






引言:你被这些词汇“绕晕”了吗?
最近是不是感觉整个世界都在聊AI?从ChatGPT、Sora、到Cursor… 人工智能正以前所未有的速度和广度渗透进我们的生活和工作。
伴随而来的是一堆高频词汇:大模型(Large Model)、LLM(Large Language Model)、机器学习(Machine Learning)、深度学习(Deep Learning,虽然你没问,但它太重要了,我们也会提一下)、还有最新的智能体(Agent)……
哎呀,听得多了,感觉脑袋都成了一锅粥。
- 这些词到底是什么意思?
- 它们之间有啥关系?
- 是不是大模型就是AI的全部?
- LLM又是大模型的子集吗?
- Agent是不是更高级的AI?
如果你也有这些疑问,恭喜你,来对地方了!
本文将用最直白的方式,帮你彻底理清这些核心概念。准备好了吗?咱们开始!
第一站:最宏大的概念——人工智能 (Artificial Intelligence, AI)
想象一下,我们人类拥有的智能是什么?是会思考、会学习、会理解语言、会识别图像、会决策、会创造……
人工智能(AI),它的目标就是要让机器也具备这些类似人类的智能能力。
所以,*人工智能(AI)是一个非常、非常广泛的概念,它是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。
AI的梦想始于上世纪中叶,早期试图通过编写大量规则来模拟智能。然而,面对现实世界的复杂性和例外情况(如识别各种各样的猫),规则难以穷尽,这种方法很快遭遇瓶颈。
这就像想教一个机器人认识所有的猫:你可能写规则"猫有四条腿、有尾巴、会喵喵叫",但总有无腿猫、无尾猫,或者不会叫的猫… 规则会变得异常复杂且不完善。
所以,AI并不仅仅指代某个具体的算法或技术,它更像是一个宏伟的目标和愿景:让机器拥有智能。而为了实现这个目标,科学家们探索了各种各样的方法,其中最成功、最主流的一个方法,就是接下来要说的——机器学习。
AI就像一个大大的金字塔,人工智能(AI)就是金字塔的最顶端,代表着最终的目标。
第二站:实现AI的强大工具——机器学习 (Machine Learning, ML)
既然给机器写规则太难,那能不能让机器自己去“看”数据,然后自己从数据里找到规律、学会完成任务呢? 这就是机器学习的核心思想!
机器学习(ML)是人工智能的一个子集。它研究如何让计算机系统通过分析数据来自动改进性能,而无需进行显式的程序设计。
区别于传统编程的"输入数据 + 规则 = 输出",机器学习的核心是"输入数据 + 期望输出 = 输出规则(模型)",让机器通过数据学习规律。
例如,识别猫时,传统方法需手动编写规则,而机器学习则通过大量猫和非猫图片及标签(期望输出),自动学习识别模型。
ML主要分为监督学习(有标签数据)、无监督学习(无标签数据)和强化学习(通过试错学习)。
所以,机器学习是实现人工智能目标的重要方法论和技术。 如果AI是金字塔顶端的目标,那机器学习就是实现这个目标过程中,位于金字塔中间、非常重要的一层技术。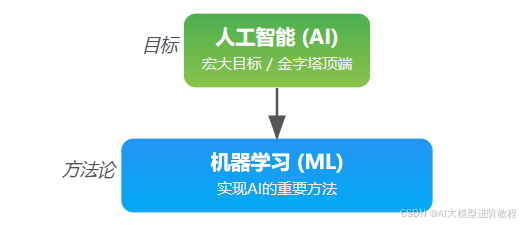
第三站:机器学习的颠覆者——深度学习 (Deep Learning, DL)
在说大模型之前,绕不开一个概念:深度学习。
深度学习(Deep Learning, DL)是机器学习的一种,它用的是一种叫“神经网络”的模型。
你可以把神经网络想象成人脑神经元的简化版。它由一层层“节点”组成:数据从输入层进来,经过中间的隐藏层处理,最后从输出层得出结果。每一层负责提取不同层次的特征,越往后,提取的特征就越抽象。
比如在识别一张人脸的图片时:
- 前几层可能识别边缘、颜色、角等简单特征,
- 中间层可能识别眼睛、鼻子、嘴巴,
- 更深层甚至能判断出整张脸是谁。
在深度学习出现之前,机器学习模型需要人手动“设计”出这些特征,非常依赖经验。深度学习厉害的地方在于:它能自动从原始数据中学会提取有用特征,大大简化了流程。
从2010年左右开始,由于GPU变强、数据变多,深度学习迅速发展,在图像识别、语音识别、自然语言处理等领域取得了巨大突破,也由此引发了这波AI热潮。
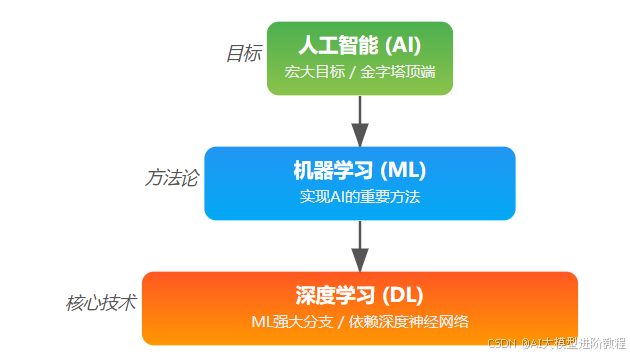
*所以,深度学习是机器学习中目前最成功、最热门的一个分支,是实现复杂AI任务的利器。*
在我们的AI金字塔里,深度学习是位于机器学习下一层,更靠近技术实现的那一层。
第四站:规模带来智能的飞跃——大模型 (Large Models)
在深度学习快速发展的过程中,科学家发现一个现象:只要神经网络足够大、数据够多,模型的能力会突然“飞跃”,出现一些小模型根本做不到的新本事,这种现象叫做 “涌现能力”(Emergent Abilities)。
于是,“大力出奇迹”变成了新思路,大家开始训练规模更大的模型,这就诞生了所谓的 大模型(Large Models)。
什么是大模型?
简单说,就是:
- 参数特别多(几十亿、上百亿,甚至万亿);
- 数据特别大(从全网抓来的海量文本、图像等);
- 训练时间特别长(动辄几百张显卡跑几个月)。
但“大”不仅是体积大,它带来了三种能力:
- 泛化强:能处理更多样、复杂的任务。
- 知识多:模型“看过”很多东西,像个百科全书。
- 有涌现能力:没学过的任务也能“试试看”,比如给它几个例子,它就能模仿着做(few-shot);甚至没例子也能做(zero-shot)。
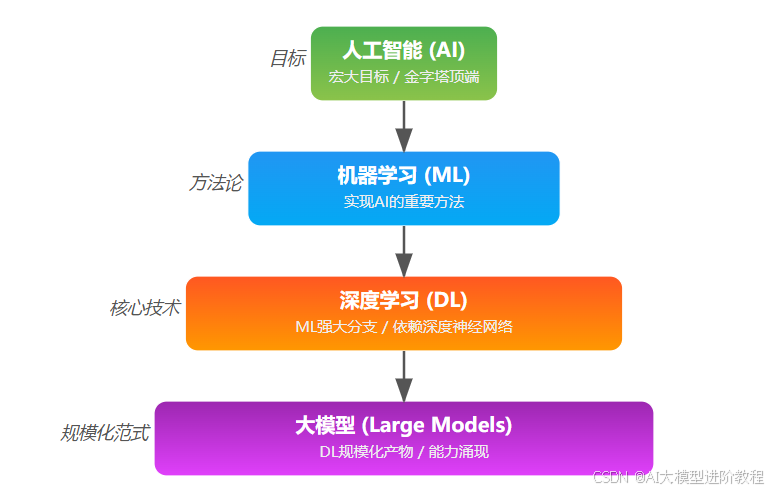
大模型的出现,是深度学习发展的重要转折点。以前,做一个任务(比如翻译、问答)就要训练一个专门的模型。现在,只需要一个提前训练好的大模型,配合简单的指令(Prompt)或少量微调,就能完成各种任务,大大提升了AI的通用性和效率。
大模型是深度学习发展到一定阶段的产物,也是当前实现强大AI能力的主流方式。它是深度学习里,通过“做大做强”实现能力飞跃的代表。
第五站:大模型中的“语言大师”——LLM (Large Language Models)
在大模型这个家族中,有一类特别亮眼的成员,那就是大型语言模型(LLM)。
**LLM是专门处理文字的大模型,擅长理解、生成和分析人类语言。
它的核心技术是Transformer架构(就是那个“Attention is all you need”),特别适合处理一段接一段的文字,能理解上下文、抓住语义。
LLM之所以厉害,是因为它在海量文本数据上学过,比如网页、书籍、对话、代码等。在这个过程中,它学会了语言的用法、知识、常识,甚至一些逻辑推理。
我们熟悉的ChatGPT、Gemini、Claude、文心一言等,都是典型的LLM,能聊天、写文章、翻译、编程、总结信息,甚至还能“创作”。
虽然它们以语言为主,但通过“多模态”技术,有的也能看图、听音频、生成视频。不过,本质上它们还是以语言为核心。
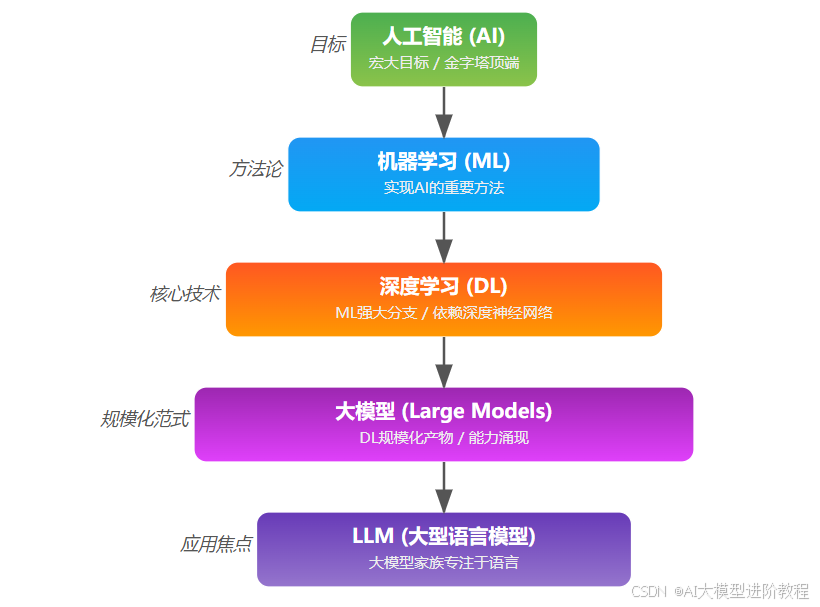
所以,LLM是大模型中最成功、用得最广的一类,主攻语言任务,是整个大模型圈子里最闪亮的一颗星。
第六站:让AI能“手脚并用”去完成任务——Agent (智能体)
前面我们聊了AI的目标、实现方法(ML/DL)、以及强大的工具(大模型/LLM)。但有了强大的“大脑”(大模型),怎么让它去完成一系列复杂的任务呢?比如帮我订机票、写一篇带图的文章、管理我的日程?靠一次问答是不行的。
这时候,智能体(Agent) 登场了。
*智能体(Agent)是一种能感知环境、思考目标、主动采取行动来完成任务的系统。* 它不只是被动地接收输入然后输出,而是有主动性和目标性。
传统的软件Agent很早就存在了(比如帮你过滤邮件的Agent)。但当前语境下讨论的“AI Agent”,特别是“基于大模型的Agent”,则拥有前所未有的强大能力,因为它们的“大脑”是强大的大模型。
基于大模型的Agent通常包含几个核心组件:
- *感知:理解用户指令、读取文件、获取网页等信息。*
- *规划:用大模型“思考”怎么完成任务,分步骤执行。*
- *行动:调用搜索引擎、API,写邮件、生成文本等。*
- *记忆:记住中间结果或你的偏好,方便后续使用。*
如果说大模型(LLM)是一个强大的“大脑”,那么Agent就是给这个大脑安上了“眼睛”(感知)、“手脚”(行动)和“思考框架”(规划/记忆),让它能够自主地与外部世界互动,一步步地解决复杂问题,而不仅仅是回答一个问题。
所以,*Agent是一种将大模型(或其他AI能力)落地、使其能够自主执行任务的应用范式或系统架构。它代表着让AI更具自主性和实用性的方向。* Agent是构建在前面所有技术之上的,是AI金字塔中更靠近实际应用和自主行为的那一层。
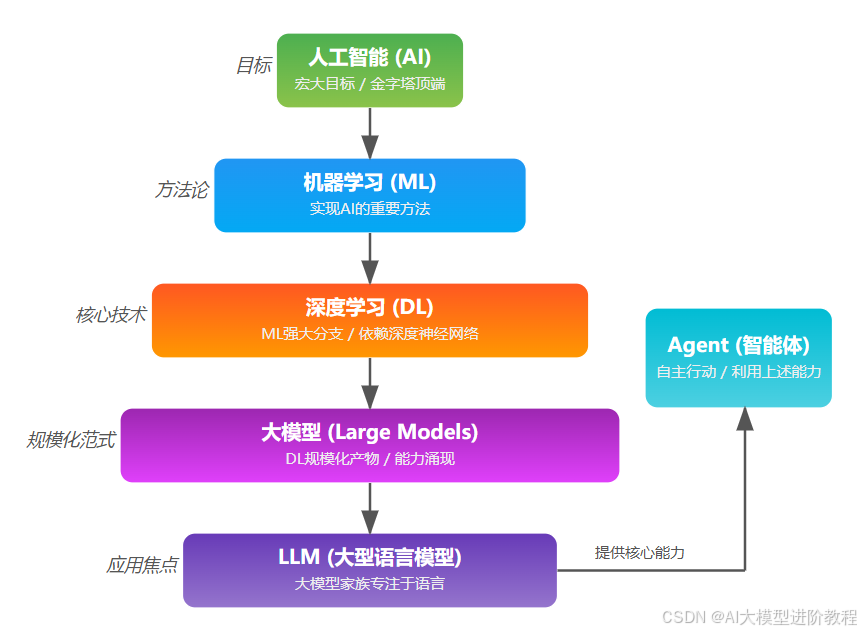
概念大串联:它们到底是什么关系?
好了,现在我们把这几个概念串起来:
- AI:目标是让机器像人一样聪明。
- 机器学习(ML):实现AI的一种方法,靠数据让机器学规律。
- 深度学习(DL):ML中最强的技术,用神经网络自动学习复杂特征。
- 大模型:DL发展到一定规模后出现的新范式,模型越大,能力越强。、
- LLM:大模型中专门处理语言的,是目前应用最广、最强的一类。
- Agent:用LLM等AI能力,构建能感知、思考、行动的系统,完成复杂任务。
它们的关系可以简单理解为一种包含和演进的关系。
一句话:AI是愿景,ML是方法论,DL是技术核心,LLM是大脑,大模型是基座,Agent是落地。
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!
你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









