






 文章介绍了Brandes算法在计算网络中介中心性中的高效性,与Floyd-Warshall和Dijkstra算法的比较,以及如何在Java中实现,包括节点最短路径之和的计算。
文章介绍了Brandes算法在计算网络中介中心性中的高效性,与Floyd-Warshall和Dijkstra算法的比较,以及如何在Java中实现,包括节点最短路径之和的计算。
一、Brandes算法
Brandes算法是一种经典的计算中介中心性的算法,它通过计算节点对之间的最短路径数量来评估节点的中介中心性。在复杂网络分析中,中介中心性是一种常用的指标,用于衡量节点在网络中的重要性程度。中介中心性越高的节点往往具有更大的影响力,可能成为信息传播、资源流动的关键节点。

Brandes算法的时间复杂度在最坏情况下是O(nm),其中n代表图中的节点数,m代表图中的边数。这是因为算法需要对每一个节点执行一次广度优先搜索(BFS),并在搜索过程中统计σ值和δ值,这一步骤的时间复杂度为O(m),之后还需要回溯计算中介中心性,对于每个节点来说时间复杂度大致也是线性的。因此,总的时间复杂度较高,但Brandes算法仍然是求解中介中心性问题的一个高效解决方案,尤其是在稀疏图中表现良好。
对于特定类型或者特别构造的图结构,可能存在更优的算法,但在一般情况下的无向图上计算中介中心性时,相对于以下几种主流的算法,Brandes算法是一个实用且被广泛接受的方法。
-
Floyd-Warshall 算法:Floyd-Warshall算法可以计算任意两点之间的最短路径,时间复杂度为O(n^3),适合于较小规模的完全图或者需要得到任意两点间最短路径的场景。在仅计算中介中心性的情况下,Brandes算法更高效,因为它利用了单源最短路径的特性。
-
Dijkstra算法:Dijkstra算法可以找到从一个起点到所有其他点的最短路径,时间复杂度为O(m + n log n)(假设使用优先队列优化)。对于计算所有节点的中介中心性,需要对每个节点作为起点运行Dijkstra算法,总的时间复杂度将会更高。而Brandes算法则一次性完成所有节点的最短路径统计,因此在特定场景下更有优势。
-
Naive实现:若采用一种简单的遍历计算方法,比如每次针对每个节点对重新计算最短路径,那么这种方法的时间复杂度将会非常高,远高于Brandes算法。
Brandes算法在计算节点中介中心性问题上相对其他通用最短路径算法有显著的时间效率优势,尤其当关注的是整体网络结构的中介性分析时。然而,如果网络规模极大或内存资源有限,Brandes算法的空间复杂度可能会成为瓶颈,这时可能需要进一步优化或采用分布式计算框架。
二、节点最短距离
在社交网络分析、复杂网络研究以及许多其他领域中,评估节点在网络中的重要程度是一项核心任务。其中一种方式,衡量某个节点到其他节点的最短路径之和,值越小,说明该节点越接近于其他节点,就越靠近图的中心位置,它可以帮助我们了解节点在网络中的重要性程度。
这是示例数组:
{
"nodes":[
{"id":"3.1"},
{"id":"4.1"},
{"id":"4.4"},
{"id":"2.3"},
{"id":"1.1"},
{"id":"1.2"}
],
"edges": [
{
"id":"e1",
"source": "3.1",
"target": "4.1"
},
{
"id":"e2",
"source": "4.4",
"target": "4.1"
},
{
"id":"e3",
"source": "3.1",
"target": "4.4"
},
{
"id":"e4",
"source": "4.1",
"target": "2.3"
},
{
"id":"e5",
"source": "4.4",
"target": "1.1"
},
{
"id":"e6",
"source": "1.2",
"target": "1.1"
}
]
}
这是示例数组对应的无向图:
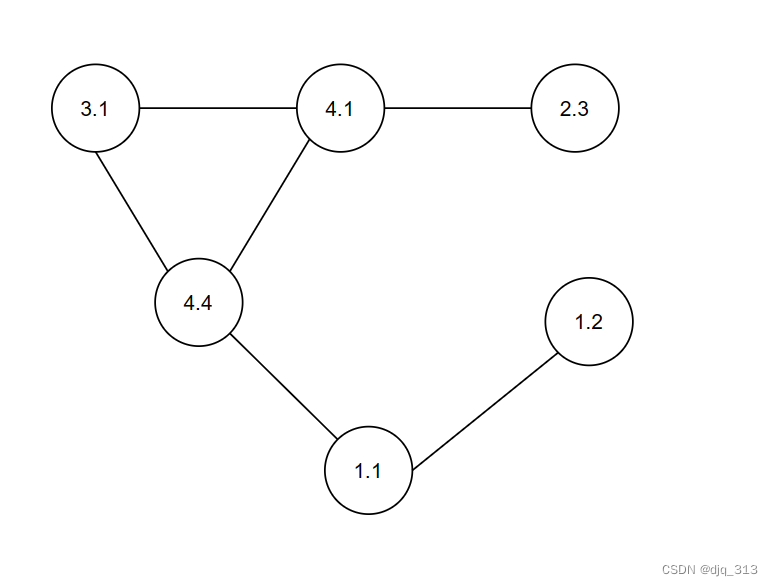
我们假设上图中每个节点间的距离均为“1”,如下图所示,例如,我们选取节点“3.1”计算其到其他节点最短路径之和:

“3.1”到“4.1”和“4.4”距离均为“1”,“3.1”到“1.1”和“2.3”距离均为“2”,“3.1”到“1.2”距离为“3”
那么,节点“3.1”计算其到其他节点最短路径之和为:1+1+2+2+3=9
同理,我们可以计算出其他节点的相应的最短路径之和。
三、Java代码实现
利用Brandes算法,我们能够在无向图中更轻松地计算出每个节点到其他节点最短路径之和。
以下是Java代码:
// 导入必要的库,用于处理JSON数据及集合操作
import org.json.JSONArray;
import org.json.JSONObject;
import java.util.*;
public class Main {
public static void main(String[] args) {
// 获取JSON对象,该对象包含了图的节点和边信息
JSONObject graphJson = getJsonObject();
// 创建邻接表表示图结构,键为节点ID,值为连接到该节点的所有节点ID列表
Map<String, List<String>> adjacencyList = new HashMap<>();
// 创建一个HashSet存储所有节点ID
Set<String> nodesSet = new HashSet<>();
// 解析JSON对象中的"nodes"数组,获取所有节点ID并添加到nodesSet中
JSONArray nodesArray = graphJson.getJSONArray("nodes");
for (int i = 0; i < nodesArray.length(); i++) {
JSONObject nodeObj = nodesArray.getJSONObject(i);
String nodeId = nodeObj.getString("id");
nodesSet.add(nodeId);
}
// 解析JSON对象中的"edges"数组,构建邻接表
JSONArray edgesArray = graphJson.getJSONArray("edges");
for (int i = 0; i < edgesArray.length(); i++) {
JSONObject edgeObj = edgesArray.getJSONObject(i);
String source = edgeObj.getString("source");
String target = edgeObj.getString("target");
// 假设图是无向的,所以在邻接表中双向添加边
adjacencyList.computeIfAbsent(source, k -> new ArrayList<>()).add(target);
adjacencyList.computeIfAbsent(target, k -> new ArrayList<>()).add(source);
}
// 计算并存储每个节点的中介中心性
Map<String, Double> nodeCentralities = new HashMap<>();
for (String nodeId : nodesSet) {
double centrality = calculateBetweennessCentrality(adjacencyList, nodeId);
nodeCentralities.put(nodeId, centrality);
}
// 将节点按照其中介中心性降序排列
List<Map.Entry<String, Double>> sortedNodes = new ArrayList<>(nodeCentralities.entrySet());
sortedNodes.sort(Map.Entry.comparingByValue(Comparator.reverseOrder()));
// 输出每个节点及其对应的中介中心性
System.out.println("节点:该节点到其他节点最短路径距离之和:");
for (Map.Entry<String, Double> entry : sortedNodes) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
// 从固定JSON字符串中创建并返回JSONObject
private static JSONObject getJsonObject() {
String jsonData = "{\"nodes\":[\n" +
"{\"id\":\"3.1\"},\n" +
"{\"id\":\"4.1\"},\n" +
"{\"id\":\"4.4\"},\n" +
"{\"id\":\"2.3\"},\n" +
"{\"id\":\"1.1\"},\n" +
"{\"id\":\"1.2\"}\n" +
"],\n" +
"\"edges\": [\n" +
" {\n" +
" \"id\":\"e1\",\n" +
" \"source\": \"3.1\",\n" +
" \"target\": \"4.1\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e2\",\n" +
" \"source\": \"4.4\",\n" +
" \"target\": \"4.1\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e3\",\n" +
" \"source\": \"3.1\",\n" +
" \"target\": \"4.4\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e4\",\n" +
" \"source\": \"4.1\",\n" +
" \"target\": \"2.3\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e5\",\n" +
" \"source\": \"4.4\",\n" +
" \"target\": \"1.1\"\n" +
" },\n" +
" {\n" +
" \"id\":\"e6\",\n" +
" \"source\": \"1.2\",\n" +
" \"target\": \"1.1\"\n" +
" }\n" +
" ]\n}";
JSONObject graphJson = new JSONObject(jsonData);
return graphJson;
}
// 根据给定的邻接表和节点ID,计算该节点的中介中心性
private static double calculateBetweennessCentrality(Map<String, List<String>> graph, String node) {
// 初始化用于计算中介中心性的三个HashMap
Map<String, Integer> sigma = new HashMap<>();
Map<String, Double> delta = new HashMap<>();
Map<String, Double> betweenness = new HashMap<>();
// 初始化所有节点的sigma、delta和betweenness值
for (String v : graph.keySet()) {
sigma.put(v, 0);
delta.put(v, 0.0);
betweenness.put(v, 0.0);
}
// 设置当前节点的sigma值为1
sigma.put(node, 1);
// 创建队列(BFS)和栈(用于回溯),以及预处理器列表和距离映射表
Queue<String> queue = new LinkedList<>();
Stack<String> stack = new Stack<>();
Map<String, List<String>> predecessors = new HashMap<>();
Map<String, Integer> distances = new HashMap<>();
// 初始化所有节点的预处理器列表和距离值
for (String v : graph.keySet()) {
predecessors.put(v, new ArrayList<>());
distances.put(v, -1);
}
// 将当前节点加入队列,并设置距离为0
queue.offer(node);
distances.put(node, 0);
// 开始广度优先搜索(BFS)
while (!queue.isEmpty()) {
String v = queue.poll();
stack.push(v);
// 遍历当前节点的所有邻居节点
for (String w : graph.get(v)) {
// 如果邻居节点尚未访问过,则将其加入队列,并更新距离
if (distances.get(w) < 0) {
queue.offer(w);
distances.put(w, distances.get(v) + 1);
}
// 当前邻居节点与当前节点的距离等于二者直接相连的距离时,更新sigma值和预处理器列表
if (distances.get(w) == distances.get(v) + 1) {
sigma.put(w, sigma.get(w) + sigma.get(v));
predecessors.get(w).add(v);
}
}
}
// 回溯过程,计算中介中心性
while (!stack.isEmpty()) {
String w = stack.pop();
for (String v : predecessors.get(w)) {
double c = (double) sigma.get(v) / sigma.get(w) * (1.0 + delta.get(w));
delta.put(v, delta.get(v) + c);
betweenness.put(w, betweenness.get(w) + c);
}
}
// 计算给定节点对整个图中介中心性的贡献
double centrality = 0.0;
for (String v : graph.keySet()) {
if (!v.equals(node)) {
centrality += betweenness.get(v);
}
}
// 返回该节点的中介中心性
return centrality;
}
}运行结果:

可以看到,节点“4.4”到其他节点的最短路径之和的值最小,因此,我们可以认为节点“4.4”就是示例图的中心节点。
















 3528
3528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









