1. 数字图像的表示与存储
一幅数字图像可以看成是一个由'颜色点'组成的二维矩阵,矩阵的宽和高分别对应图片的宽和高。根据光波及色彩的特性我们知道,任何颜色都可以由红色、绿色、蓝色三种颜色按照特定的比例混合得到,这三种颜色也被称为三原色,因此,单个'颜色点'可以由一个(R,G,B)形式的三元组表示,RGB分别表示红色绿色蓝色三种颜色的值。这样,彩色图像就对应一个形状为(h, w, 3)的三维矩阵。
一般情况下,RGB的颜色值各使用一个uint8的数字来表示,取值为0~255,总共可以表示255^3=16581375种颜色,对于人眼来说,已经足够丰富。
以一张常见的4k分辨率的彩色图像为例,其宽和高分别为3840×2160,则在不压缩的情况下,为了表示和存储这张4k图像,需要占用的存储空间为:
3840 * 2160 * 3 * 1= 24883200 Bytes ≈ 24.88 MB
2. “减肥了的”jpg图像的体积
这是一张来自互联网的4K分辨率的jpg图片,可以看到,其实际所占的存储空间仅为441.15KB,只相当于24.88MB的2%左右,使用jpg技术,我们在这张图片上获得了98%左右的压缩比。
3. jpeg图像压缩的实现原理
最高可以降低90%以上的存储空间占用而且几乎不影响图像的视觉效果,看起来非常不可思议,jpeg是如何通过一系列的“魔法”来实现高度的,让我们来一探究竟。
3.1 YUV色彩模型与降采样压缩
前面提到,任何颜色都可以由RGB三种颜色根据比例混合得到,既Color = k1*R + k2*G + k3*B,k1、k2、k3分别表示R、G、B颜色的系数。除了RGB色彩模型外,研究人员还提出了YUV色彩模型,Y表示颜色的亮度,U和V表示颜色的色值和饱和度,RGB颜色和YUV颜色可以进行相互转换。
RGB转YUV的转换方式为:
Y = 0.299R + 0.587G + 0.114B
U = -0.169R - 0.331G + 0.5B
V = 0.5R - 0.419G - 0.081B
YUV转RGB的转换方式为:
R = Y+1.13983×V
G = Y−0.39465×U−0.58060×V
B = Y + 2.03211×U
YUV 和 RGB 之间转换的公式及其系数是根据人类视觉系统对亮度和色度的感知特点,通过数学分析和实验数据确定的。这些系数旨在优化颜色转换,使得转换后的颜色与原始颜色保持视觉上一致性。
使用YUV色彩模型来表示数字图像有什么好处呢?研究人员通过一系列的视觉实验来检测人眼的视觉感知特性,实验发现,人眼对于亮度的变化最敏感,而对于颜色的色值和饱和度信息不太敏感,这一特性启发了我们,
既然对UV通道的变化不太敏感,那么就没必要存储精确的完整的UV通道的信息,可以通过降采样的方式存储近似的信号,牺牲一定的精确性来获得更低的存储占用。具体的降采样方式是对于UV通道中的每个2x2的窗口,只保留其左上角的元素,如下图所示
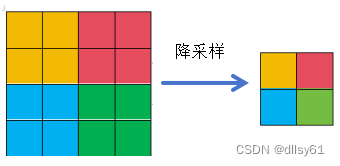
通过对UV分量降采样后,UV通道的矩阵大小都变为原本的1/4,相应地,可以图片总大小的变化为原来的50%
1/3 + (1/3) * 1/4 + (1/3) * 1/4 = 0.5
3.2 离散余弦变换及DCT系数表的量化
通过对YUV色彩进行降采样,我们获得了50%的压缩比,看起来还不错,不过距离90%以上的压缩比还有很大距离。
为了进一步对图像进行压缩,研究者们又引入了离散余弦变换(Discrete Cosine Transform)。详细的离散余弦变换的定义及证明读者请自行查阅学习,此处直接应用其结论。
对于任何8*8的灰度图像,都可以使用如下的64个基础图像(base image)通过线性组合的方式得到。

从信息存储的角度看,有了DCT系数,就可以还原出原始的行像素值,有了行像素值也可以计算出DCT系数,两者记录的信息完全等价。因此,我们可以不再记录原始的图像的数值,转而记录每个基础图像进行线性组合时候的系数,这样8*8的灰度图像就和8*8的DCT系数表起来。
将图像的像素值转为DCT系数表来表示之后,需要存储的信息量完全没有减少,DCT系数表和图像的尺寸完全相同。得益于人眼的另一个视觉感知特性,对组成画面信号的余弦函数中的低频部分敏感,而对高频部分不敏感(64个基础图像中左上角部分是低频的基础图像,右下角部分是高频的基础图像),因此,和对UV进行压缩的思路相同,我们可以忽略或者移除部分对人眼感知几乎没有影响的高频分量。研究人员根据一系列的视觉测试实验,得到了一张表格,称为量化表,将DCT系数表除以量化表然后取整,就得到了量化表示的DCT系数表。DCT系数表的量化原理如下图所示
可以看到,量化表示的DCT系数表中右下角部分出现了很多0值,即左下角的基础图像对应的权值为0,实际上根据所需的压缩比的不同或所需的图片质量不同,对应的量化表也不同,越高的压缩比,对应的量化表中的除数也就越大,量化后就能得到更多的0,这些重复的0值给进一步压缩留下了空间。
3.3 游程编码与霍夫曼编码

在得到量化后的DCT系数表之后,需要运用一些传统的编码技术进一步缩减存储空间,首先jpg压缩算法会对DCT系数表进行z形扫描,如上图所示,z扫描的目的是为了尽可能地获得更多的连续0,z扫描后,DCT系数表变成了类似这样的一组连续串“1234567890000000000000000000000”。
游程编码又称行程编码,主要思路是将一个相同值的连续串用一个代表值和串长来代替。例如,有一个字符串“aaabccddddd”,经过行程编码后可以用“3a1b2c5d”来表示。
霍夫曼编码是一种基于频率信息的最优编码策略,其思路是对于出现频率越高的模式串,倾向于使用更短的码长来编码表示它,对于出现频率越低的模式串,倾向于使用更长的码长来编码表示它,这样可以使编码之后的字符串的平均长度、期望值降低。
jpg压缩算法会对z扫描后得到的串进行游程编码和霍夫曼编码,最后就得到了编码后的jpg图像数据。
3.4 完整流程
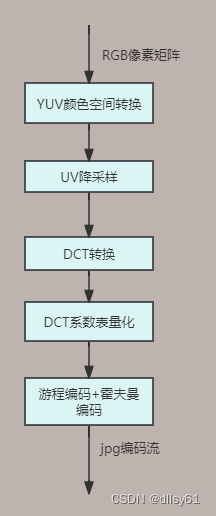
完整的jpg编码流程如上图所示,相对应地,解码的过程就是将编码的过程完全颠倒过来,从jpg编码流中重建出RGB像素矩阵。
4 总结与思考
总览jpeg压缩算法的主要流程,贯穿其中的两个思路是移除不重要的分量信息和使用低精度的近似牺牲一定的精确性来换取存储空间的压缩,这两种思路或者说压缩哲学也广泛地体现在其它需要压缩数据的场景中,比如音频的mp3压缩和神经网络的量化压缩技术,感兴趣的读者可自行拓展学习。
每个人的手机、电脑中每天都在使用的jpeg图片,每个人都对其司空见惯习以为常,然而其背后却隐藏着非常精巧、非常复杂同时也非常优雅的设计。深究一下,顿感自己的无知与自己日常所做工作的粗糙与渺小,真正体会到了什么是“吾生也有涯而知也无涯”。
便捷的电子化的现代生活,背后正是由无数个“jpeg”这样的技术支撑起来的,需要庞大的标准化组织去制定规范,需要优秀的工程师去实现可靠的代码,需要无数的应用工程师针对各种设备开发对应的应用,科技支撑的现代化生活,像一个华丽美好的梦,也像一个放置于危岩上的精致易碎的花瓶。
5. 参考资料
【中英双字】JPEG算法原理 jpeg图片是如何压缩的?
离散余弦变换可视化讲解
令人拍案叫绝的jpeg图像压缩原理
维基百科-jpeg






















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









