






一. SQL递归概念:
简单理解意思,知道干什么用的即可
1、MySQL with Recursive是什么?
MySQL with Recursive是一种基于递归思想的MySQL查询方式,可以实现对数据的递归查询和处理,返回符合条件的数据。在MySQL 8.0版本中,该功能被正式引入。
WITH RECURSIVE 语句包含两部分:
a.递归部分: 定义了如何递归查询数据;
b.终止条件部分: 定义了递归查询何时停止。
别急,后面会详细解释;
2、MySQL with Recursive有什么作用?
MySQL with Recursive的作用是基于一组初始数据,进行递归查询,返回符合条件的数据集。这种递归查询方式可以应用在很多场景下,比如对于树形结构、层级结构的数据处理,以及对数据进行分类汇总等。
3、MySQL with Recursive的使用限制?
MySQL with Recursive的使用限制主要在于查询语句的复杂性和效率。递归查询的复杂度随着层数的增加而增加,如果递归层数过多可能会导致查询效率低下甚至出现死循环的情况。因此,在使用MySQL with Recursive时需要注意数据量大小和递归层数。
二. SQL递归一般形式:
WITH RECURSIVE recursive_query_name (col1, col2, ..., coln) AS (
-- 递归部分
SELECT
initial_query_result_col1,
initial_query_result_col2,
...,
initial_query_result_coln
FROM initial_query
UNION ALL
SELECT
recursive_query_result_col1,
recursive_query_result_col2,
...,
recursive_query_result_coln
FROM recursive_query_name, recursive_query
WHERE recursive_query_condition
)
-- 终止条件部分
SELECT * FROM recursive_query_name ;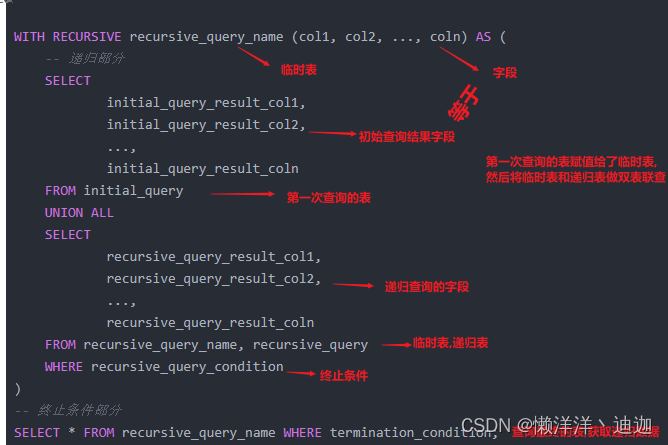
在递归部分,我们先通过一个初始查询(initial_query)得到一些初始的结果。然后我们通过UNION ALL运算将初始结果集合并到递归查询结果中。接下来,在每次递归查询中,我们使用前一次递归的结果(recursive_query_name)与递归查询(recursive_query)进行运算,并使用WHERE条件过滤掉不需要的数据。最后,在终止条件部分中,我们使用一个条件来判断递归查询何时停止。当递归查询到终止条件时,递归查询结束,最终结果被返回
WITH RECURSIVE:
表示要使用递归查询的方式处理数据。
UNION:
表示将两个查询结果集进行联合,使用UNION ALL则表示保留重复数据。
SELECT * FROM 临时表:
表示最终返回的查询结果集,可以通过临时表查询表中的列名进行指定。
如果觉得还迷糊的,不要着急,直接举例子理解,逐步理解才能掌握知识点

这个就是个递归查询的sql;递归查询肯定时指的同一张表;然后是将
SELECT p.* FROM course_category p WHERE p.id = '1' 这个sql结果赋值给t1;然后通过这个初次查询结果的t1表继续去跟course_category联查,符合where条件的再赋值给t1;直至没有符合条件的;最后需要的数据都在t1表里了,只需要查询t1表即可;
这里可以尝试做个案例理解一下;
三.案例:公司部门关系递归查询
a.按DDL建表:
CREATE TABLE company_department (
department_id INT PRIMARY KEY,
department_name VARCHAR(50),
parent_department_id INT REFERENCES company_department(department_id)
);
b.插入数据:
INSERT INTO company_department
(department_id, department_name, parent_department_id)
VALUES
(1, '公司', NULL),
(2, '人力资源部', 1),
(3, '财务部', 1),
(4, '市场部', 1),
(5, '技术部', 1),
(6, '招聘部', 2),
(7, '薪资部', 2),
(8, '成本控制部', 3),
(9, '收支管理部', 3),
(10, '品牌推广部', 4),
(11, '销售部', 4),
(12, '前端开发部', 5),
(13, '后端开发部', 5)c.递归查询公司部门关系SQL语句
WITH RECURSIVE department_tree (department_id, department_name, parent_department_id, depth, path) AS (
SELECT
department_id,
department_name,
parent_department_id,
1 AS depth,
CAST(department_id AS CHAR(200)) AS path
FROM company_department
WHERE parent_department_id IS NULL
UNION ALL
SELECT
cd.department_id,
cd.department_name,
cd.parent_department_id,
dt.depth + 1 AS depth,
CONCAT(dt.path, ',', cd.department_id) AS path
FROM company_department cd
JOIN department_tree dt ON cd.parent_department_id = dt.department_id
)
SELECT
department_id, department_name, parent_department_id, depth, path
FROM department_tree
ORDER BY path;
d.sql案例详解:
这个查询使用了递归公共表达式来遍历公司部门关系。公共表达式使用了两个 SELECT 语句:
第一个 SELECT 语句选取了所有没有父部门的根部门,并将它们添加到临时表
department_tree中。它们的深度被初始化为 1,并且它们的路径被设置为它们的部门 ID。这个 SELECT 语句是递归查询的起点。第二个 SELECT 语句连接了
company_department表和department_tree表。它选取了company_department表中所有具有父部门的部门,并连接到department_tree表中已经存在的部门。对于每个连接的行,它们的深度是父部门的深度加 1,并且它们的路径是父部门的路径加上逗号和它们自己的部门 ID。查询返回了
department_tree表中所有的部门,按照它们的路径排序。这个排序方法使得在结果集中,每个部门都在它们的父部门之后,并且它们的顺序是深度优先遍历的顺序。
e.查询结果截图:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









