





大多数性能问题可以通过几种不同的方式解决。 多数人都容易理解和应用许多适用的解决方案。 一些解决方案,例如从JVM管理的堆中删除某些数据结构,则更为复杂。 因此,如果您不熟悉此概念,我建议您继续学习我们最近如何减少应用程序的延迟,以及如何将Amazon AWS费用减少一半。
我将从解释需要解决方案的上下文开始。 如您所知, Plumbr密切关注每次用户交互。 这是使用部署在处理交互的应用程序节点旁边的代理来完成的。
这样做时,Plumbr代理正在从此类节点捕获不同的事件。 所有事件都发送到中央服务器,并组成我们称为事务的事务。 事务包含多个属性,包括:
- 交易的开始和结束时间戳;
- 执行交易的用户的身份;
- 执行的操作(将项目添加到购物车,创建新发票等);
- 该操作所属的应用程序;
在我们面临的特定问题的背景下,重要的是概述仅将对实际值的引用存储为事务的属性。 例如,不是存储用户的实际身份(例如电子邮件,用户名或社会保险号),而是在交易本身旁边存储对此类身份的引用。 因此,事务本身可能如下所示:
| ID | 开始 | 结束 | 应用 | 运作方式 | 用户 |
|---|---|---|---|---|---|
| #1 | 12:03:40 | 12:05:25 | #11 | #222 | #3333 |
| #2 | 12:04:10 | 12:06:00 | #11 | #223 | #3334 |
这些参考与对应的人类可读值对应。 通过这种方式,可以维护每个属性的键值映射,以便将ID为#3333和#3334的用户分别解析为John Smith和Jane Doe。
这些映射在运行时期间使用,当访问事务的查询将用人类可读的参考数据替换参考时:
| ID | 开始 | 结束 | 应用 | 运作方式 | 用户 |
|---|---|---|---|---|---|
| #1 | 12:03:40 | 12:05:25 | www.example.com | /登录 | 约翰·史密斯 |
| #2 | 12:04:10 | 12:06:00 | www.example.com | /购买 | 简·多伊 |
天真的解决方案
我敢打赌,我们的读者中的任何人都可以在不睁眼的情况下针对这种要求提出简单的解决方案。 选择一个喜欢的java.util.Map实现,将键值对加载到Map并在查询期间查找引用的值。
当我们发现我们选择的基础架构(具有存储在Kafka主题中的查找数据的Druid存储)已经通过Kafka查找开箱即用地支持此类Maps时,感觉容易的事情变得微不足道。
问题
幼稚的方法为我们服务了一段时间。 一段时间后,随着查找映射的大小增加,需要查找值的查询开始花费越来越多的时间。
我们在吃自己的狗粮并使用Plumbr监视Plumbr本身时注意到了这一点。 我们开始看到在Druid Historical节点上,GC暂停越来越频繁,而且更长,服务于查询并解决了查询。
显然,一些最有问题的查询必须从地图中查找超过100,000个不同的值。 这样做时,查询被GC启动打断,并超出了以前的100ms以下查询的持续时间,超过了10秒钟。
在寻找根本原因的同时,我们让Plumbr从此类有问题的节点公开了堆快照,确认长时间的GC暂停后大约70%的已用堆已被查找表完全消耗了。
同样明显的是,该问题还需要考虑另一个方面。 我们的存储层基于节点集群,集群中为查询提供服务的每台计算机都运行多个JVM进程,而每个进程都需要相同的参考数据。

现在,考虑到所讨论的JVM具有16G堆,并有效地复制了整个查找映射,因此这也成为容量规划中的一个问题。 支持越来越大的堆所需的实例大小开始在我们的EC2账单中付出了代价。
因此,我们不得不提出一种不同的解决方案,既减轻了垃圾收集的负担,又找到了降低Amazon AWS成本的方法。
解决方案:编年史地图
我们实施的解决方案基于Chronicle Map构建。 编年史地图在内存键值存储区中处于堆外状态。 正如我们的测试所示,存储的延迟时间也非常长。 但是,我们选择编年史地图的主要优点是它能够跨多个流程共享数据。 因此,除了将查找值加载到每个JVM堆之外,我们只能使用集群中不同节点访问的映射的一个副本:
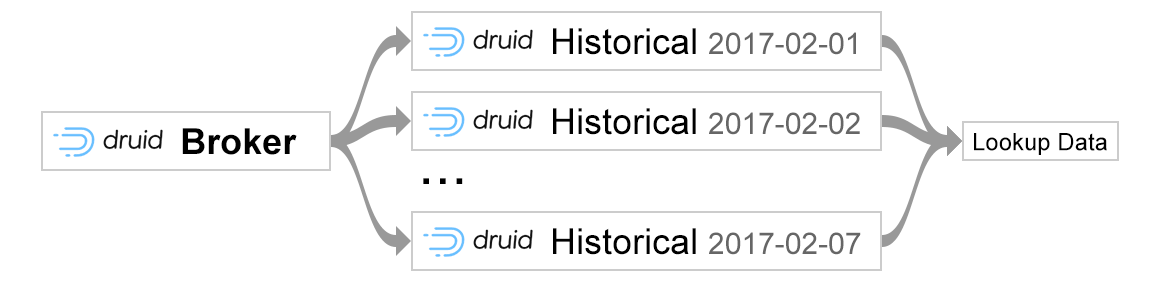
在进入细节之前,让我为您提供编年史地图功能的高级概述,我们发现它特别有用。 在编年史地图中,数据可以保存到文件系统中,然后由任何并发进程以“查看”模式访问。
因此,我们的目标是创建一个具有“编写者”角色的微服务,这意味着它将将所有必需的数据实时地持久存储到文件系统中,并作为“读取器”的角色(即我们的Druid数据存储)。 由于Druid不支持现成的Chronicle Map,因此我们实现了自己的Druid扩展 ,该扩展能够读取已经保存的Chronicle数据文件,并在查询期间用人类可读的名称替换标识符。 以下代码提供了一个示例,说明如何初始化编年史地图:
ChronicleMap.of(String.class, String.class)
.averageValueSize(lookup.averageValueSize)
.averageKeySize(lookup.averageKeySize)
.entries(entrySize)
.createOrRecoverPersistedTo(chronicleDataFile);在初始化阶段需要此配置,以确保Chronicle Map根据您预测的限制分配虚拟内存。 虚拟内存预分配不是唯一的优化,如果像我们一样将数据持久化到文件系统中,您会注意到创建的Chronicle数据文件实际上是稀疏文件 。 但这将是一个完全不同的帖子的故事,所以我不会深入探讨这些。
在配置中,您需要为尝试创建的编年史地图指定键和值类型。 在我们的例子中,所有参考数据都是文本格式,因此我们为键和值都指定了String类型。
在指定键和值的类型之后,Chronicle Map初始化还有更多有趣的部分是独特的。 正如方法名称所暗示的, averageValueSize和averageKeySize都要求程序员指定期望存储在Chronicle Map实例中的平均键和值大小。
使用方法条目,您可以为Chronicle Map提供可以存储在实例中的预期数据总数。 也许有人会怀疑,如果随着时间的推移,记录数量超过预定义的大小会发生什么? 显然,如果超过了配置的限制,则在最后输入的查询上性能可能会下降。
当超出预定义的条目大小时,还要考虑的另一件事是,如果不更新条目大小,则无法从Chronicle Map文件中恢复数据。 由于Chronicle Map在初始化期间会预先计算数据文件所需的内存,因此,如果条目大小保持不变,并且实际上文件中包含的内容(比如说多4倍的条目),则数据将无法容纳到预计算的内存中,因此Chronicle Map初始化将失败。 如果要在重启后正常运行,请务必牢记这一点。 例如,在我们的场景中,当重新启动持久化来自Kafka主题的数据的微服务时,在初始化Chronicle Map实例之前,它会根据Kafka主题中的消息数量动态计算数量条目。 这使我们能够在任何给定时间重新启动微服务,并使用更新的配置恢复已持久保存的Chronicle Map文件。
带走
使Chronicle Map实例能够在微秒内读写数据的各种优化立即开始产生良好的效果。在发布基于Chronicle Map的数据查询后几天,我们已经看到了性能改进:
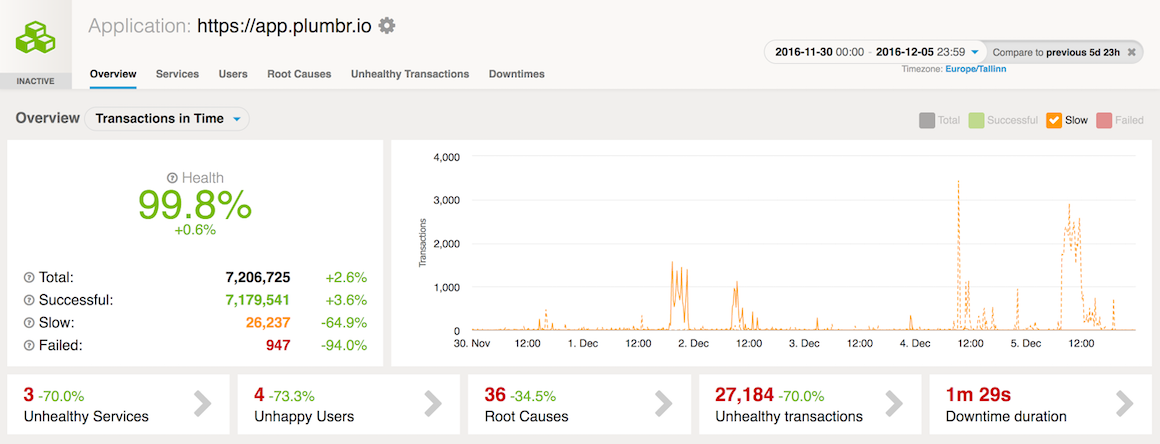
此外,从每个JVM堆中删除查找映射的冗余副本可以显着减少存储节点的实例大小,从而在我们的Amazon AWS账单中产生明显的凹痕。
翻译自: https://www.javacodegeeks.com/2017/02/going-off-heap-improve-latency-reduce-aws-bill.html














 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









