







前言
ClickHouse广泛用于用户和系统日志查询场景中,主要针对于OLAP场景,为业务方提供稳定高效的查询服务。在业务场景下,数据以不同的格式、途径写入到clickhouse。用传统JOIN方式查询海量数据,通常有如下痛点:
-
每个查询的代码冗长,有的长达1500行、2000行sql,使用和理解上特别痛苦
-
性能上无法满足业务诉求,数据量大会内存不足;
-
事实表就一张,可是维度表却有多张,关联数据量暴增
-
重复计算
如何将这些数据进行整合,以类似ClickHouse宽表的方式呈现给上层使用,用户可以在一张表中查到所需的所有指标,避免提供多表带来的代码复杂度和性能开销问题?
这里将重点介绍如何通过物化视图有效解决上述场景问题。在介绍之前,先看一下什么是物化视图,以及如何创建、使用,如何增加维度和指标,结合字典增维等场景。
原理篇
传统视图
说到物化视图,我们不得不说下传统的视图;这里拿Oracle视图举例,我们看下Oracle视图的创建语句
CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW view_name [(column1[,column2,....])]
AS select_statement [WITH CHECK OPTION CONSTRAINT constraint];参数含义
-
OR REPLACE:如果视图已经存在,则替换已有的视图;
-
FORCE|NOFORCE:指定是否强制执行;如果定义了一个基于其他存在的对象的视图,则应该使用 FORCE,防止出现错误;
-
view_name:视图的名称;
-
column1:定义视图中的列名称;
-
select_statement:SELECT 语句用于生成视图的数据;
-
WITH CHECK OPTION:在插入或更新视图数据时,检查其是否满足视图定义的限制条件;
-
CONSTRAINT constraint:定义在视图插入或更新数据时强制执行的约束条件。
查询原理
-
在Oracle中,视图不存储任何数据。当我们查询视图时,Oracle会根据视图的定义,将其视为一个虚拟表,并执行查询语句,最后将查询结果返回给用户。
-
创建一个Oracle视图时,Oracle会解析视图定义的SQL语句,并将其存储在数据字典中
-
Oracle中视图的查询并不会每次都重新解析SQL语句,而是在第一次查询时进行解析,构建优化计划,并将该解析结果进行缓存,以便后续查询时直接使用。这个缓存被称为视图的“解析树”。
-
当视图被查询时,优化器会直接使用缓存中的解析树来执行查询。这种做法不仅可以避免重复解析SQL语句带来的性能开销,还可以提高查询效率。
-
需要注意的是,当所有基表或相关对象的结构发生更改时(如:DDL语句、DML语句),Oracle会自动标记所有依赖于这些对象(如视图、存储过程、函数、触发器)的视图为“无效”,意味着必须在下一次查询这些视图时重新解析视图的定义。这种情况下,Oracle也会自动重建视图的解析树,以应对结构更改的情况。
-
为了提高性能,可以在设计视图时尽量避免使用过于复杂的查询,同时避免频繁更改相关对象的结构。
查询步骤
Oracle在执行视图查询时,会进行以下步骤:
-
解析SQL语句:当用户提交一个SQL查询语句时,Oracle首先会解析该语句,分析其语法和语义,生成一个相应的查询语句组合。如果SQL语句中包含视图,则Oracle会先将视图的定义转换成与其等效的查询语句。
-
优化查询计划:Oracle会对查询语句进行优化分析,使用一个基于成本优化的查询优化器来找到最有效的查询计划。优化器会根据数据库统计信息、操作系统资源和查询参数等因素,选择最佳的查询计划来执行查询。
-
执行查询计划:Oracle会使用执行计划中最佳的方法来执行查询,其方式可能包括扫描、聚合、连接、排序、过滤等等。对于视图,Oracle实际上会将其视为一个包含所有相关表的复合查询,然后执行与之等效的查询计划,最终将结果返回给用户。
优化策略
需要注意的是,Oracle在查询视图时,并非总是将视图整体扫描一遍,而是使用一定的优化策略来最小化查询开销,这些优化策略可以使对视图的查询更加高效、快速。包括:
-
视图合并:当视图之间存在共享的查询条件时,Oracle会将它们合并为一个更简单的查询语句,以减少物理读取。
-
列剪切:Oracle会根据需要查询的列来选择需要读取的列,以减少物理读取。
-
子查询优化:对于包含子查询的视图,Oracle会尽可能地将子查询移动到主查询中,以减少物理读取。
物化视图
CREATE MATERIALIZED VIEW
[IF NOT EXISTS] [db.]table_name
[ON CLUSTER] [TO[db].[table]] [ENGINE = engine] [POPULATE]
AS SELECT ...参数含义:
-
view_name是物化视图的名称
-
engine_name是指定该视图使用的存储引擎
-
settings是可选的引擎设置参数
-
POPULATE/NO POPULATE用于指定是否需要对物化视图进行初始化
-
SELECT...语句用于指定物化视图查询的数据来源
创建方式
-
隐式创建目标表
-
创建不带[[db].[table]]的物化视图时,必须指定ENGINE。
-
-- 创建本地表 CREATE TABLE download ( when DateTime, userid UInt32, bytes Float32 ) ENGINE=MergeTree PARTITION BY toYYYYMM(when) ORDER BY (userid, when); -- 往本地表插入数据 INSERT INTO download SELECT now() + number * 60 as when, 25, rand() % 100000000 FROM system.numbers LIMIT 5000; -- 创建物化视图 CREATE MATERIALIZED VIEW download_daily_mv ENGINE = SummingMergeTree -- 指定engine PARTITION BY toYYYYMM(day) ORDER BY (userid, day) POPULATE AS SELECT toStartOfDay(when) AS day, userid, count() as downloads, sum(bytes) AS bytes FROM download GROUP BY userid, day -- 查询物化视图 SELECT * FROM download_daily_mv -- inner.download_daily_mv ORDER BY day, userid LIMIT 5 SELECT toStartOfMonth(day) AS month, userid, sum(downloads), sum(bytes) FROM download_daily_mv GROUP BY userid, month WITH TOTALS ORDER BY userid, month
-
-
显示创建目标表
-
使用[[db].[table]]的物化视图时,官方推荐不使用POPULTE
-
若使用POPULATE,会将现有的数据插入到表中
-
不使用POPULATE,查询仅包含创建视图后插入表中的数据
-
不推荐使用理由:官方说明是因为在创建视图期间插入表中的数据不会插入其中
-
对于实际业务场景来说,历史数据不可少,可以通过查询条件方式进行数据同步
-
--明细表 CREATE TABLE counter ( when DateTime DEFAULT now(), device UInt32, value Float32 ) ENGINE=MergeTree PARTITION BY toYYYYMM(when) ORDER BY (device, when) --插入模拟数据 INSERT INTO counter SELECT toDateTime('2023-06-19 00:00:00') + toInt64(number/10) AS when, (number % 10) + 1 AS device, (device * 3) + (number/10000) + (rand() % 53) * 0.1 AS value FROM system.numbers LIMIT 1000000 --目标表(统计表) CREATE TABLE counter_daily ( day DateTime, device UInt32, count UInt64, max_value_state AggregateFunction(max, Float32), min_value_state AggregateFunction(min, Float32), avg_value_state AggregateFunction(avg, Float32) ) ENGINE = SummingMergeTree() PARTITION BY tuple() ORDER BY (device, day) --创建视图,注意通过条件解决新旧数据 CREATE MATERIALIZED VIEW counter_daily_mv TO counter_daily -- 无须指定engine,跟表engine一致 AS SELECT toStartOfDay(when) as day, device, count(*) as count, maxState(value) AS max_value_state, minState(value) AS min_value_state, avgState(value) AS avg_value_state FROM counter WHERE when >= toDate('2023-06-19 00:00:00') GROUP BY device, day ORDER BY device, day --视图创建后,插入新数据 INSERT INTO counter SELECT toDateTime('2023-06-19 00:00:00') + toInt64(number/10) AS when, (number % 10) + 1 AS device, (device * 3) + (number / 10000) + (rand() % 53) * 0.1 AS value FROM system.numbers LIMIT 1000000 --视图创建后,插入历史数据 INSERT INTO counter_daily SELECT toStartOfDay(when) as day, device, count(*) AS count, maxState(value) AS max_value_state, minState(value) AS min_value_state, avgState(value) AS avg_value_state FROM counter WHERE when < toDateTime('2023-06-19 00:00:00') GROUP BY device, day ORDER BY device, day --查询数据(查询目标表与查询物化视图是一样的) SELECT device, sum(count) AS count, maxMerge(max_value_state) AS max, minMerge(min_value_state) AS min, avgMerge(avg_value_state) AS avg FROM counter_daily GROUP BY device ORDER BY device ASC show tables; ┌─name───────────────────────────────────────────┬ │ .inner_id.3ab83499-b168-4ce4-98e0-28c1708ef22c │ │ counter │ │ counter_daily │ │ counter_daily_mv │ │ download │ │ download_daily_mv │ └────────────────────────────────────────────────┴
-
-
为什么要目标表
-
根据官网解释:Create the source table, because our goals involve reporting on the aggregated data and not the individual rows, we can parse it, pass the information on to the Materialized Views, and discard the actual incoming data.
-
换言之就是:创建源表的目标是报告聚合数据,而不是单个行,这样可以解析它,将信息传递给物化视图,并丢弃实际传入的数据
-
-
保留重复计算结果:物化视图的查询可能会涉及到很耗时的计算,例如在大型数据集上进行组合、聚合、过滤等操作。但是,上述这样的查询结果通常会长时间保持不变,所以将查询结果存储在物化视图中(也就是目标表),以便在后续查询中快速访问,可以大大提高查询性能。
-
这点跟Oracle的视图不同,Oracle视图基于解析树一次解析多次运行提升查询效率;而clickhouse的物化视图基于查询预计算的结果提升查询性能,这也就是为什么clickhouse的物化视图需要指定目标表的原因之一
-
-
-
隐式表和显示表的区别
-
隐式表:
-
隐式表是一个虚拟的表,它不需要预先创建,而是会在物化视图被查询时自动创建,并存储物化视图的计算结果。
-
隐式表的优势在于它能够减少预先创建目标表的工作量并且可以自动清理。避免写错聚合函数类型带来数据上的写入失败
-
隐式表的缺点在于,alter有局限性,每次更改都需要替换或者修改物化视图的计算逻辑。
-
-
显示表
-
显式表是指在创建物化视图时手动创建的目标表,该表需要事先存在,而且需要和物化视图使用相同的数据存储引擎。
-
显式表创建的物化视图可以提供更高的灵活性,可以在创建表时指定一些特殊的属性,如数据压缩方式、数据分区等等。
-
另外,显式表还可以在创建物化视图时一起进行维护和备份,有助于提升数据一致性和可靠性。
-
但是,需要注意显式表的缺陷在于维护方面需要占用更多的存储空间,也需要手动清理和备份数据。
-
-
结果对比
使用源表
查询语句
SELECT
device,
sum(count) As count,
maxMerge(max_value_state)AS max,
minMerge(min value state)As min,
avgMerge(avg value state)As avg
FROM
(
SELECT
toStartofDay(when) As day,
device,
count(*) As count,
maxState(value) AS max_value_state
minState(value) AS min_value_state
avgState(value) AS avg_value_state
FROM counter
WHERE when >= toDate('2023-06-19 00:00:00')
GROUP BY
device, day
ORDER BY
device ASC,
day ASC
)
GROUP BY device
ORDER BY device ASC
Query id: fe564b77-1220-4d89-aee8-a85fa74efbc1
+--------+----------+-------------------------+------------------------+
| device | count | max | min | avg |
+--------+----------+------------+------------+------------------------+
| 1 | 100000 | 108.175 | 3.011 | 55.5923189964985841 |
| 2 | 100000 | 111.1141 | 6.0911 | 58.60119698565006 |
| 3 | 100000 | 114.1142 | 9.0312 | 61.60399999959946 |
| 4 | 100000 | 117.1123 | 12.0273 | 64.6063479971695 |
| 5 | 100000 | 120.1724 | 15.1144 | 67 592546005926141 |
| 6 | 100000 | 123.1725 | 18.0025 | 70.60701499565124 |
| 7 | 100000 | 126.1656 | 210876 | 73,5993999970436 |
| 8 | 100000 | 129.0957 | 24.1077 | 76.6041940114975 |
| 9 | 100000 | 132.1428 | 27.0588 | 79.6000519906807 |
| 10 | 100000 | 135.1959 | 30.0289 | 82.60489601936341 |
+--------+----------+------------+------------+------------------------+
10 rows in set. Elapsed: 0.058 sec, Processed 2,00 million rows, 24.00 MB (34.50 million rows/s., 414:03 MB/s.)执行计划
┌─explain──────────────────────────────────────────────────────────────────────────────────────┬
│ Expression (Projection) │
│ MergingSorted (Merge sorted streams for ORDER BY) │
│ MergeSorting (Merge sorted blocks for ORDER BY) │
│ PartialSorting (Sort each block for ORDER BY) │
│ Expressionr (Before ORDER BY) │
│ Aggregating │
│ Expression ((Before GROUP BY+ (Projection + Before ORDER BY))) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ SettingQuotaAndlimits (Set limits and quota after reading from storage) │
│ ReadFromstorage (MergeTree) │
└──────────────────────────────────────────────────────────────────────────────────────────────┴使用物化视图>>
查询语句
SELECT
device,
sum(count) As count,
maxMerge(max_value_state)AS max,
minMerge(min value state)As min,
avgMerge(avg value state)As avg
FROM counter_daily_mv
GROUP BY device
ORDER BY device ASC
Query id: 76e75304-1637-413a-bfd3-190a914e309c
+--------+----------+-------------------------+------------------------+
| device | count | max | min | avg |
+--------+----------+------------+------------+------------------------+
| 1 | 100000 | 108.175 | 3.011 | 55.5923189964985841 |
| 2 | 100000 | 111.1141 | 6.0911 | 58.60119698565006 |
| 3 | 100000 | 114.1142 | 9.0312 | 61.60399999959946 |
| 4 | 100000 | 117.1123 | 12.0273 | 64.6063479971695 |
| 5 | 100000 | 120.1724 | 15.1144 | 67 592546005926141 |
| 6 | 100000 | 123.1725 | 18.0025 | 70.60701499565124 |
| 7 | 100000 | 126.1656 | 210876 | 73,5993999970436 |
| 8 | 100000 | 129.0957 | 24.1077 | 76.6041940114975 |
| 9 | 100000 | 132.1428 | 27.0588 | 79.6000519906807 |
| 10 | 100000 | 135.1959 | 30.0289 | 82.60489601936341 |
+--------+----------+------------+------------+------------------------+
10 rows in set. Elapsed: 0.002 sec执行计划
┌─explain──────────────────────────────────────────────────────────────────────────────────────┬
│ Expression (Projection) │
│ MergingSorted (Merge sorted streams for ORDER BY) │
│ MergeSorting (Merge sorted blocks for ORDER BY) │
│ PartialSorting (Sort each block for ORDER BY) │
│ Expressionr (Before ORDER BY) │
│ Aggregating │
│ Expression ((Before GROUP BY+ (Projection + Before ORDER BY))) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ SettingQuotaAndlimits (Set limits and quota after reading from storage) │
│ ReadFromstorage (MergeTree) │
└──────────────────────────────────────────────────────────────────────────────────────────────┴总结
-
使用物化视图效率更高,预计算,以空间换时间
-
使用源表和物化视图的执行计划是一致的,但是使用源表要扫描很多数据行,物化视图因为结果集比较少,暂时不需要
源表、物化视图、目标表的关系
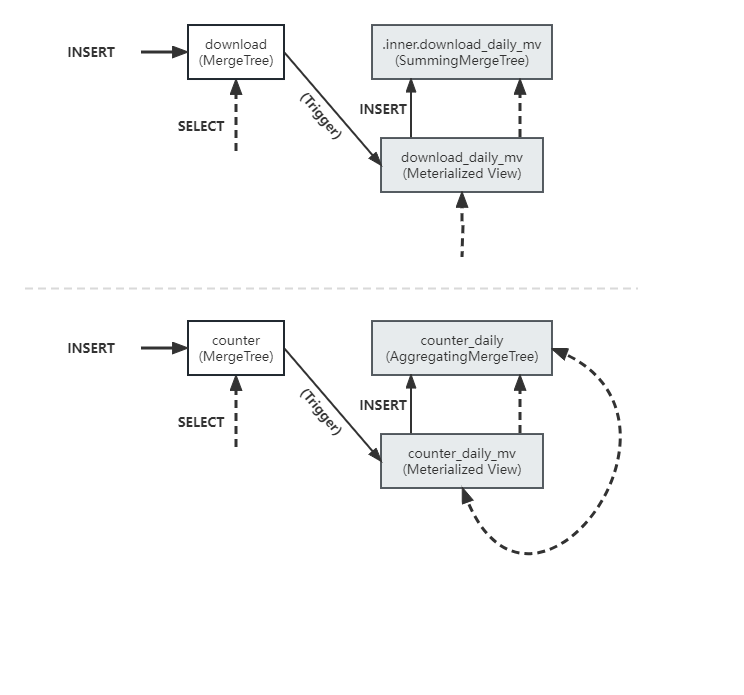
结论
-
物化视图是源表的查询结果集的一份持久化存储,用于报告聚合数据和解析
-
产生物化视图的过程就叫做“物化”(materialization),如 as select ... from ...
-
物化视图是数据库中的预计算逻辑+显式缓存,典型的空间换时间思路
物化视图工作原理
物化视图原理源码分析
-
当向SELECT中指定的源表插入了新行时,这些新行也会发送到该源表的所有物化视图,类似插入触发器,但是同步时机上受限于更新策略
-
数据更新策略:
-
设置刷新机制:ALTER MATERIALIZED VIEW my_view; UPDATE EVERY 1 HOUR;
-
使用视图前手动刷新视图,触发同步,保证数据准确性:REFRESH MATERIALIZED VIEW my_view;
-
创建视图时配置:SETTINGS refresh_interval = 3600,单位秒;0:表示禁用自动刷新;>0:表示间隔多久自动刷新;效果同 UPDATE EVERY 1 HOUR;
-
-
历史数据同步策略:
-
全量数据同步,通过查询条件控制:WHERE when < toDateTime('2023-06-19 00:00:00')
-
设置数据过期时间,保证数据一致性: TTL 30 DAYS
-
手动清理过期数据,保证数据一致性:CLEANUP TTL my_view IN blocking;注意:可能会导致一定的服务停止时间或查询延迟
-
-
-
相对于物化视图,插入不是原子的。因此:同步执行对物化视图的插入,并非所有物化视图都已完全更新并可用于查询
-
链式/级联物化视图的插入也是非原子的,同上
-
对源表现有数据的任何更改(如更新、删除、删除分区等)都不会更改物化视图。
-
添加视图 OutputStream, InterpreterInsertQuery.cpp (https://github.com/ClickHouse/ClickHouse/blob/cb4644ea6d04b3d5900868b4f8d686a03082379a/src/Interpreters/InterpreterInsertQuery.cpp#L313)
-
if (table->noPushingToViews() && !no_destination) out = table->write(query_ptr, metadata_snapshot, context); else out = std::make_shared<PushingToViewsBlockOutputStream>(table, metadata_snapshot, context, query_ptr, no_destination); -
构造 Insert , PushingToViewsBlockOutputStream.cpp (https://github.com/ClickHouse/ClickHouse/blob/cb4644ea6d04b3d5900868b4f8d686a03082379a/src/DataStreams/PushingToViewsBlockOutputStream.cpp#L85)
-
ASTPtr insert_query_ptr(insert.release()); InterpreterInsertQuery interpreter(insert_query_ptr, *insert_context); BlockIO io = interpreter.execute(); out = io.out; -
物化新增数据:PushingToViewsBlockOutputStream.cpp (https://github.com/ClickHouse/ClickHouse/blob/cb4644ea6d04b3d5900868b4f8d686a03082379a/src/DataStreams/PushingToViewsBlockOutputStream.cpp#L331)
-
Context local_context = *select_context; local_context.addViewSource( StorageValues::create( storage->getStorageID(), metadata_snapshot->getColumns(), block, storage->getVirtuals())); select.emplace(view.query, local_context, SelectQueryOptions()); in = std::make_shared<MaterializingBlockInputStream>(select->execute().getInputStream() - 建表流程
-
InterpreterCreateQuery::execute InterpreterCreateQuery::createTable setProperties // 设置属性,如:列信息columns_list InterpreterCreateQuery::doCreateTable StorageFactory::instance().get // 第一次进来,根据query确定引擎为MaterializedView。 根据registerStorageMaterializedView中注册的函数创建IStorage StorageMaterializedView::create(args) // shared_ptr_helper的create StorageMaterializedView::StorageMaterializedView getSelectQueryFromASTForMatView // 提取inner_query, select依赖的table id std::make_shared<ASTCreateQuery>() // 构建创建inner table的ASTCreateQuery,主要是storage和columns InterpreterCreateQuery::execute // 创建inner table createTable doCreateTable StorageFactory::instance().get StorageReplicatedMergeTree::create StorageReplicatedMergeTree::StorageReplicatedMergeTree DatabaseOnDisk::createTable getObjectDefinitionFromCreateQuery // 提取元数据内容 out.next() // 元数据保存到文件中(临时文件) commitCreateTable // 添加映射(uuid和表的映射)及重命名文件 StorageReplicatedMergeTree::startup // 启动一些后台线程 target_table_id = inner table/TO表 的storageid DatabaseCatalog::addDependency // <select中的table, 物化视图>的映射关系。至此,原始表 --> 物化视图 --> inner table/ TO 表 DatabaseOnDisk::createTable ... StorageMaterializedView::startup // IStorage::startup空函数,啥也不做 InterpreterCreateQuery::fillTableIfNeeded // 建立物化视图时加了populate,则需要插入数据 - 数据插入流程
-
TCPHandler::runImpl executeQuery // executeQueryImpl,总结来说就是构造了IBlockOutputStream,数据流向为: ast = parseQuery interpreter = InterpreterFactory::get(ast) // 实例化InterpreterInsertQuery InterpreterInsertQuery::InterpreterInsertQuery InterpreterInsertQuery::execute // 执行外层的insert BlockOutputStreamPtr out = std::make_shared<PushingToViewsBlockOutputStream> // 遍历原始表关联的物化视图 begin insert = std::make_unique<ASTInsertQuery> // 构造insert,需要将数据插入到inner table InterpreterSelectQuery // 根据inner query构造,获取as select的列,用于insert InterpreterInsertQuery::execute // 向inner table插入数据 BlockOutputStreamPtr out = std::make_shared<PushingToViewsBlockOutputStream> // 无关联的物化视图,不用再继续嵌套 output = storage->write // StorageReplicatedMergeTree::write,inner 表的write std::make_shared<ReplicatedMergeTreeBlockOutputStream> // ReplicatedMergeTreeBlockOutputStream构造 replicated_output = dynamic_cast<ReplicatedMergeTreeBlockOutputStream *>(output.get()) out = std::make_shared<AddingDefaultBlockOutputStream>(out, ...) out_wrapper = std::make_shared<CountingBlockOutputStream>(out) // 遍历原始表关联的物化视图 end output = storage->write // StorageReplicatedMergeTree::write,原始表的write replicated_output = dynamic_cast<ReplicatedMergeTreeBlockOutputStream *>(output.get()) out = std::make_shared<AddingDefaultBlockOutputStream>(out, ...) out_wrapper = std::make_shared<CountingBlockOutputStream>(out) processInsertQuery // 真正开始插入数据 state.io.out->writePrefix() // 根据前面构造的OutputStream层层调用,最终通过MergeTreeData::delayInsertOrThrowIfNeeded校验是否可以insert sendData // 向客户端发送表结构 readData // 真正接收数据 readDataNext // 循环读取 receivePacket // 类型为Protocol::Client::Data receiveData initBlockInput // state.block_in = NativeBlockInputStream state.maybe_compressed_in = CompressedReadBuffer state.block_in->read() // NativeBlockInputStream::readImpl 从socket中读取数据 readData // 反序列化数据 state.io.out->write // ... PushingToViewsBlockOutputStream::write ReplicatedMergeTreeBlockOutputStream::write // 在原始表中写入 // 遍历关联的物化视图begin PushingToViewsBlockOutputStream::process // 先select读取数据,再将数据写入到inner表 result_block = in->read() // 读取原始表中的数据 ... PipelineExecutingBlockInputStream::readImpl view.out->write(result_block) ... ReplicatedMergeTreeBlockOutputStream::write // 写入到inner表 // 遍历关联的物化视图end state.io.out->writeSuffix()
物化视图原理总结:
在ClickHouse中,物化视图是由一个名为MergeTreeDataPart的类来实现的。这个类实现了数据的写入、删除、查询等操作。同时,ClickHouse还提供了许多其他的类和接口来支持物化视图的创建、刷新、删除等操作。
在物化视图的创建过程中,ClickHouse会使用CREATE MATERIALIZED VIEW命令创建一个新的物化视图,并在系统中生成一个新的表。在数据写入到源表之后,ClickHouse会通过执行一定的操作将数据刷新(即计算出物化视图的结果并存储)到物化视图所对应的数据存储中。具体来说,ClickHouse会按照源表中的每个分区执行以下操作:
-
读取源表对应分区中新增的数据,将其加入到物化视图中。
-
读取源表对应分区中删除的数据,将其从物化视图中删除。
-
对于更新的数据,ClickHouse会先将旧数据从物化视图中删除,再将新数据加入到物化视图中。
这些操作是通过ClickHouse中的一些类和接口来实现的。具体来说,是在StorageMaterializedView类中实现的,这个类继承了MergeTreeDataPart类,可以对物化视图对应的数据存储进行操作,并且重载了一些相应的方法来支持物化视图的计算。
总的来说,ClickHouse通过在底层数据存储层引入一个物化视图的概念,能够实现数据的高效管理。在数据写入时自动进行刷新,并在查询时进行快速的计算。
使用篇
背景
在实际使用中,经常遇到一个维度关联的问题,比如将物品的类别、用户的画像信息等带入场景计算;这里简单列举下clickhouse中做维度补全的操作。模拟用户维度数据和物品维度数据生成字典(字典有很多种存储结构,这里主要列举hashed模式)
字典
--创建 用户维度数据 字典
CREATE DICTIONARY dim.dict_user_dim on cluster cluster (
uid UInt64 ,
platform String default '' ,
country String default '' ,
province String default '' ,
isp String default '' ,
app_version String default '' ,
os_version String default '',
mac String default '' ,
ip String default '',
gender String default '',
age Int16 default -1
) PRIMARY KEY uid
SOURCE(
CLICKHOUSE(
HOST 'localhost' PORT 9000 USER 'default' PASSWORD '' DB 'dim' TABLE 'user_dim_dis'
)
) LIFETIME(MIN 1800 MAX 3600) LAYOUT(HASHED());
--创建 物品维度数据 字典
CREATE DICTIONARY dim.dict_item_dim on cluster cluster (
item_id UInt64 ,
type_id UInt32 default 0,
price UInt32 default 0
) PRIMARY KEY item_id
SOURCE(
CLICKHOUSE(
HOST 'localhost' PORT 9000 USER 'default' PASSWORD '' DB 'dim' TABLE 'item_dim_dis'
)
) LIFETIME(MIN 1800 MAX 3600) LAYOUT(HASHED())
注意事项
-
语法不做详细介绍,想要更深了解可以参考官方文档
-
字典的数据是冗余在所有节点的,默认字典的加载方式是惰性加载,也就是需要至少一次查询才能将字典记载到内存,避免一些不使用的字典对集群带来影响。
-
也可以通过hash分片的方式将用户指定到某个shard,那么字典也可以实现通过hash分片的方式存储在每个节点,间接实现分布式字典,减少数据存储
使用方式
-
一种是通过dictGet;如果只查询一个key,建议使用dicGet,代码复杂可读性高,同时字典查的value可以作为另一个查询的key
-
另外一种方式是通过join
--单value方法1:
SELECT
dictGet('dim.dict_user_dim', 'platform', toUInt64(uid)) AS platform,
uniqCombined(uid) AS uv
FROM dws.user_product_dis
WHERE day = '2023-06-19'
GROUP BY platform
Query id: 52234955-2dc9-4117-9f2a-45ab97249ea7
┌─platform─┬───uv─┐
│ android │ 9624 │
│ ios │ 4830 │
└──────────┴──────┘
2 rows in set. Elapsed: 0.009 sec. Processed 49.84 thousand rows, 299.07 KB (5.37 million rows/s., 32.24 MB/s.)
--多value方法1:
SELECT
dictGet('dim.dict_user_dim', 'platform', toUInt64(uid)) AS platform,
dictGet('dim.dict_user_dim', 'gender', toUInt64(uid)) AS gender,
uniqCombined(uid) AS uv
FROM dws.user_product_dis
WHERE day = '2023-06-19'
GROUP BY
platform,
gender
Query id: ed255ee5-9036-4385-9a51-35923fef6e48
┌─platform─┬─gender─┬───uv─┐
│ ios │ 男 │ 2236 │
│ android │ 女 │ 4340 │
│ android │ 未知 │ 941 │
│ android │ 男 │ 4361 │
│ ios │ 女 │ 2161 │
│ ios │ 未知 │ 433 │
└──────────┴────────┴──────┘
6 rows in set. Elapsed: 0.011 sec. Processed 49.84 thousand rows, 299.07 KB (4.70 million rows/s., 28.20 MB/s.)
--单value方法2:
SELECT
t2.platform AS platform,
uniqCombined(t1.uid) AS uv
FROM dws.user_product_dis AS t1
INNER JOIN dim.dict_user_dim AS t2 ON toUInt64(t1.uid) = t2.uid
WHERE day = '2023-06-19'
GROUP BY platform
Query id: 8906e637-475e-4386-946e-29e1690f07ea
┌─platform─┬───uv─┐
│ android │ 9624 │
│ ios │ 4830 │
└──────────┴──────┘
2 rows in set. Elapsed: 0.011 sec. Processed 49.84 thousand rows, 299.07 KB (4.55 million rows/s., 27.32 MB/s.)
--多value方法2:
SELECT
t2.platform AS platform,
t2.gender AS gender,
uniqCombined(t1.uid) AS uv
FROM dws.user_product_dis AS t1
INNER JOIN dim.dict_user_dim AS t2 ON toUInt64(t1.uid) = t2.uid
WHERE day = '2023-06-19'
GROUP BY
platform,
gender
Query id: 88ef55a6-ddcc-42f8-8ce3-5e3bb639b38a
┌─platform─┬─gender─┬───uv─┐
│ ios │ 男 │ 2236 │
│ android │ 女 │ 4340 │
│ android │ 未知 │ 941 │
│ android │ 男 │ 4361 │
│ ios │ 女 │ 2161 │
│ ios │ 未知 │ 433 │
└──────────┴────────┴──────┘
6 rows in set. Elapsed: 0.015 sec. Processed 49.84 thousand rows, 299.07 KB (3.34 million rows/s., 20.07 MB/s.)结论
-
从查询结果来看,dictGet要更快一些,同时在代码可读性上也要更好一些,可以结合场景使用。
-
如果在业务开发过程中,遗漏了维度或者指标,则可以通过修改字典和视图来实现,实现方式
-
-- 新增字典维度 alter table dim.dict_user_dim on cluster cluster modify column if exists gender String default '未知' comment '性别' after item_id; -- 修改物化视图 alter table my_view_table on cluster cluster_name add column if not exists new_measure AggregateFunction(uniqCombined,UInt32) comment 'new_measure';实践经验
-
如果业务表有较频繁的删除或修改,物化视图本地表的引擎需要使用CollapsingMergeTree或VersionedCollapsingMergeTree
-
如果物化视图是由两表join产生的,则仅有在左表插入数据时才更新。如果只有右表插入数据,则不更新
-
尽量避免使用物化视图分布式表(MATERIALIZED VIEW & Distributed),在源表数据有变化时触发物化视图更新,物化视图分布式表又根据分片键对聚合后的数据进行再次分片至物化视图本地表(_local),写入分布式表的SQL会被裂变成多条写入SQL,从而使得zk的事务数疯涨,影响数据同步效率
-
--创建本地表 CREATE TABLE IF NOT EXISTS ods.click_log_local ON CLUSTER cluster_01 ( click_date Date, click_time DateTime, user_id Int64, event_type String, city_id Int64, product_id Int64 ) ENGINE = ReplicatedMergeTree('/ch/tables/ods/click_log/{shard}','{replica}') PARTITION BY click_date ORDER BY (click_date,toStartOfHour(click_time),city_id,event_type) TTL click_date + INTERVAL 1 MONTH SETTINGS index_granularity = 8192, use_minimalistic_part_header_in_zookeeper = 1, merge_with_ttl_timeout = 86400; --创建分布式表 CREATE TABLE IF NOT EXISTS ods.click_log_all ON CLUSTER cluster_01 AS ods.click_log_local ENGINE = Distributed(cluster_01,ods,click_log_local,rand());--创建本地表 CREATE MATERIALIZED VIEW IF NOT EXISTS ods.city_product_stat_local ON CLUSTER cluster_01 ENGINE = ReplicatedSummingMergeTree('/ch/tables/ods/city_product_stat/{shard}','{replica}') PARTITION BY click_date ORDER BY (click_date,ts_hour,city_id,product_id) SETTINGS index_granularity = 8192, use_minimalistic_part_header_in_zookeeper = 1 AS SELECT click_date, toStartOfHour(click_time) AS ts_hour, city_id, product_id, count() AS visit FROM ods.click_log_local GROUP BY click_date,ts_hour,city_id,product_id; --创建分布式表 CREATE TABLE IF NOT EXISTS ods.city_product_stat_all ON CLUSTER cluster_01 AS ods.city_product_stat_local ENGINE = Distributed(cluster_01,ods,city_product_stat_local,rand());--在查询前针对指定分区,手工触发merge optimize table city_product_stat_local on cluster cluster_01 partition '2021-12-01' FINAL DEDUPLICATE by click_date,ts_hour,city_id,product_id select * from city_product_stat_all mspsa order by click_date参考链接
https://clickhouse.com/docs/en/sql-reference/statements/create/view#materialized-view
https://clickhouse.com/docs/knowledgebase/are_materialized_views_inserted_asynchronously
https://clickhouse.com/docs/en/guides/developer/cascading-materialized-views
https://clickhouse.com/docs/en/operations/settings/settings#wait-for-async-insert
https://clickhouse.com/docs/en/operations/settings/settings#optimize-on-insert
https://clickhouse.com/docs/en/integrations/data-formats/json#using-materialized-views
https://clickhouse.com/docs/en/whats-new/changelog/2020#bug-fix-27
















 7126
7126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











