





有几种方法可以改善您的产品。 一种方法是仔细跟踪用户的体验并在此基础上进行改进。 我们确实自己应用了此技术,并再次花了一些时间查看不同的数据
除了我们追求的许多其他方面之外,我们还提出了一个问题“延迟GC触发应用程序的最坏情况是什么”。 为了回答这个问题,我们分析了过去两个月中来自312个连接Plumbr Agent的JVM的数据。 结果很有趣,我们决定与您分享结果:
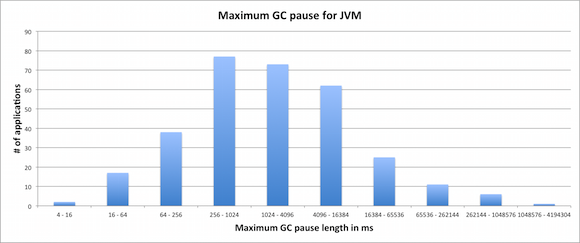
在X轴上,此JVM中有最大的暂停长度,分为多个存储区。 在Y轴上,有特定数量的最大暂停的应用程序。 使用上面的数据,我们可以例如对被监控的312个JVM声明以下内容:
- 57个JVM(18%)设法使GC停顿了一下,最大停顿时间不到256ms
- 73个JVM(23%)面临的最大GC暂停时间为1024毫秒至4095毫秒
- 由于GC,105个JVM(33%)停止了应用程序线程4秒钟或更长时间。
- 43个JVM( 14% )面临的最大GC暂停时间超过16秒
- 18个JVM( 6%)包含GC暂停时间超过一分钟
- 由于垃圾回收暂停,当前记录保存者设法将所有应用程序线程停止了16分钟以上。
我们确实承认我们的数据可能存在偏见-Plumbr最终监视的JVM更可能遭受触发更长GC暂停的性能问题。 因此,您需要花些力气才能得出这些结果,但是总的来说,发现仍然很有趣。 毕竟,对于那里的大多数应用程序,不能认为延迟增加了数十秒。
我们有几个假设,说明情况为何如此糟糕:
- 在第一种情况下,工程师甚至都没有意识到他们的应用程序性能如此差。 无法访问GC日志并与客户支持隔离开来可能完全使那些可能会改善情况的人员隐瞒问题
- 第二种情况是人们在努力重现问题。 与往常一样,寻求解决方案的第一步是在可以进行进一步实验的环境中构建可重现的测试用例。 当持久的GC暂停仅在生产环境中发生时,提出一个解决方案是一项艰巨的任务。
- 第三组问题落在意识到问题的工程师的肩膀上,他们甚至可以随意重现行为,但不知道如何实际改善情况。 调优GC是一项棘手的任务,需要大量有关JVM内部的知识,因此,在这种情况下,大多数工程师会陷入困境。
好消息是,我们正在努力使所有这些原因都过时-Plumbr发现表现不佳的GC问题,在发现这些问题时提醒您,并且更好地为您提供了量身定制的解决方案,以改善行为。 因此,您无需花费数周的反复试验,就可以在几分钟内浮出水面并解决这些案件。
翻译自: https://www.javacodegeeks.com/2014/10/revealing-the-length-of-garbage-collection-pauses.html

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









