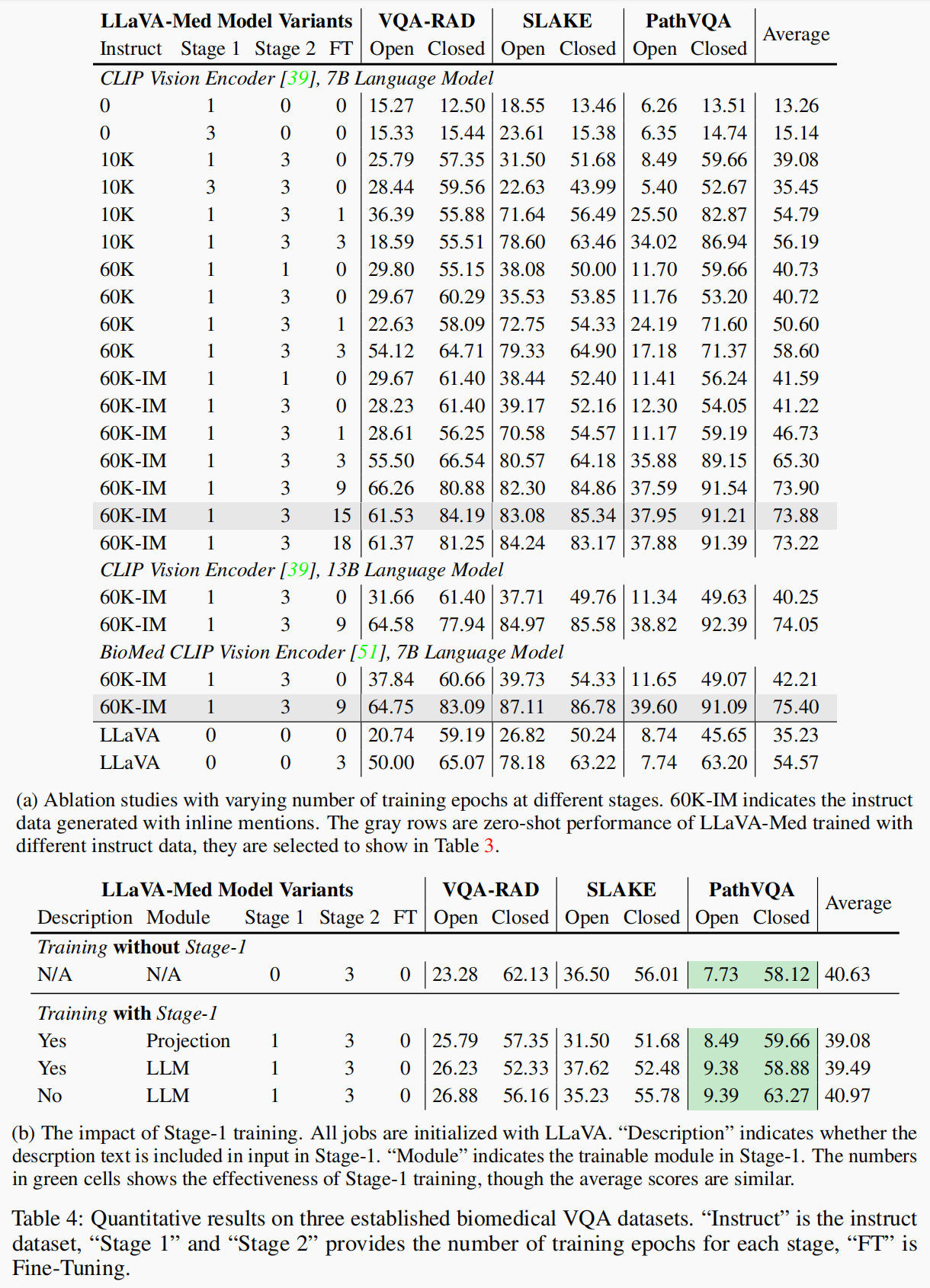
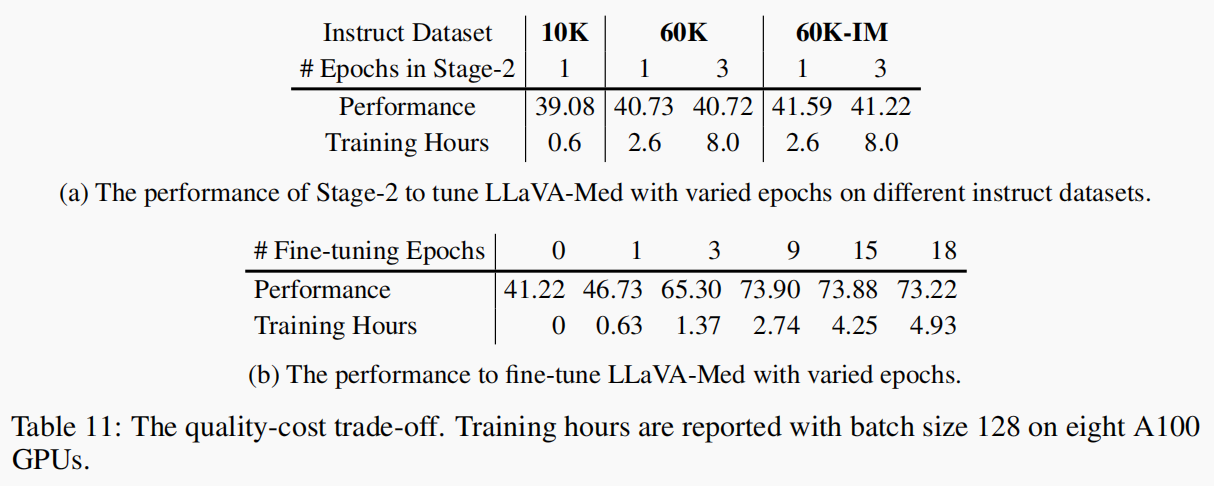
4.1.4 数据量与迭代次数(表11)
- 不同量级数据的训练时间、效果(VQA-Score)如表11-a所示,总结出如下规律:
- 随着数据量增大,性能在提升
- 但增加迭代次数,提升不明显
结论是,指令数据的质量,包括“语义丰富性”(如本数据的上下文),比重复迭代重要。
- 对已有模型(LLaVA-Med stege-2-60K-IM)继续用真实VQA数据集微调(VQA-RAD, SLAKE, PathVQA),
其结果如图11-b所示,经过两阶段微调后的分数是41.22,继续用真实数据集微调,在第9次迭代(epoch)时,性能接近饱和 (分数为 73.90), 之后出现过拟合。
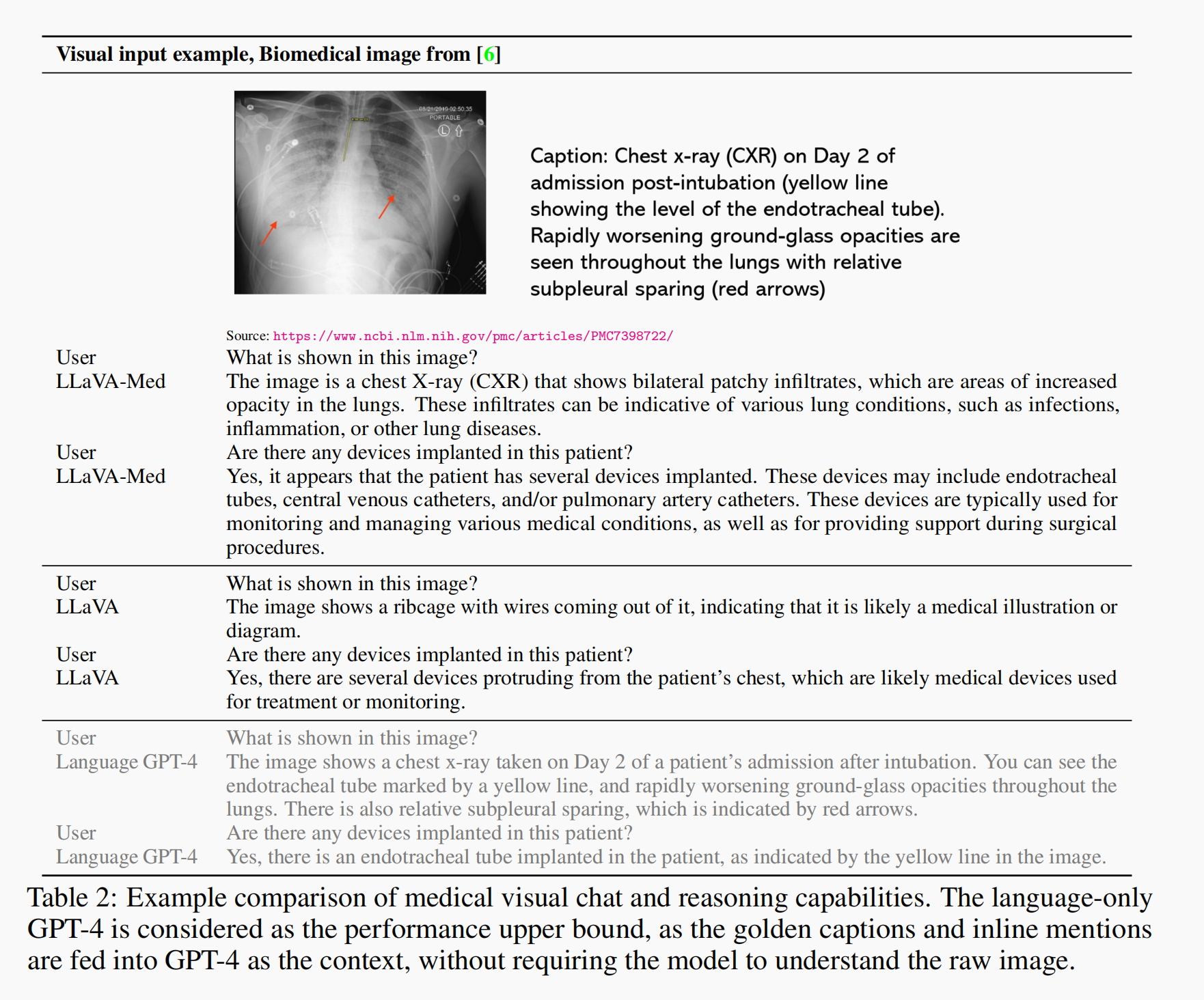
4.2定性分析
4.2.1 零样本提示(Zero-prompt, 表2)
不输入图注(caption),仅输入图像及问题,测试LLaVA的性能,结果如下:
其中GPT-4 不能输入图像,这里注入图注和上下文,评估结果如下:
- LLaVA: 无法理解图像
- LLaVA-Med: 理解图像且具有专业性
- 内容准确反映图像,但不是看图得到(通过图注得到),仅作为参考答案
4.2.2 中文理解能力(表12)
用Slake Bilingual数据集样本测试未经训练的中文训练样本,结果如图:

这里只是粗略判断图像成像类型(CT or T1 MRI), 证明模型具备跨语言理解能力。
4.2.3 CT-多类对话(表13)
图像是一张医学影像(腹部 + 骨盆的CT图像,冠状位 coronal view)。
问题是2轮对话形式,测试模型是否能:
-
识别图像类型和视角(结构理解)
-
识别图像中是否存在异常(医学推理)
这里LLaVA-Med:
-
成功识别出具体异常(盆腔肿块)
-
使用临床术语(tumor, cyst, mass)
-
表达有医学语气(“need further tests”)
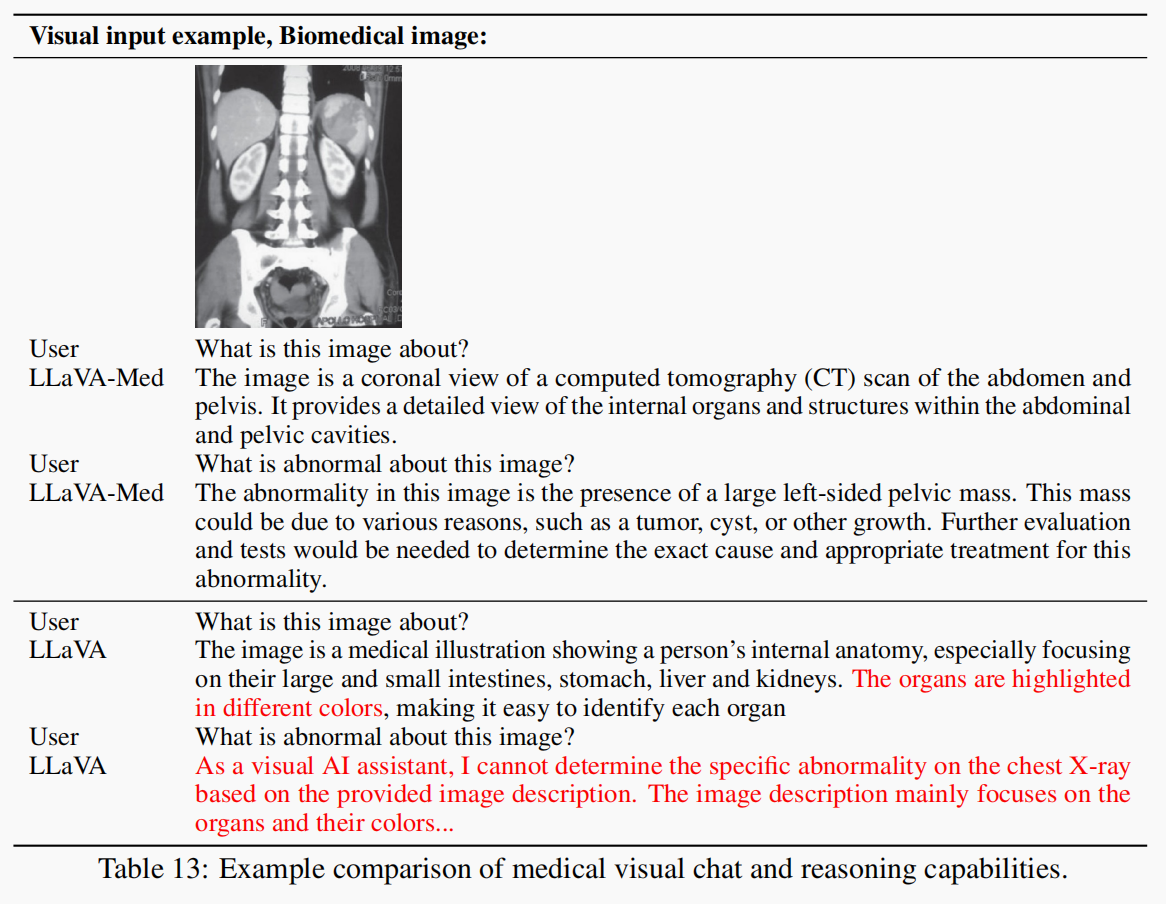
LLaVA-Med 在结构识别和医学推理方面的回答明显优于原始 LLaVA。这进一步验证了论文核心观点:
通用视觉语言模型(LLaVA)通过在专业医学指令数据上精调,能显著获得临床推理和对话能力。
4.2.4 腹部MRI多伦对话 (表14)
图像中带有一个 白色箭头,指向胰腺头部的囊性病变
-
问题 1:“What is the white arrow pointing to?” 说明模型具有图像定位 + 医学词汇理解能力
-
问题 2:“Could this be a mucinous cystic neoplasm?” 说明模型能进行假设性医学判断
-
问题 3:“Describe the appearance of the mucinous cystic neoplasm” 模型完成了一次类比式专业解释,贴近临床医生的表达
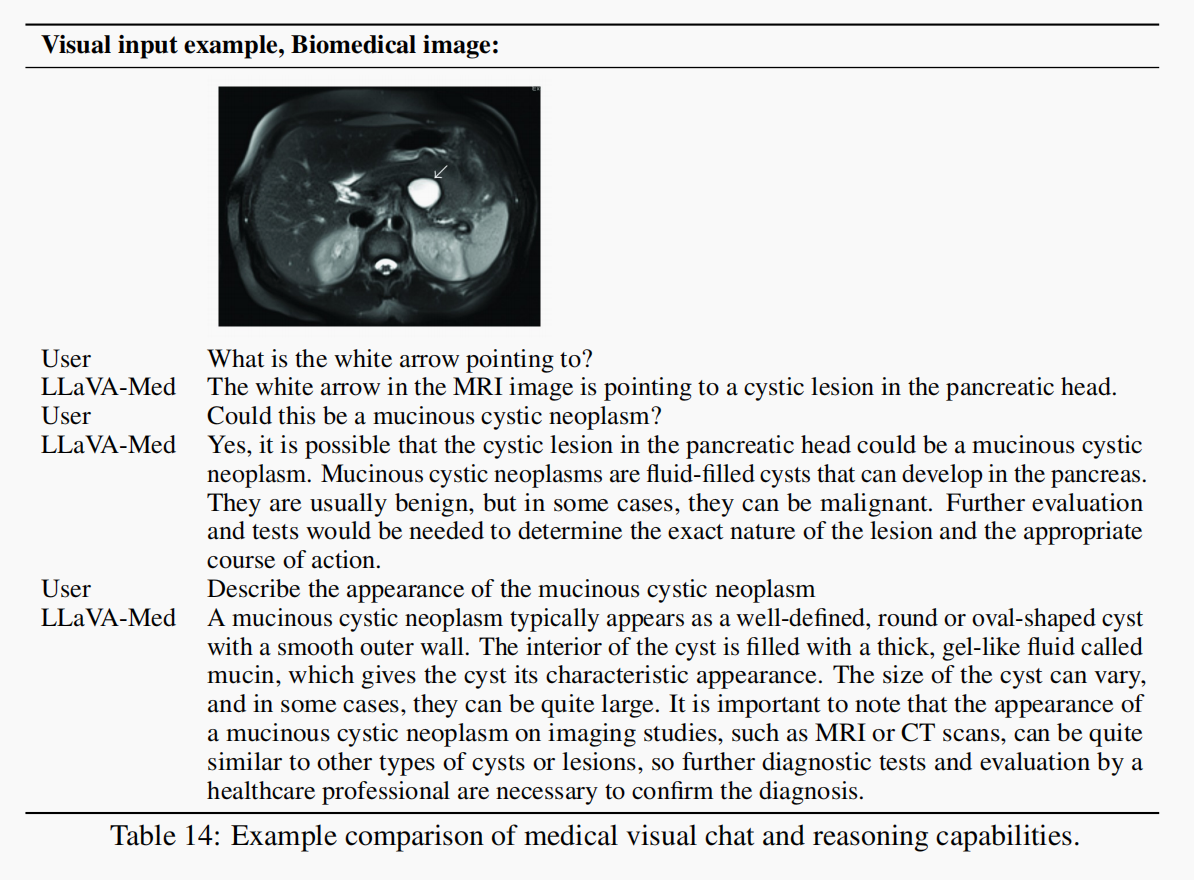
表14 表明 LLaVA-Med 在真实图像基础上,能与用户就疾病识别、鉴别诊断、成像特征解释进行自然、专业的多轮交流。
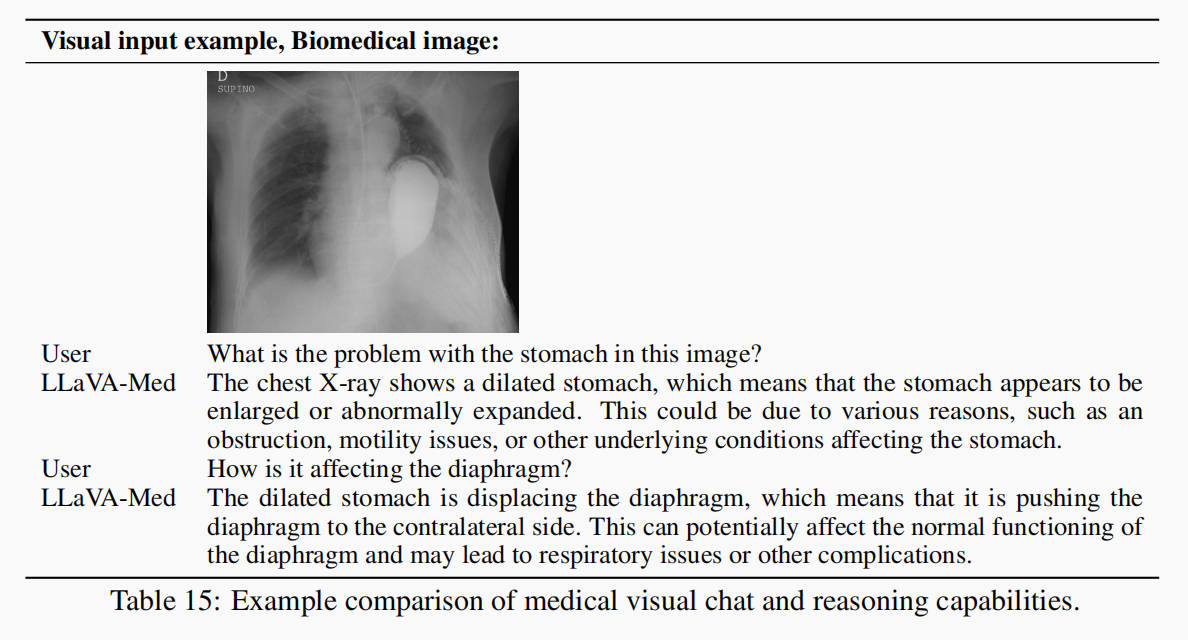
4.2.5 胸部X光 (Chest X-ray, 表15)
图中表现为胃部扩张(dilated stomach)
- 问题 1:“What is the problem with the stomach in this image?”
模型准确识别图像中的主要异常:dilated stomach,提出了多个可能病因:梗阻(obstruction)、动力障碍(motility issues),符合实际临床解读
- 问题 2:“How is it affecting the diaphragm?”
明确指出病变与膈肌位移之间的解剖学因果关系, 理解到位:胃扩张 → 膈肌推移 → 影响呼吸功能
LLaVA-Med 总结:
-
解剖定位理解 正确认识“胃部扩张”位置和特征,能完成图像结构间关系推理 (胃部→膈肌→呼吸系统)的连锁反应
-
对病因+病理机制推断 提出合理诊断路径,解释症状来源,临床风格语言 使用临床术语与分析语气,自然可信
-
LLaVA-Med 不仅能识别医学图像中的异常结构,还能推理这些异常对周边解剖结构和生理功能的影响,
相比表(13/14),表15增加了:“结构-功能推理”的维度:
5.其他
5.1 调用API 生成数据集
论文的图4展示了调用api生成数据集的模版:

大概代码如下:
messages = [
{"role": "system", "content": "...设定角色和规则..."},
{"role": "user", "content": "...示例问题1..."},
{"role": "assistant", "content": "...示例回答1..."},
{"role": "user", "content": "...新图像描述(图注)..."}
]
response = openai.ChatCompletion.create(
model="gpt-4",
messages=messages, # 构造的内容
temperature=0.7,
max_tokens=1000
)
reply = response["choices"][0]["message"]["content"]
print(reply)
构造内容如下:
{
"image": "figure_4.png",
"caption": "Figure 4: Contrast-enhanced CT of the abdomen...",
“Inline”: {“xxx1”, “xxx2”}
"conversations": [
{"from": "human", "value": "What is shown in this image?"},
{"from": "gpt", "value": "The image shows a contrast-enhanced CT..."},
{"from": "human", "value": "Is the lesion well-defined?"},
{"from": "gpt", "value": "Yes, the lesion appears to have a smooth border..."}
]
}
具体实例如论文图5:

5.2 后续作品
- MEDTRINITY-25M
《A LARGE-SCALE MULTIMODAL DATASET WITH MULTIGRANULAR ANNOTATIONS FOR MEDICINE》,ICLR, 2025
该方法增大了数据量,将桥接模块加入Q-Former / projector),具体表现如下:
阶段 训练模块 冻结模块 主要作用
阶段一 视觉编码器 + 投影层 语言模型 图文对齐表征
阶段二 语言模型 + 投影层 视觉可选冻结 图文生成指令理解
阶段三 语言模型 + 投影层 多数视觉模块 强化任务表现



















 2473
2473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









