







 凯撒密码是一种简单的替换加密技术,通过将字母表上的字母按固定数目偏移进行加密。本文介绍了凯撒密码的原理,并展示了如何使用Python实现加密和解密的过程,包括针对不同情况的加密算法和解密算法。
凯撒密码是一种简单的替换加密技术,通过将字母表上的字母按固定数目偏移进行加密。本文介绍了凯撒密码的原理,并展示了如何使用Python实现加密和解密的过程,包括针对不同情况的加密算法和解密算法。
首先了解一下什么是凯撒密码(Caesar Cipher)
凯撒密码 (英語:Caesar cipher), 或称凯撒加密、凯撒变换、变换加密,是一种最简单且最广为人知的加密技术. 凯撒密码是一种替换加密技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移後被替换成密文.
简单来讲就是把原文里的字母按照n个单位,特定方向去替换 导致无法正常阅读
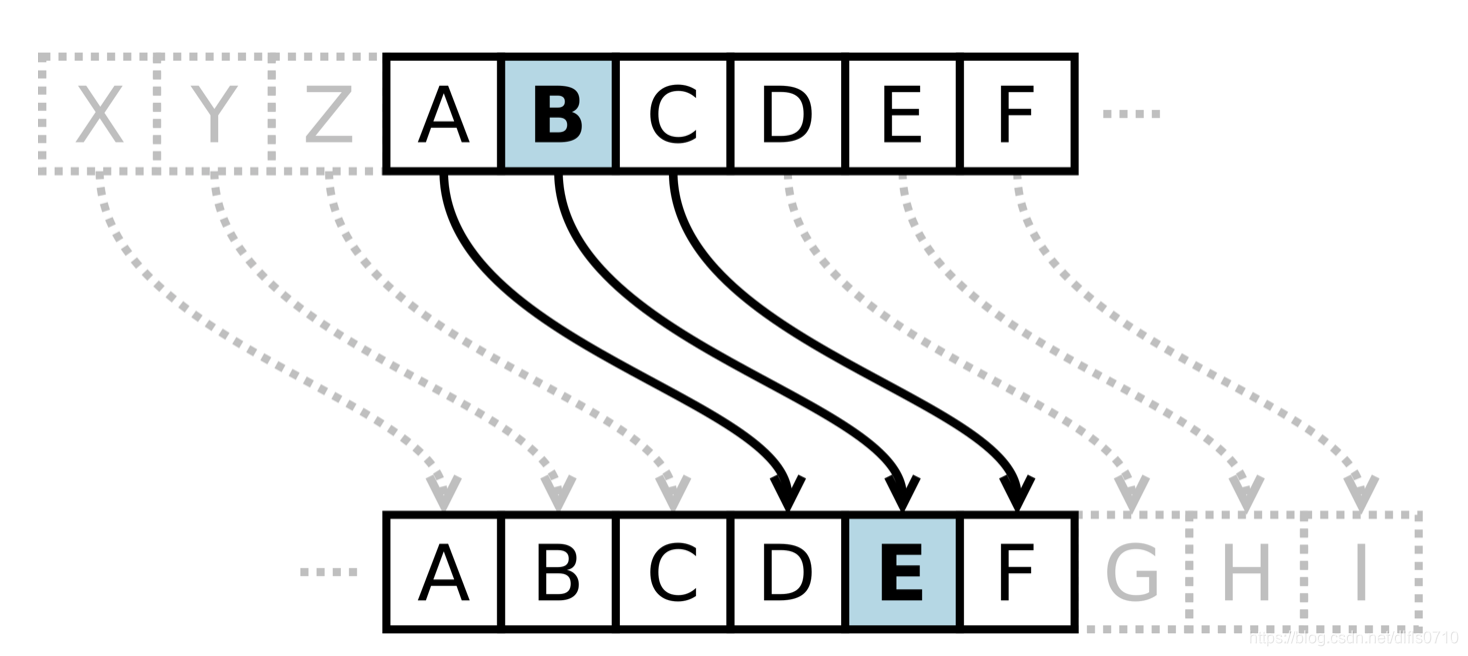
图中,是按照3个单位向右替换得到 B -> E (凯撒密码的原理也是同理)
例子:原文为HELLO WORLD (根据凯撒密码的3个单位,向右加密)
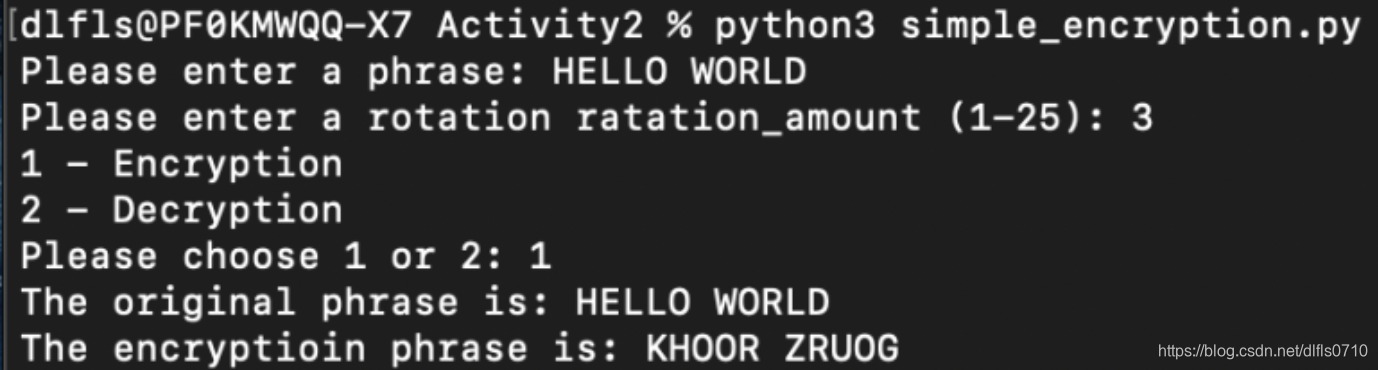
会得出密文为:KHOOR ZRUOG
既然了解了原理,那就了解一下在代码里如何实现以上操作!
我们会利用Unicode来帮助我们!
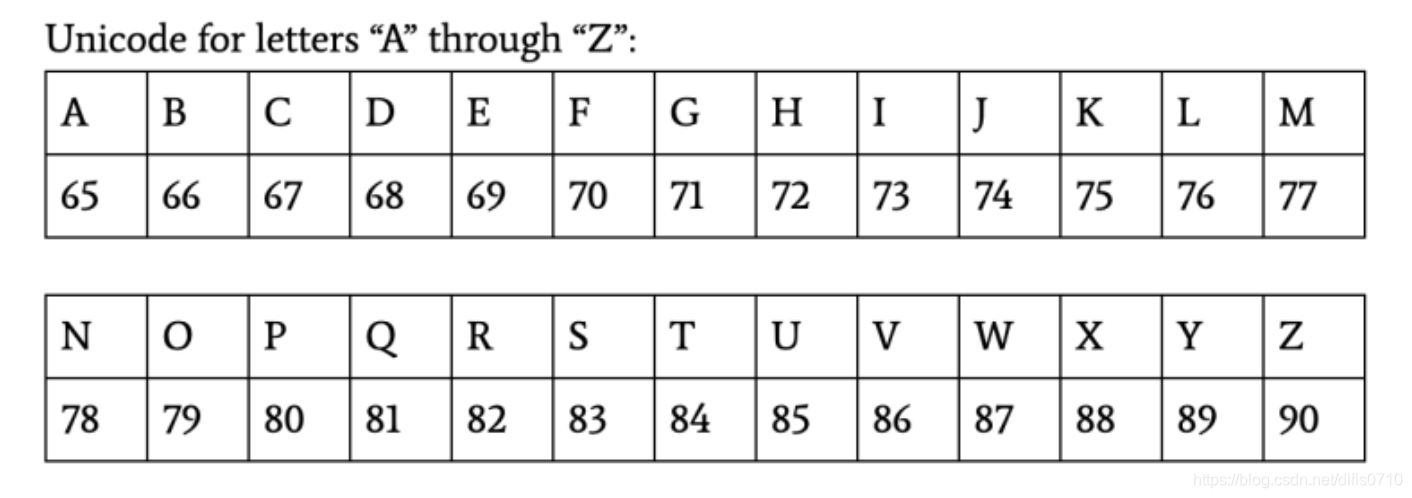
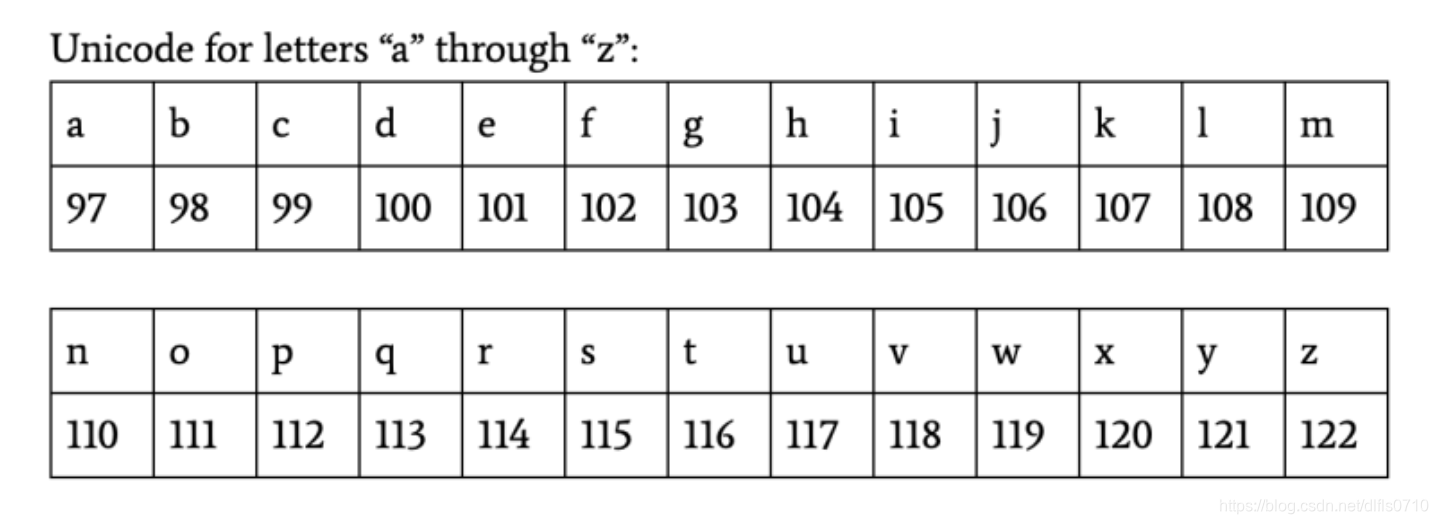
具体原理公式:(目标字母x, 替换单位n)
加密算法:
解密算法:
根据公式会出现以下3中情况:
1. (x+n) < 26 -> 得出加密字母 = 明文字母单纯右移n位
2. (x+n) = 26 -> 加密字母 = 明文字母(不变)
3. (x+n) > 26 -> 去除多余,再向右移n位 例如x = Z (25), n = 3 得出(25+3)%26 = 2 (C)
代码呈现算法: (代码来自于本人课题,所以请谅解注释等均为英文)
phrase = input("Please enter a phrase: ")
ratation_amount = int(input("Please enter a rotation ratation_amount (1-25): "))
enc = int(input("1 - Encryption\n2 - Decryption\nPlease choose 1 or 2: "))
phrase_enc = ""
phrase_dec = ""
if enc == 1: #encryption
for l in phrase: #letters/numbers "l" in phrase ("l" could be any alphabet and number)
if l.isupper():#if letter "l" is uppcased (because upper and lower share different number of unicode)
l_unicode = ord(l) #find the unicode for the letter "l"
l_index = ord(l) - ord("A") #the distance between the letter "l" and A (the start)
new_index = (l_index + ratation_amount) % 26 #refrence from https://en.wikipedia.org/wiki/Caesar_cipher
#if (l_index + ratation_amount) <26 new_index = l_index+ratation_amount
#if (l_index + ratation_amount) =26 it means no shift made or stay as normal alphabet order(A~Z)
#if (l_index + ratation_amount) >26 new_index = (l_index+ratation_amount)%26 (subtracting n time of 26)
new_unicode = new_index + ord("A") #adding distance/ratated_amount to the start(A)
new_character = chr(new_unicode) #convert unicode to character
phrase_enc = phrase_enc + new_character #encrypted phrase
elif l.islower(): #if letter "l" is lowercased
l_unicode = ord(l)#find the unicode for the letter "l"
l_index = ord(l) - ord("a") #the distance between the letter "l" and a (the start)
new_index = (l_index + ratation_amount) % 26 #refrence from https://en.wikipedia.org/wiki/Caesar_cipher
#if (l_index + ratation_amount) <26 new_index = l_index+ratation_amount
#if (l_index + ratation_amount) =26 it means no shift made or stay as normal alphabet order (a~z)
#if (l_index + ratation_amount) >26 new_index = (l_index+ratation_amount)%26 (subtracting n time of 26)
new_unicode = new_index + ord("a") #adding distance/ratated_amount to the start(a)
new_character = chr(new_unicode) #convert unicode to character
phrase_enc = phrase_enc + new_character #encrypted phrase
else: #non alphabet (number or notation)
phrase_enc += l #return orginal "l" in phrase_enc
#Display the results
print("The original phrase is:",phrase)
print("The encryptioin phrase is:",phrase_enc)
else: #decryption
for l in phrase: #letters "l" in phrase ("l" could be any alphabet)
if l.isupper(): #if letter "l" is uppcased
l_unicode = ord(l) #find the unicode for the letter "l"
l_index = ord(l) - ord("A")
#the distance between the letter "l" and A (we considering the phrase as ciphertext which means it's shifted already so do the subtracting instead)
new_index = (l_index - ratation_amount) % 26 #refrence from https://en.wikipedia.org/wiki/Caesar_cipher
#return the original order in normal alphabet set
new_unicode = new_index + ord("A") #adding distance/order to the start(A)
new_character = chr(new_unicode) #convert unicode to character
phrase_dec = phrase_dec + new_character #decrypted phrase
elif l.islower(): #if letter "l" is lowercased
l_unicode = ord(l) #find the unicode for the letter "l"
l_index = ord(l) - ord("a")
#the distance between the letter "l" and A
new_index = (l_index - ratation_amount) % 26 #refrence from https://en.wikipedia.org/wiki/Caesar_cipher
#return the original order in normal alphabet set
new_unicode = new_index + ord("a") #adding distance/order to the start(a)
new_character = chr(new_unicode) #convert unicode to character
phrase_dec = phrase_dec + new_character #decrypted phrase
else: #non alphabet or number (notation)
phrase_dec += l #return original "l" in phrase_dec
#Display the results
print("The original phrase is:",phrase)
print("The decryption phrase is:",phrase_dec
大概流程就是
1. 得到一段明文或密文
2. 得到替换单位n (default加密为向右,解密为向左)
3. 得到用户是想加密/解密
4. 根据明文/密文里的字母unicode,得出在字母排序表里的index (A~Z -> 0~25)
相应的增加或减少unicode(加密或解密)得出对应的字母 再按顺序组合成一段完整的密文/明文

















 1682
1682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









