







目录
1.Overlay在Cache地址的问题现象
最近有朋友在验证英飞凌TC3xx的Overlay功能时,出现了如下问题:
0x80280000重映射到到0xB0040000,定义一个变量在0x80280000,用a去读,开启Overlay功能之后,理论上来说修改0xB0040000的值,a读到的就是新值,结果a读到的还是原来的值,把cache关掉就正常了。
这里首先反应肯定是Cache数据一致性问题,但是直觉告诉我没有这么简单。再仔细阅读题干并结合手册可以发现:
- 8H开头的PFlash为Cachable的地址
- B0040000对应Non-Cache的LMU



问题来了,既然Overlay映射到了Non-Cache的LMU0,那CPU为什么不直接到LMU去读数据?反而还是以前Cache里的数据呢?
带着这个问题,我们梳理一下Tricore的Memory模型,理清思路后发现问题很简单,但加深了对Tricore的认识。
2. TC1.6.2P的Local Memory
2.1 Local Memory分类
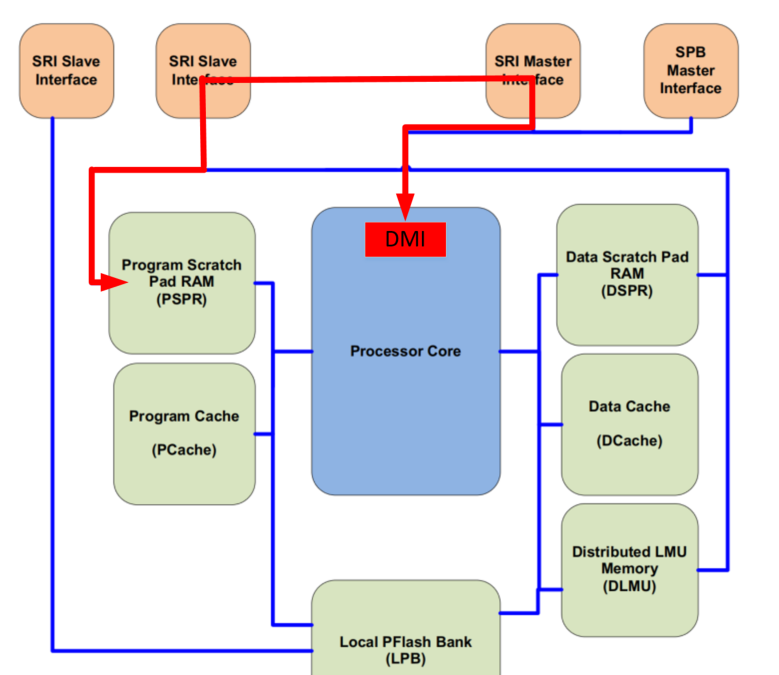
根据UserMannul里的描述,TC1.6的本地memory模型如下:
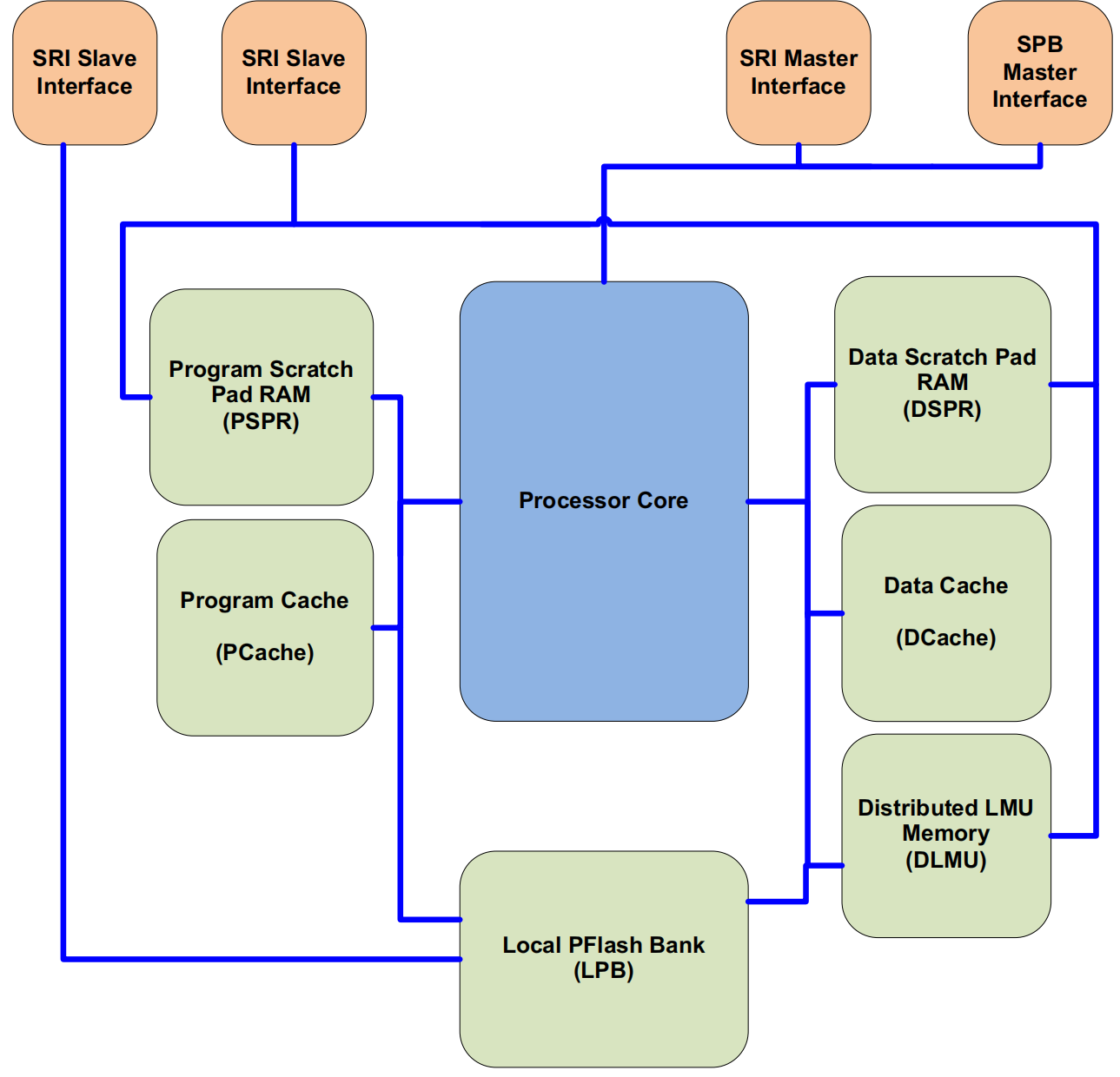
其中包含了:
- PSPR:Program Scratchpad SRAM,为性能需求的代码提供快速、具有确定CPU访问周期的RAM,其特点是存在PSPR的程序是CPU直接取指,不会被Cache;
- DSPR:Data Scratchpad SRAM,顾名思义,为数据访问提供高速的RAM
- PCache:Program Cache,2路组相连的程序Cache
- DCache:Data Cache,2路组相连的数据Cache
- DLMU:Distributed LMU memory
- LPB:Local PFlash Bank ,本地CPU与目标Flash的直连接口
以TC39x为例,我们可以通过其框图看到memory层级:
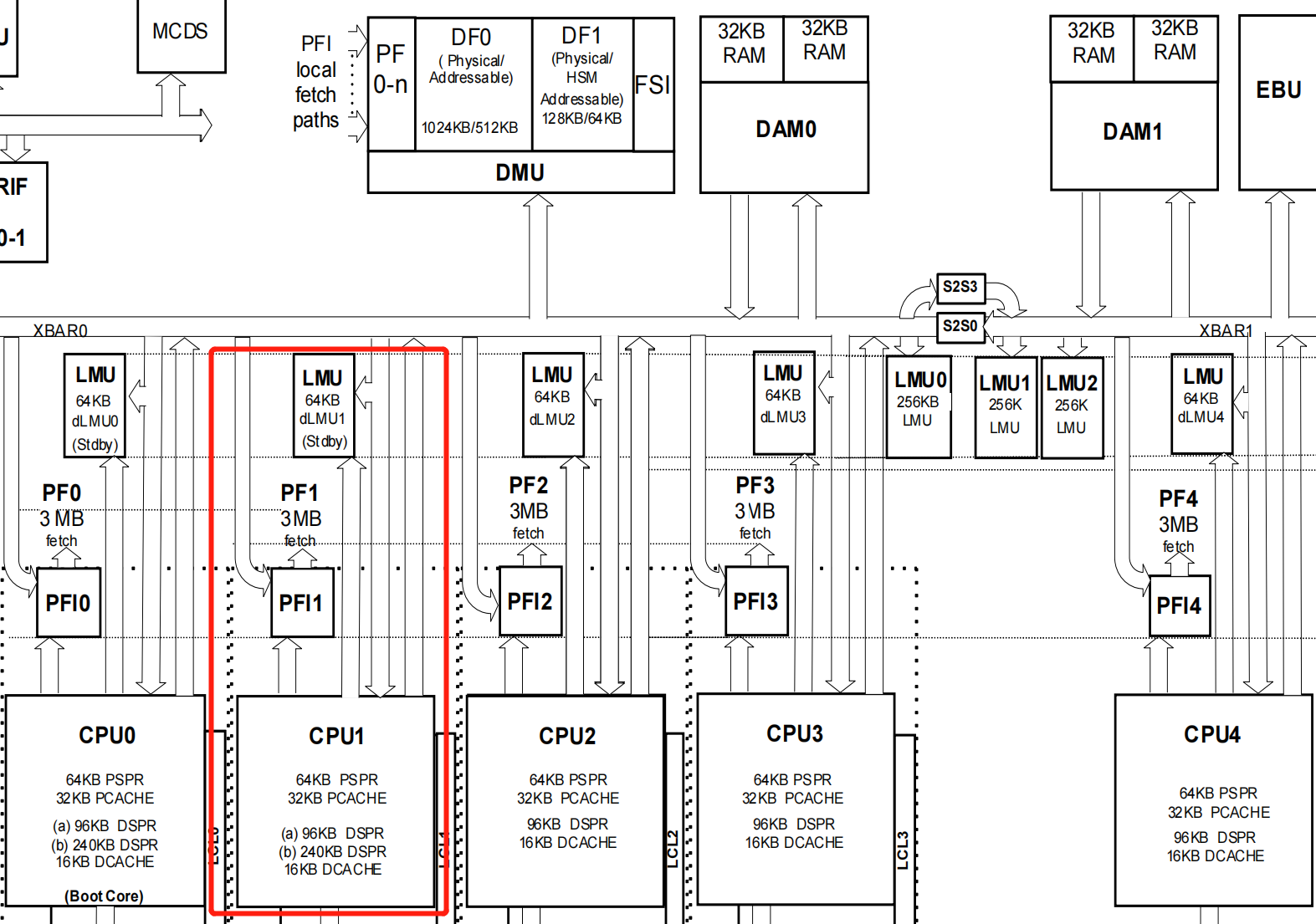
其中,CPU访问PSPR、PCACHE、DSPR、DCACHE的速度最快,其次是DLMU、PFI,最后是LMU。Cycle数据总结如下:
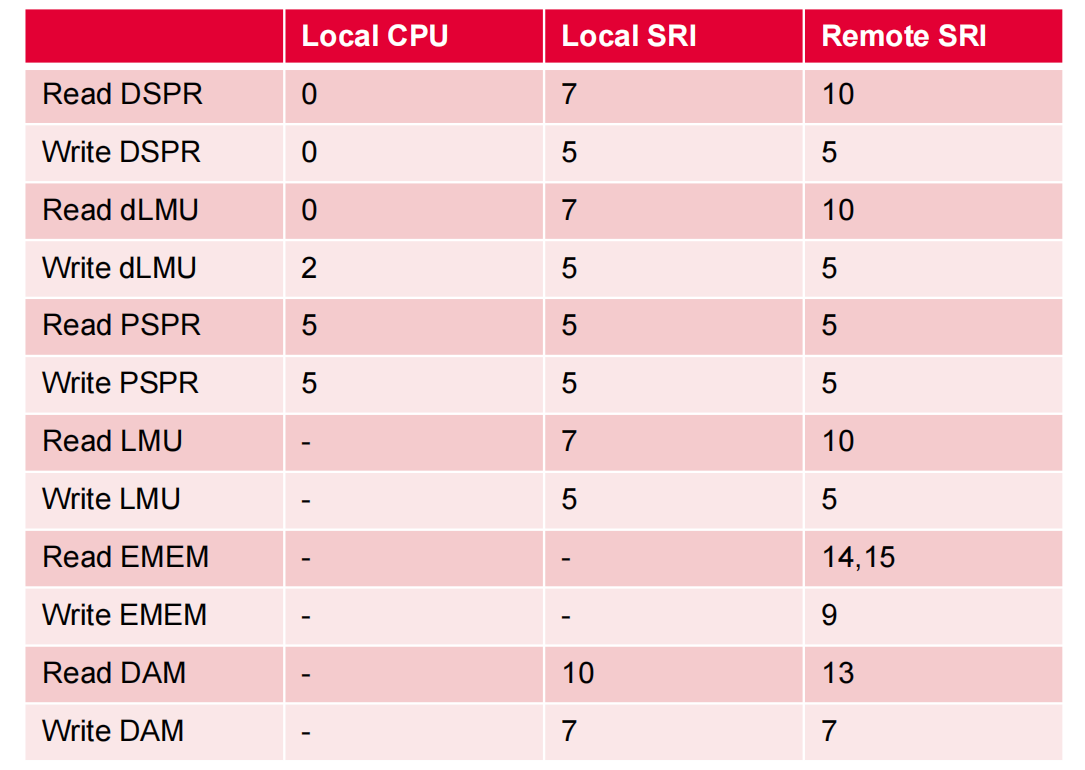
这里临时有个想法,如果把Data放到PSPR里,其性能如何呢?要解决这个问题,先得搞清楚CPU的Memory接口类型。
2.2 PMI和DMI
TC1.6的CPU模型如下:
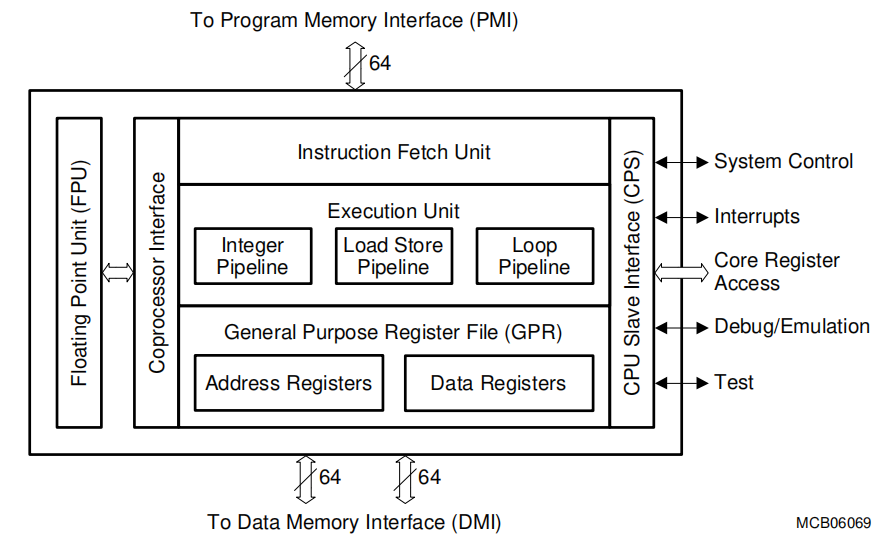
它由IFU(Instruction Fetch Unit)、EU(Execution Unit)、GRP构造,其中指令访问使用PMI接口、数据访问使用DMI接口。
PMI:Program Memory Interface向CPU提供指令流
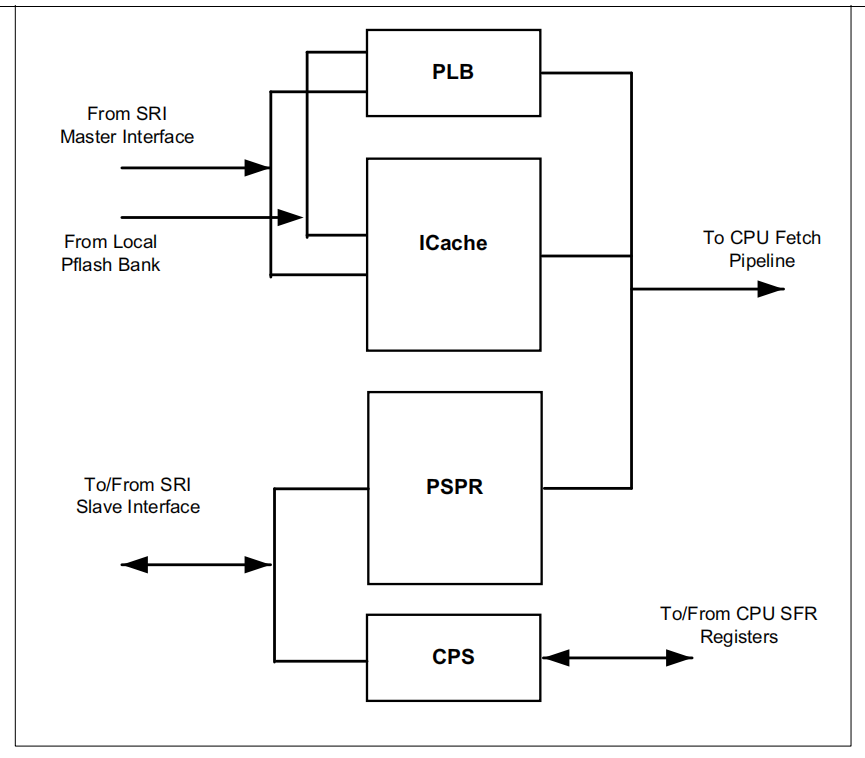
其中,比较特别的是PLB,一个256bits Program Line Buffer。当使用Non-Cacheable地址时时,为加快速度,PLB可作为单个Cache Line使用。同时注意,上半部分PMI与SRI Master和LPB(PFI)接口是一个单向只读接口,而对于下半部分PSPR、CPS是一个双向接口。
DMI:Data Memory Interface向CPU提供数据或者存储由CPU发送的数据,其框图如下:
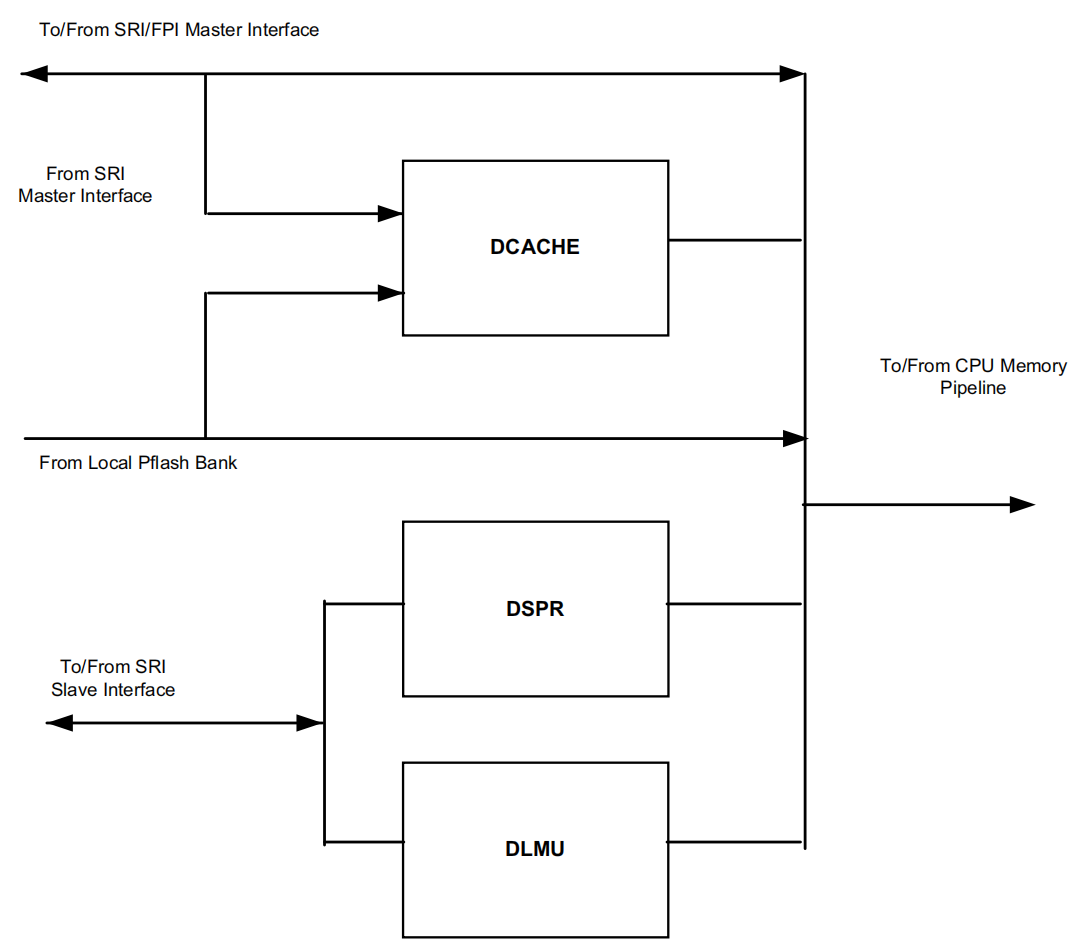
可以看到,在DMI里没有与PSPR的直接接口,因此,回到临时问题:如果把数据放到PSPR里,CPU去访问数据时使用DMI,那么走的路线应该就与SRI总线有关,如下图:
3.问题分析
回到正题,8H(Cacheable)的PFlash 重映射到BH(Non-Cacheable)的LMU区域时,为什么会出现Cache数据一致性问题?
首先明确Overlay全称叫做Data Access Overlay,针对的是数据访问,意味着地址翻译过程应该由DMI这个接口来实现。
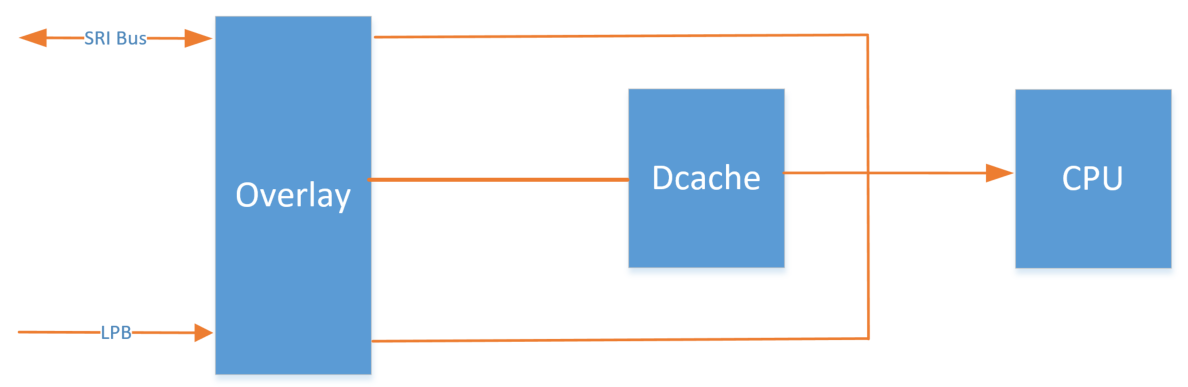
正常情况下,我们获取Cacheable PFlash(8H)里的数据,应该走如下路径:
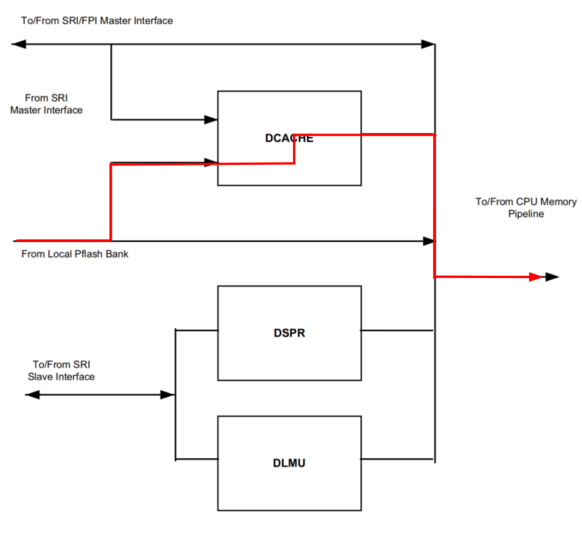
如果Cache命中,就不要到memory去拿数据了,提高了访问速度;
修改Noncache LMU里的数据,走如下紫色路径:
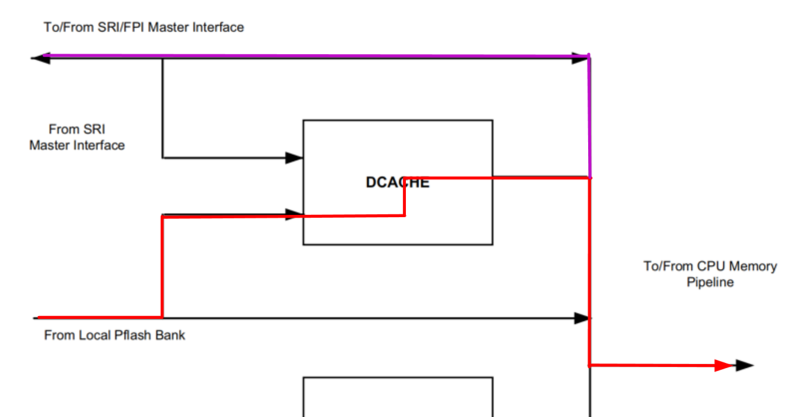
现在出现DCache数据不一致现象,说明CPU通过DMI去获取数据时,首先取得的是Dache里的数据, 那能不能得出结论,Overlay的地址翻译是在如下位置实现的呢?
理由如下:当我直接修改Non-Cache LMU里数据的值时,走路线1 :
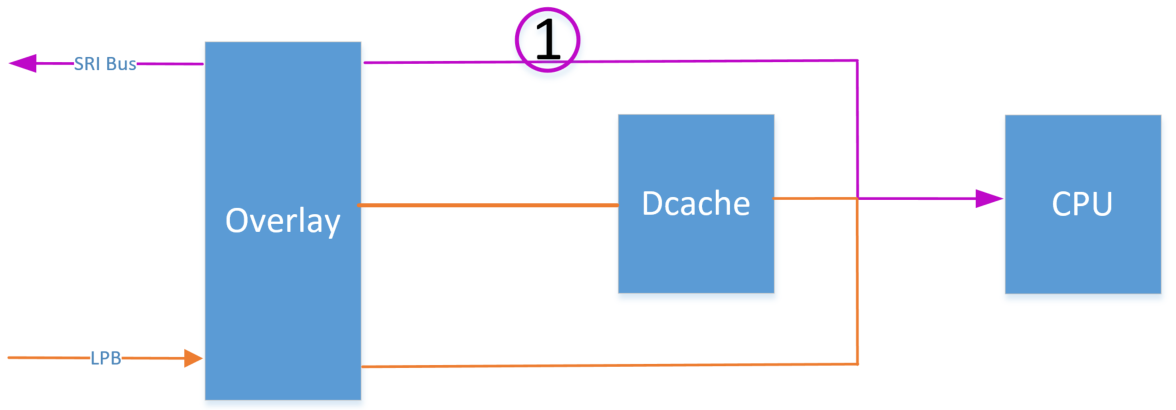
值得注意的是,因为使用的Non-Cache的地址,所以直接到LMU里,在没有使用DSYNC指令时,数据不会同步到DCache中;
验证Overlay功能时,肯定是使用Flash地址去获取修改后(Ram)的数据(Flash 映射到 RAM),走路线2:
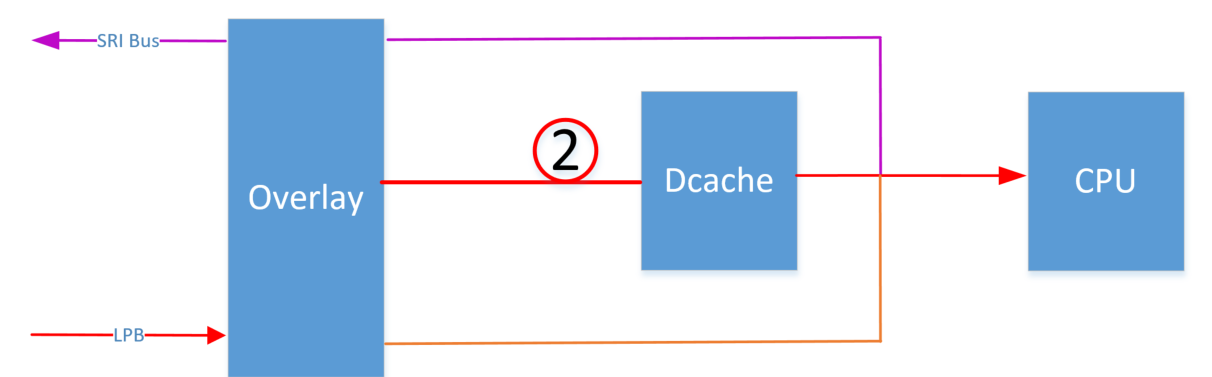
开启Overlay后,CPU最开始使用的地址肯定是Flash的地址,例如0x80280000;由于该地址Cacheable,因此首先到DCache里找数据,一旦Cache Hit,那使用的就是老的数据。
怎么解决这个问题呢?直接到目标地址去拿数据是最稳妥的。
如下图路线3:
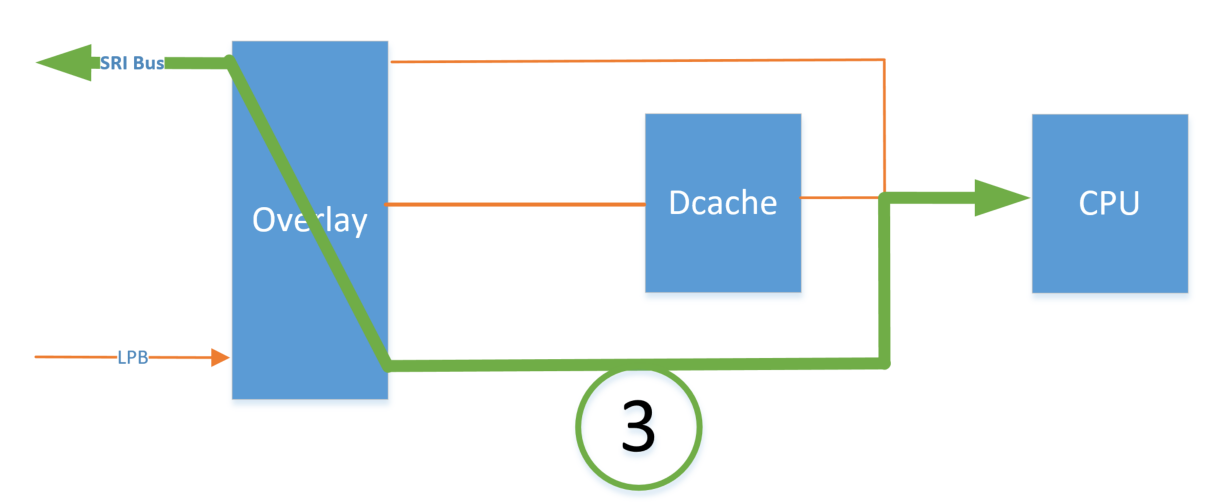
按这种思路,可以有如下解决方案:
1)使用Non-cache地址来实现Overlay;
2)如果必须要求使用Cache地址,也好办。
在OVCCON寄存器里提供了DCache清除机制,如下图:
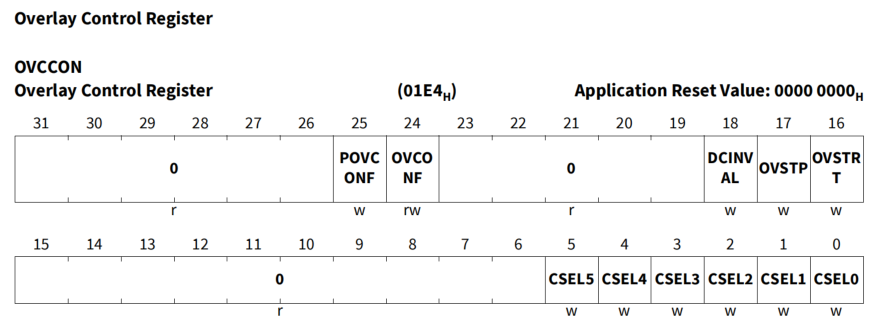
 每次读数据之前清下DMI里的Cache Line,每次写数据时同步一下(Write Back Cache)。
每次读数据之前清下DMI里的Cache Line,每次写数据时同步一下(Write Back Cache)。
4.小结
由于Cache对软件开发者的透明性,在涉及到这个问题时,最好还是使用Non-Cache地址。虽然这会损失一些性能,但对于常见的标定场景基本是够用了。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











