





性能分析新机器
当我在新机器上工作时,我想了解它的局限性。 在这篇文章中,我将研究机器的抖动以及忙于等待本周末构建的新PC的影响。 机器的规格很有趣,但不是发布目的。 永远不要少:
- i7-3970X六核,运行频率为4.5 GHz(打开HT)
- 32 GB的PC-1600内存
- OCZ RevoDrive 3,PCI SSD(实际写入带宽为600 MB / s)
- Ubuntu 13.04
注意: OCZ RevoDrive在Linux上不受官方支持,但比其模型便宜得多。
测试抖动
我的微抖动采样器查看正在运行的线程的中断。 它与jHiccup相似,但是它没有测量线程唤醒的延迟,而是测量了线程一旦开始运行如何延迟的时间。 令人惊讶的是,线程的运行方式会影响唤醒后将看到的延迟类型。
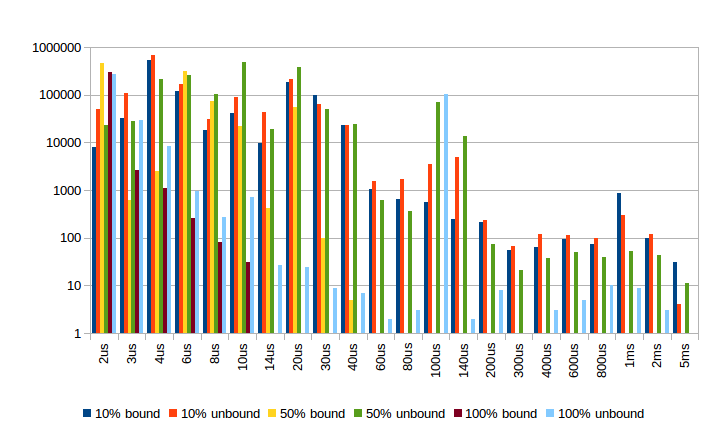
该图表有点密集。 它示出了一个CPU小时内发生的平均(每次测试运行多于两个时钟小时)有原始数据是可用的范围内的时间的中断的数量该处
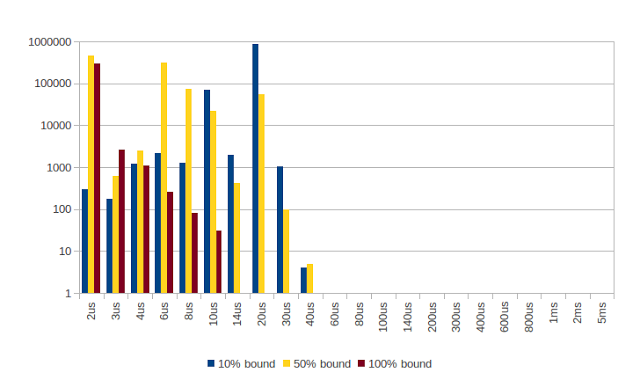
有趣的区别在于操作系统如何处理与隔离的CPU和/或繁忙的等待线程的绑定。
忙碌中
在繁忙等待的情况下,绑定到隔离的内核确实有助于减少较高的延迟差距。

这些测试同时运行。 唯一的区别是“绑定”线程绑定到“ isolcpus” CPU,该内核的其他CPU也被隔离。 即整个核心都是孤立的。
相当忙-50%
在这种情况下,线程在采样1毫秒和休眠1毫秒之间交替
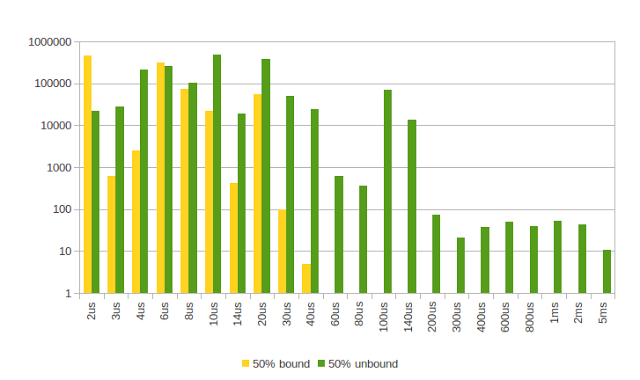
未绑定的50%繁忙线程的延迟要低得多,只有2微秒,但更长的延迟要多得多。
有点忙– 10%
在此测试中,采样器运行0.111毫秒,睡眠1毫秒。 即使在这种情况下,绑定到隔离的CPU也会有所不同。
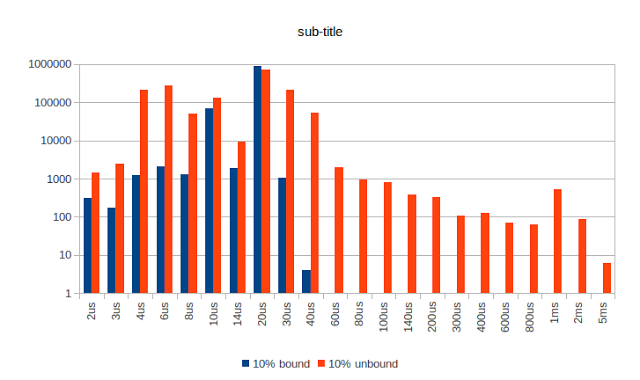
绑定但不隔离– 10%
在这种情况下,未隔离绑定线程。 它被绑定到一个CPU上,在该CPU上内核不是免费的,并且也不是孤立的。 与该测试中的未结合相比,单独结合似乎没有什么区别。
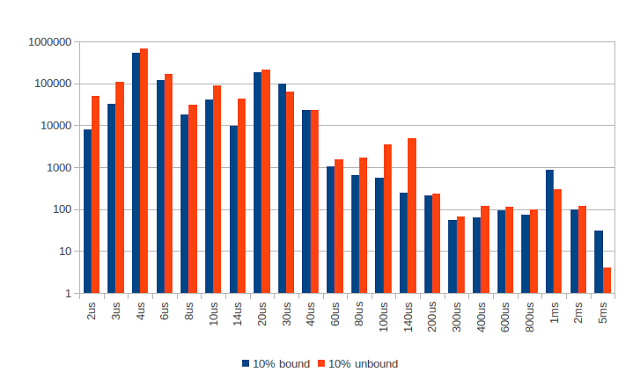
比较绑定线程和隔离线程
我以前见过的东西,但我发现有点奇怪,就是如果您放弃CPU,则线程唤醒时性能会很差。 以前,我已将缓存降低为未预热的时间,但是代码对内存的访问很少,并且代码非常短,因此仍然可能但不太可能。 以每小时一百万的速度在20微秒处达到峰值可能是由于每次唤醒时都会发生延迟。 这大约是90,000个时钟周期,对于高速缓存未命中来说似乎很多。
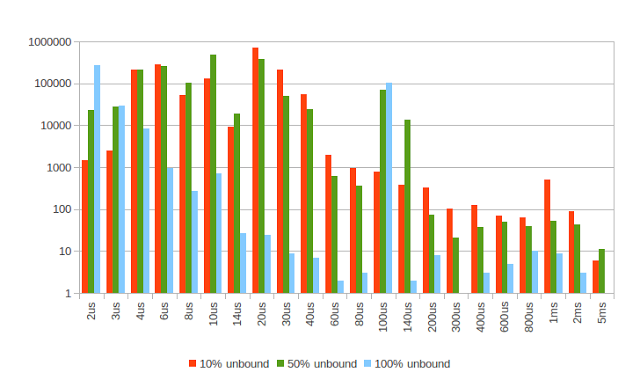
比较未绑定的线程
在此图表中,它暗示即使您没有被约束,对CPU的贪婪也确实有帮助。 繁忙的线程较少被中断。 很难说50%的忙比10%的忙更好。 可能是这样,但是需要更长的测试时间(我说这是在误差范围之内)
结论
在不隔离CPU的情况下使用线程相似性在此系统上似乎无济于事。 我怀疑其他Linux版本甚至Windows都是如此。 在亲和力和隔离性有帮助的地方,繁忙的等待仍然有意义,因为调度程序似乎会减少中断线程的次数(如果您这样做的话)。
翻译自: https://www.javacodegeeks.com/2013/07/micro-jitter-busy-waiting-and-binding-cpus.html















 8697
8697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









