







 本文通过介绍cross_val_score和GridSearchCV在KNN模型调优中的应用,详细探讨了如何利用交叉验证评估模型性能并找到最佳参数组合。重点讲解了如何手动和自动进行超参数搜索,以及数据集划分的稳定性和随机性对模型的影响。
本文通过介绍cross_val_score和GridSearchCV在KNN模型调优中的应用,详细探讨了如何利用交叉验证评估模型性能并找到最佳参数组合。重点讲解了如何手动和自动进行超参数搜索,以及数据集划分的稳定性和随机性对模型的影响。
前言
本文就介绍了机器学习的基础内容knn算法的模型调优,图片来源《Python大战机器学习》。
一、cross_val_score(选出最优评分的模型)

代码实现如下
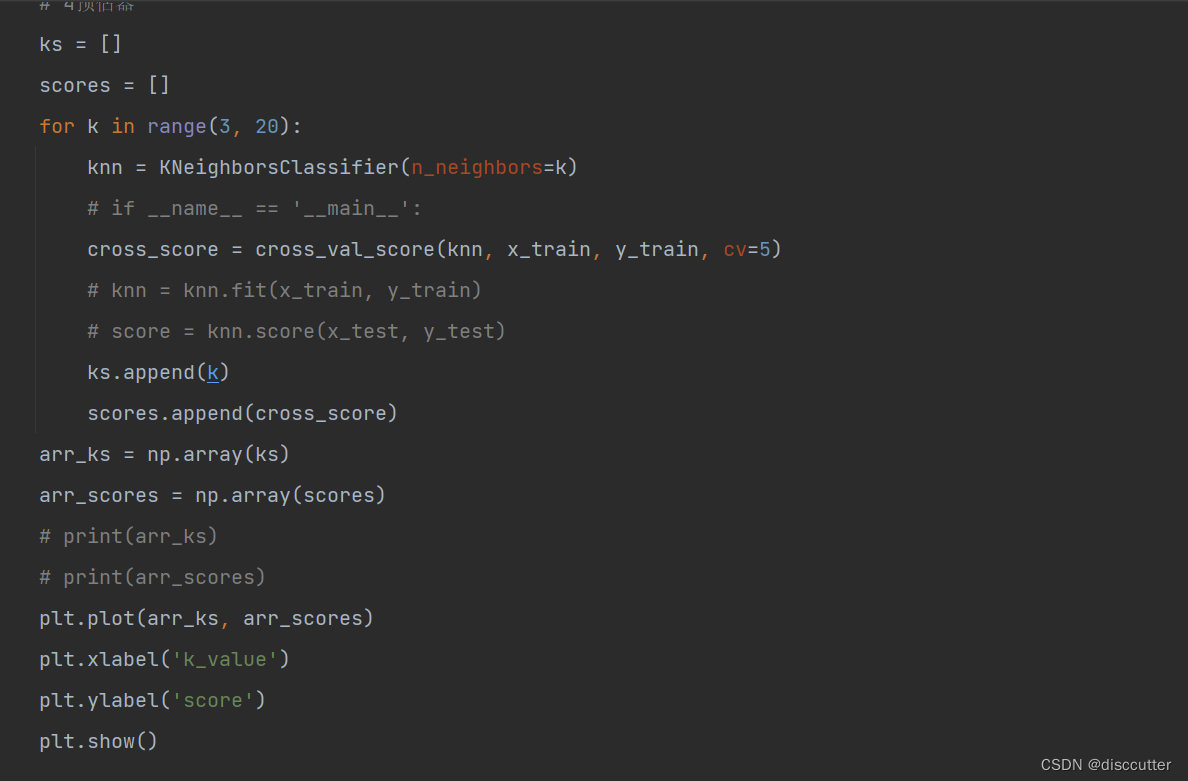
结果为: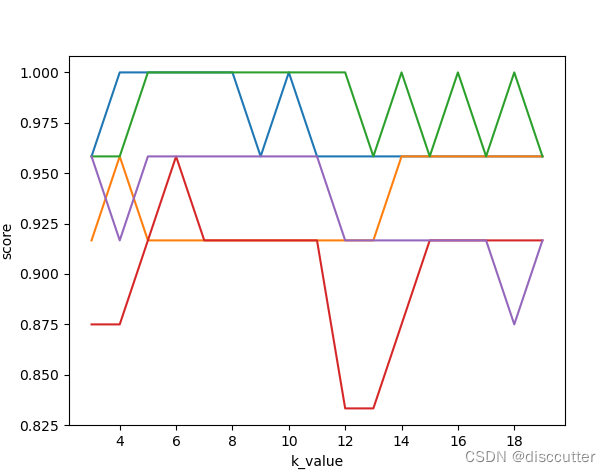
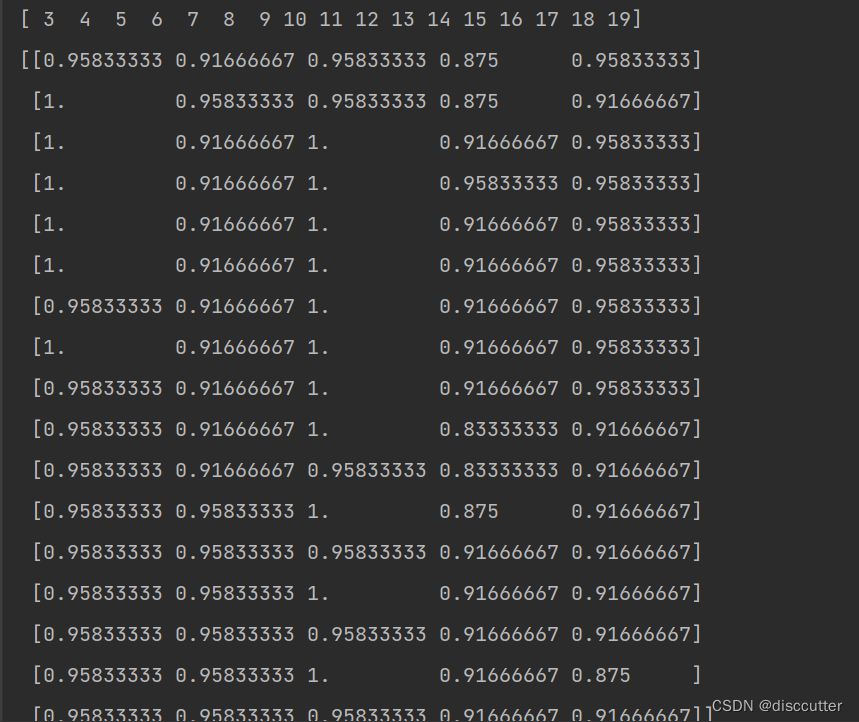
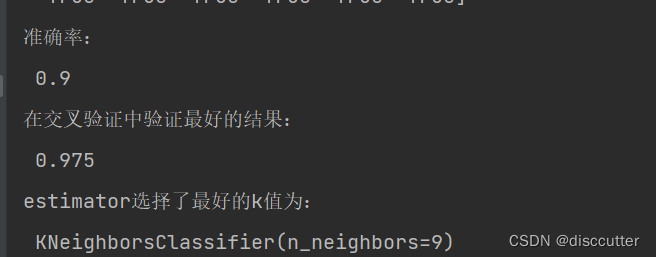
二、GridSearchCV(暴力搜索选出最优参数)

代码实现如下:
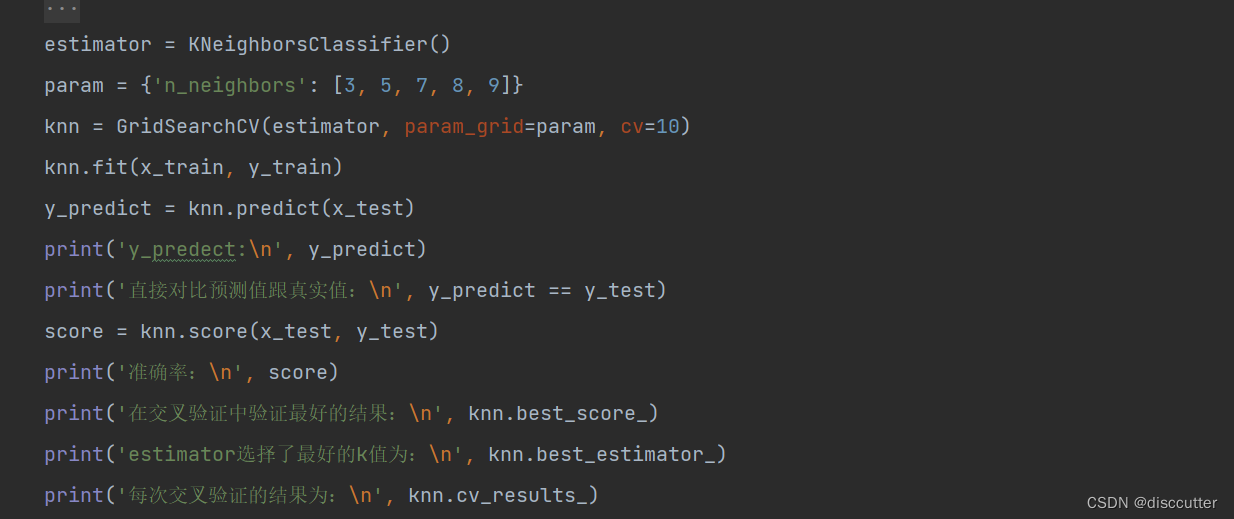
结果:
总结
①cross_val_score :用于获取每个交叉验证的得分,然后根据得分score来选择合适的超参数,通常需要编写手动完成交叉
②GridSearchCV :除了能够完成自行交叉验证外,返回了最后的超参数及对应的最优模型,但是k值的选取是自己添加,需要有先验经验
③划分数据集是需要固定数据,比如随机数的种子有没有固定,如果没有固定随机数种子,可能导致每次拆分的训练集和测试集都不一样,即使相同的参数范围,训练出的模型指标一般都不一样。
④例如:在sklearn可以随机分割训练集和测试集(交叉验证),只需要在代码中引入model_selection.train_test_split就可以了:
x_train, x_test, y_train,y_test=model_selection.train_test_split(x,y,test_size=0.2,random_state=0)
这里的random_state就是为了保证程序每次运行都分割一样的训练集和测试集。否则,同样的算法模型在不同的训练集和测试集上的效果不一样。
当你用sklearn分割完测试集和训练集,确定模型和初始参数以后,你会发现程序每运行一次,都会得到不同的准确率,无法调参。这个时候就是因为没有加random_state。加上以后就可以调参了。


















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











