







前言
这两天阅读了发表于TOS的关于分布式文件存储的论文,里面提出了一些比较前沿新颖的方法,理解了里面提出的一些思想,但也有一些地方由于知识水平有限,所不能进行连贯的把流程走通的地方(有机会一定阅读阅读源码),把我所理解的内容展示出来在这里和大家一起分享。
介绍
背景
- 高性能计算和大数据给数据存储和处理带来了极高的要求。
- RDMA(远程直接内存访问技术,在阅读论文之前需要先去了解以下这个技术,会使得理解论文变得轻松很多)在网络中带来的低时延和高带宽。
- 文件系统和网络层间的隔离,分层设计阻止了文件系统利用硬件的优势。
现有DFS的不足
- 数据在内存中的多个位置被多次复制。
- 网络越来越快,服务器会因CPU而成为处理大量客户端请求的瓶颈。
- 多次的网络往返和复杂的处理逻辑,使得DFS在分布式事务中具有较大的一致性开销。
论文的共享
- 提出基于RDMA的新颖I/O流,使其直接访问共享持久内存池。
- 客户端主动获取或推送数据,平衡服务器和网络负载。
- 重新设计了利用RDMA原语的元数据机制,包括用于低延迟通知的自识别元数据RPC。
- 设计了用于低开销一致性的collect-dispatch分布式事务。
架构
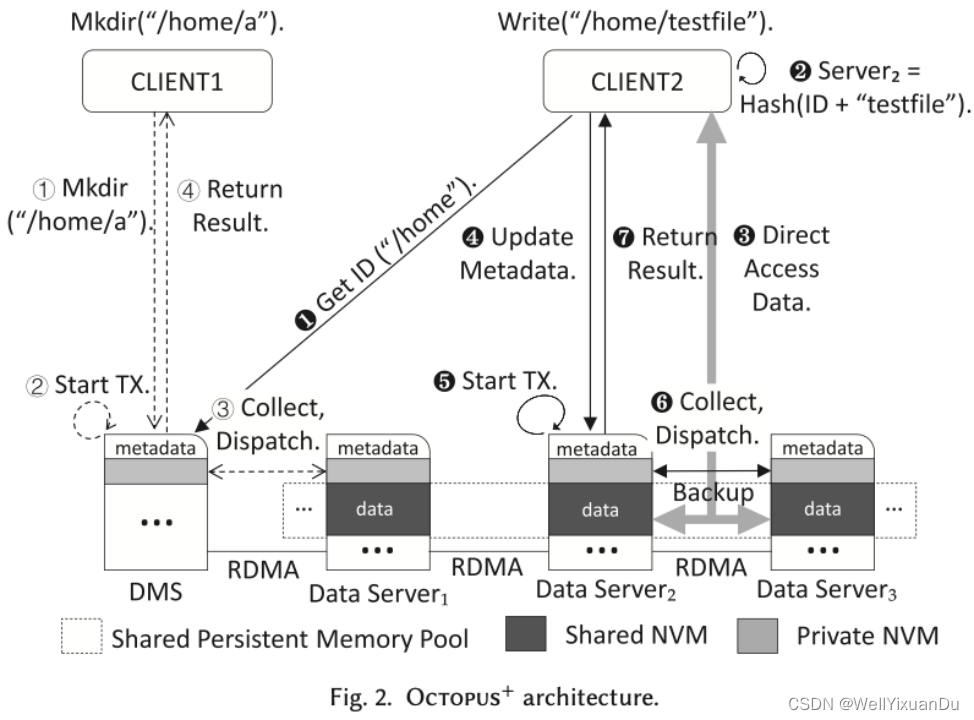
- DMS:用于保存所有目录的元数据
- Private NVM(非易失型存储器):用于保存元数据
- Shared NVM(非易失型存储器):用于保存数据
Octopus+ 的架构如上图所示,其中DMS用于保存所有目录的元数据,文件则以哈希的形式分发到所有常规服务器中,数据区导出并被整个集群共享,可以直接进行远程访问,元数据由于一致性原因保持私有。
我们从上图中可以看到创建文件以及向文件中写数据的一些具体流程,创建文件时,首先会访问DMS然后通过RDMA远程直接内存访问的方式借助Collect-Dispatch一致性协议写入服务器中,并会给客户端一个返回结果。
写文件时则会首先从DMS中获取父目录的ID,然后通过哈希计算得到该文件所在的服务器,通过RDMA的方式进行远程直接内存访问的写入,并会更新服务器所在的元数据,做好备份以及一致性等工作,最终返回结果。
Design_High-Throughput Data I/O
引入共享内存池
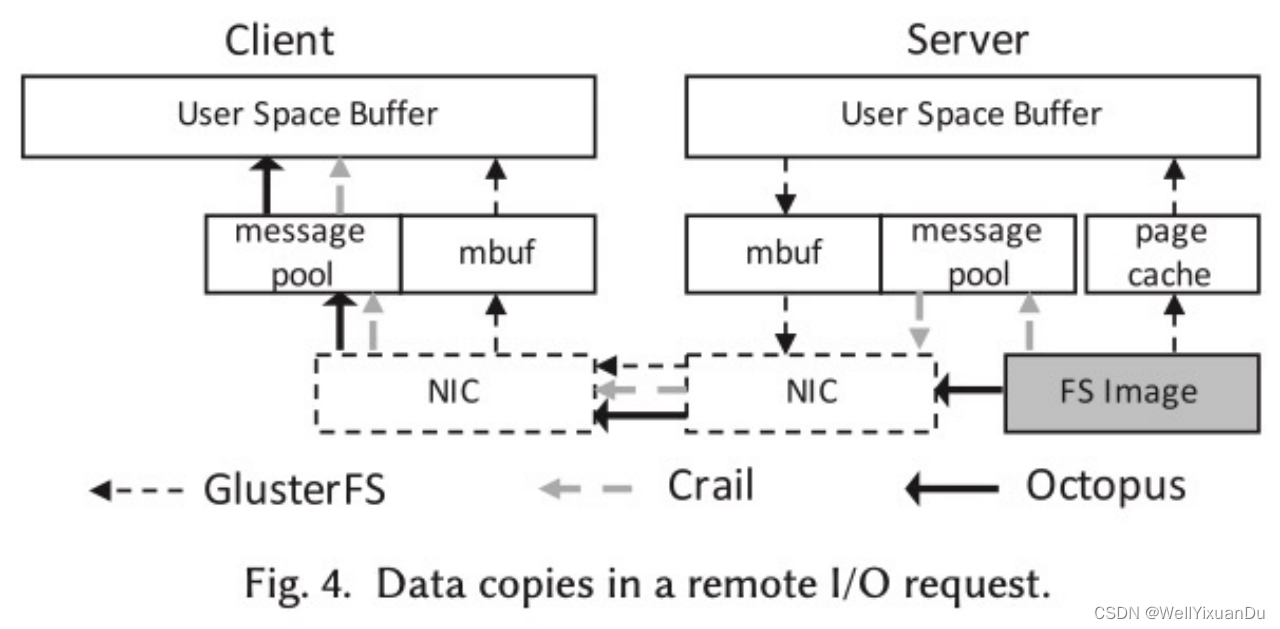
现有的DFS的远程I/O请求共需要7次拷贝,从可持久性存储的镜像中拷贝到当地文件系统的缓存,再从当地文件系统缓存拷贝到用户缓冲区中,进一步通过网络通讯中的mbuf缓存拷贝至网卡中,再以bit的形式在物理介质中传输到客户端的网卡,再经过tcp等网络通信协议拷贝至mbuf最终作为当地文件拷贝到用户空间中。
而文中提到采用的RDMA技术则可以直接远程访问文件系统镜像,只需经过四次拷贝,便完成了这一过程。
客户端主动获取I/O
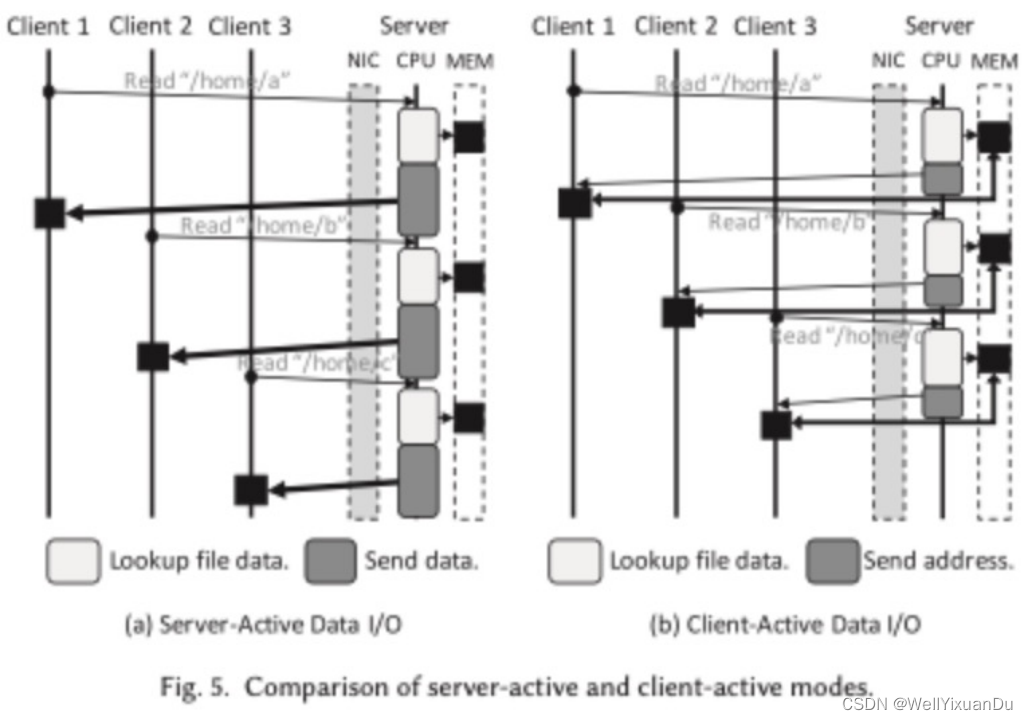
传统的服务器主动I/O如左图所示,客户端向服务器发送请求,服务器收到请求后CPU调度来执行请求,准备数据并送往客户端,使得服务器处于高利用率状态,客户端数量越多,CPU处理的请求就越多,服务器就越受限于CPU。
文中采取的客户端主动I/O则是由客户端向服务器发送读写请求,服务器收到请求后将元数据返回给客户端,客户端利用返回的元数据信息执行读取或写入数据,使用RDMA读写命令直接访问数据而无需远程服务器中的CPU参与。由于随着网络传输的加快,而吞吐量受限于网络和服务器吞吐量之间的较低者,因此采取客户端主动I/O的方式来平衡服务器和网络的开销,提高吞吐量。
Design_Low-Latency Metadata Access
自识别元数据
自识别元数据RPC是使用RDMA的write_with_imm命令来实现的,从名字便可以看出来与write的区别主要是能够携带一个消息字段,用于告知远端客户端的id号以及接收缓冲区的偏移量,另一个不同点则是用来消费服务器端中的一个接收请求,使服务器端能够立即处理。
收集分派事务
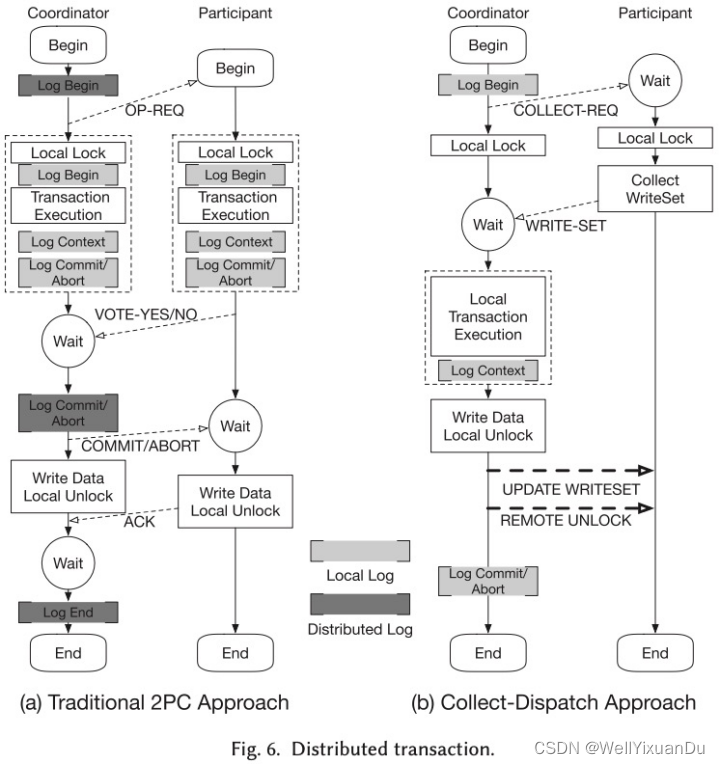
我们常用的两阶段提交协议如左图所示,他一共有prepare以及commit两个阶段,当一个事务发起时,由协调者向各个参与者发送prepare消息,参与者收到prepare消息后将写入日志来进行持久化存储,并执行事务,然后回复给协调者事务能够执行成功,若所有参与者事务均执行成功,协调者将发送commit指令给各个参与者,否则发送abort,各个参与者收到commit/abort后会进行事务的提交或回退,并给协调者发送ack。
可以看出在这个过程中具有参与者的日志持久化以及协调等开销。
文中提出的收集分派事务如右图所示,collect 所有的参与者的read write sets,在协商者中做出对应的更新,之后协商者把最后全部参与者需要commit的 write sets下发下去,这样因为不需要各个参与者的协商,所以过程得到了简化。
从交互中来看,两阶段提交协议需要prepare、以及commit两次RPC延迟,而收集分派事务则需要一次一开始的收集RPC以及一个RDMA write将write sets写入参与者的操作以及一次RDMA原子操作用于解远程的锁,相对而言,延迟更低,且在写入操作时不需要远程CPU处理。
实现
索引机制
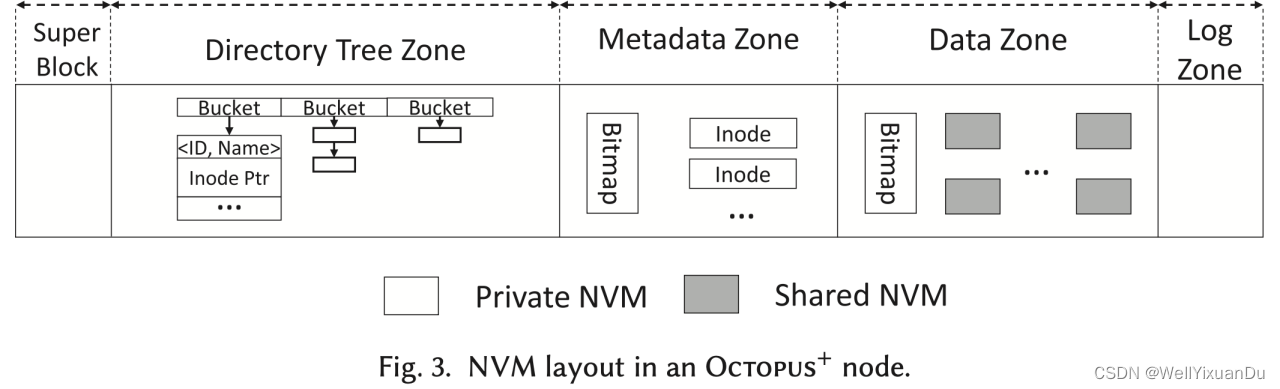
索引机制的实现主要包含目录索引以及数据索引,对于目录索引而言,会存在一个专门的元数据服务器来存放所有目录,每个目录都被分配一个ID,当需要某文件进行操作时,需要先向元数据服务器获取到父ID,并将文件名一起哈希则得到文件所在的服务器,数据服务器内部使用链式哈希表来存放该服务器中的所有目录或文件索引,将上面的key再哈希则得到指向该文件inode。
对于数据索引,每个文件都有一个skip list的实例,该实例中存在许多节点,节点中记录了文件中的偏移量、大小和指向NVM地址字段,可以进行较快的获取数据。
数据可用性
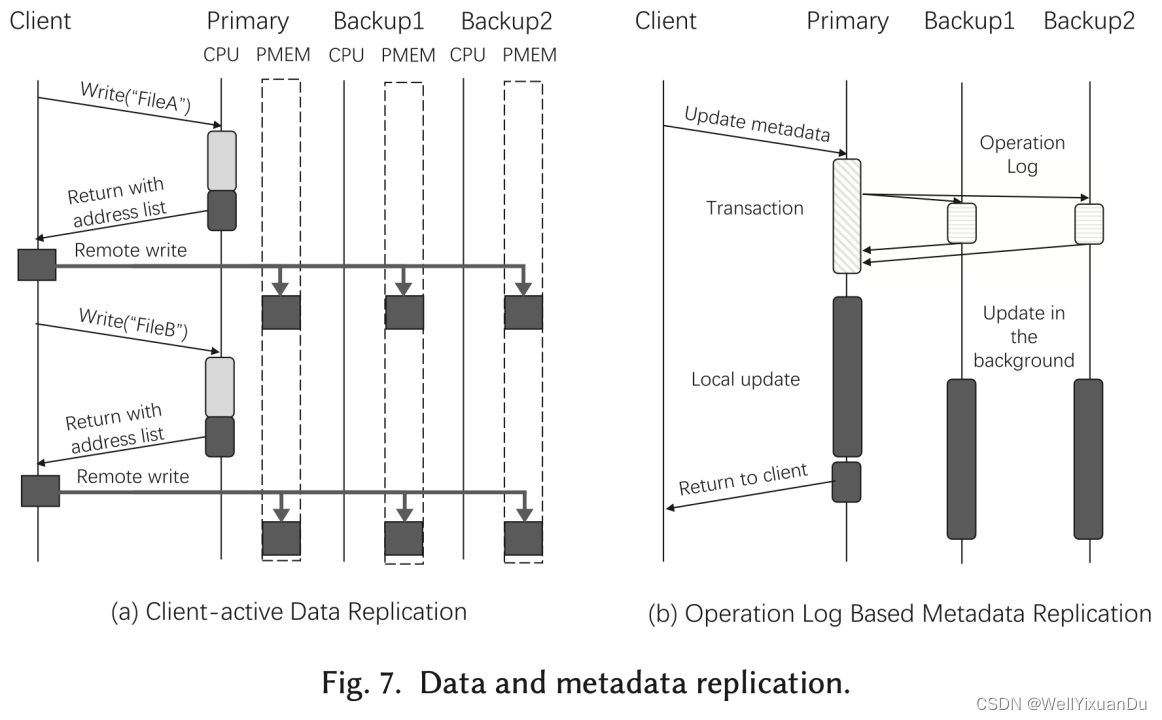
数据可用性主要是通过备份来保证的,对于元数据的复制操作,由于元数据更新频繁,因此在备份时,仅将操作日志发送给备份服务器,备份服务器在后台异步执行操作日志。为了减少时延,采用RDMA write的方式进行操作日志的直接写入。
对于数据复制,则是使用客户端主动I/O,在交互获取到地址后,由客户端直接将数据写入所有副本。
文件系统持久性
文件系统一致性中主要解决了下面2个问题,分别是数据一致性,由于需要将易失型CPU缓存中的数据刷新入持久性内存,但商业的NIC不支持该刷新原语,因此文章中采用在write操作后加入一条额外的RPC来通知远端写入内存的位置及大小。
故障一致性则是主要采用写时复制来更新文件数据所有更新操作都会被重定向至新分配的持久化内存空间中,并以事务的方式来更新元数据来保障原子性。
结语
以上便是我对这篇paper的一些理解,如有不当之处,欢迎指出,一起讨论交流~















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









