





 Apache Ignite的基线拓扑(Baseline Topology)是包含持久存储数据的服务器节点集合,用于数据恢复和管理集群扩展。本文通过实例介绍了如何创建、管理和监控基线拓扑,以及其在数据一致性、容错性和可伸缩性中的作用。通过使用`control.sh`命令行工具,可以激活、调整和监控集群的基线拓扑。
Apache Ignite的基线拓扑(Baseline Topology)是包含持久存储数据的服务器节点集合,用于数据恢复和管理集群扩展。本文通过实例介绍了如何创建、管理和监控基线拓扑,以及其在数据一致性、容错性和可伸缩性中的作用。通过使用`control.sh`命令行工具,可以激活、调整和监控集群的基线拓扑。
apache ignite
点燃基准拓扑或BLT代表群集中的一组服务器节点,这些服务器节点将数据持久存储在磁盘上。 
其中,N1-2和N5服务器节点是具有本机持久性的Ignite集群的成员,该集群使数据能够持久存储在磁盘上。 N3-4和N6服务器节点是Ignite群集的成员,但不是基准拓扑的一部分。
基线拓扑中的节点是常规服务器节点,该节点将数据存储在内存和磁盘中,并且还参与计算任务。 Ignite群集可以具有不属于基准拓扑的一部分的不同节点,例如:
- 未使用的服务器节点点燃本机持久性以将数据持久存储在磁盘上。 通常,它们将数据存储在内存中或将数据持久保存到第三方数据库或NoSQL。 在以上等式中,节点N3或N4可能是其中之一。
- 未存储的客户端节点共享数据。
为了更好地理解基线拓扑概念,让我们从头开始,尝试理解其目标以及它可以帮助我们解决什么问题。
像Ignite这样的数据库旨在支持大量数据存储和处理。 Ignite数据库具有高度可伸缩性和容错能力。 Ignite的这种高可伸缩性功能给数据库管理员带来了一些挑战,例如:如何管理集群? 如何正确添加/删除节点,或者添加/删除节点后如何重新平衡数据? 因为具有多个节点的Ignite群集会显着增加数据基础结构的复杂性。 让我们以Apache Ignite为例。
点燃内存模式集群的概念非常简单。 群集中没有主节点或专用节点,并且每个节点都相等。 每个节点存储分区的子集,并且可以参与分布式计算或部署任何服务。 如果任何节点发生故障,其他节点将服务于用户请求,并且故障节点的数据将不再可用。 Ignite群集管理操作非常相似,如下所示:
- 要运行集群,请启动所有节点。
- 要扩展群集拓扑,请添加一些节点。
- 要减少群集拓扑,请删除一些节点。
本文的某些部分摘自《 Apache Ignite》一书 。 如果您感兴趣,请查看本书的其余部分,以获取更多有用的信息。
数据自动在节点之间重新分配。 根据缓存的备份副本配置,数据分区从一个节点移动到另一个节点。
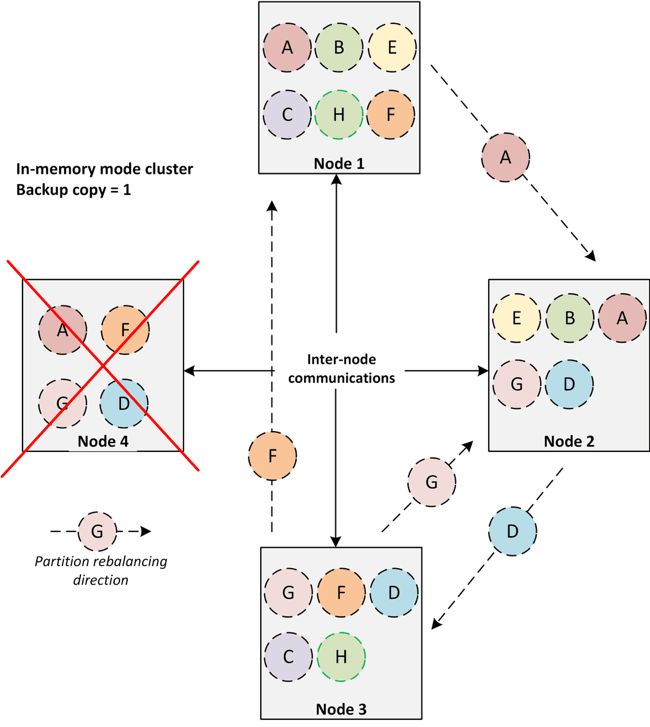
在持久性模式下,即使重新启动后,节点仍保持其状态。 在任何读取操作期间,都会从磁盘读取数据并恢复节点状态。 因此,与内存模式不同,以持久性模式重新启动节点不需要将数据从一个节点重新分发到另一个节点。 节点故障期间的数据将从磁盘恢复。 该策略不仅为防止节点故障期间移动大量数据提供了机会,而且还减少了重启后整个集群的启动时间。 因此,我们需要以某种方式区分这些可以在重启后保存其状态的节点。 换句话说,Ignite基线拓扑提供了此功能。
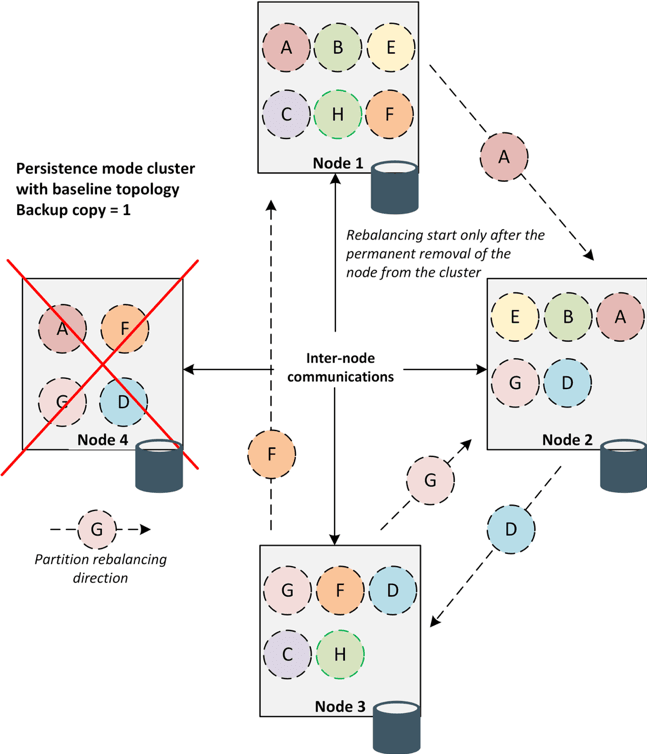
简而言之,Ignite基线拓扑是已配置用于在磁盘上存储持久性数据的节点的集合。 基线拓扑跟踪拓扑更改的历史记录,并在恢复过程中防止群集中的数据差异。 让我们继续基线拓扑的目标:
- 如果要重新引导节点,请避免冗余数据重新平衡。
- 群集重新启动后,一旦基线拓扑的所有节点都加入,便自动激活群集。
- 避免出现脑裂情况下的数据不一致。
Apache Ignite提供了一个命令行(CLI)工具,可用于监视和管理集群基准拓扑。 在本文中,我们将回顾使用Ignite持久性时使用此工具进行基准拓扑管理的几种常见方案。
可以在Apache Ignite发行目录的/ bin文件夹下找到./control.sh命令行脚本。 该脚本(工具)的主要目标是激活/停用和管理代表基线拓扑的一组节点。 但是,此工具是一种多功能工具,可以主动用于监视缓存状态或检测整个集群中可能发生的任何事务锁定。
准备沙箱。 如前所述,运行该工具的脚本位于{Ignite_home} / bin文件夹中,名为control.sh。 有用于Unix(control.sh)和Windows(control.bat)的脚本版本。 出于演示目的,我将使用以下配置:
| 名称 | 描述 |
|---|---|
| 操作系统 | MacOS,您可以选择使用Windows或Linux操作系统。 |
| 点燃版本 | 2.6.0或更高版本。 |
| 点火节点数 | 单个主机中的3个节点。 |
| 虚拟机 | 1.8 |
| TCP发现 | 多播 |
步骤1 。 我们将在持久模式下的单个主机上运行三个Ignite节点。 默认情况下,Ignite在IGNITR_HOME文件夹下创建一个WORK目录,用于存储WAL存档和日志文件。 下载Ignite发行版并将其解压缩到操作系统上的3个不同目录中,例如/usr/ignite/2.6.0-s1、/usr/ignite/2.6.0-s2、/usr/ignite/2.6.0-s3 。 您应该具有类似的文件夹层次结构,如图4所示。
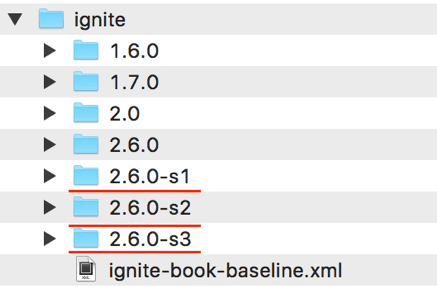
请注意,这是在单个主机上运行具有持久性启用功能的几个节点而无需任何额外配置的最简单方法。 但是,可以将Ignite配置为允许您运行具有不同WAL存档文件夹的几个Ignite节点。
第二步 。 为了启用持久性存储,我们通过Spring使用Ignite数据存储配置。 创建一个名称为ignite-book-baseline.xml的XML文件,并在其中复制以下内容。
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.springframework.org/schema/beans" xsi:schemalocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="TestCache">
<property name="atomicityMode" value="ATOMIC">
<property name="backups" value="1">
</property></property></property></bean>
</list>
</property>
<!-- Enabling Apache Ignite Persistent Store. -->
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true">
<property name="metricsEnabled" value="true">
</property></property></bean>
</property>
</bean>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder">
<property name="addresses">
<list>
<value>127.0.0.1:47500..47509</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
</bean>
</beans>将文件保存在文件系统中的某个位置。
第三步 。 从我们的第一个Ignite节点开始,我们将一次启动每个Ignite服务器节点。 打开终端,然后将IGNITE_HOME目录更改为您为Ignite节点1取消存档Ignite分发的文件夹。
export IGNITE_HOME=PATH_TO_THE_IGNITE_NODE_ONE/ignite/2.6.0-s1现在,使用以下命令启动第一个Ignite节点:
ignite.sh /PATH_TO_THE_SPRING_CONFIG_FILE/ignite/ignite-book-baseline.xml您在控制台上的输出应类似于以下内容:
ver. 2.6.0#20180710-sha1:669feacc
2018 Copyright(C) Apache Software Foundation
Ignite documentation: http://ignite.apache.org Quiet mode.
^-- Logging to file '/usr/ignite/2.6.0-s1/work/log/ignite-f0ef6ecc.0.log'
Topology snapshot [ver=1, servers=1, clients=0, CPUs=8, offheap=3.2GB, heap=1.\
^-- Node [id=F0EF6ECC-D692-4862-9414-709039FE00CD, clusterState=INACTIVE] Data Regions Configured:
^-- default [initSize=256.0 MiB, maxSize=3.2 GiB, persistenceEnabled=true]检查控制台上显示的日志,日志消息确认我们的第一台Ignite服务器已启动并正在运行,并且已启用持久性模式。 现在,对第二个Ignite节点再次执行相同的操作。
export IGNITE_HOME=PATH_TO_THE_IGNITE_NODE_ONE/ignite/2.6.0-s2
ignite.sh /PATH_TO_THE_SPRING_CONFIG_FILE/ignite/ignite-book-baseline.xml此时,您可以看到2nd Ignite节点以持久性模式启动并加入了集群。 您应该在终端中看到非常相似的消息,如下所示。
[16:13:35] >>> Ignite cluster is not active (limited functionality available). Use contro\ l.(sh|bat) script or IgniteCluster interface to activate.
[16:13:35] Topology snapshot [ver=2, servers=2, clients=0, CPUs=8, offheap=6.4GB, heap=2.\ 0GB]
[16:13:35] ^-- Node [id=6DB02F31-115C-41E4-BECC-FDB6980F8143, clusterState=INACTIVE] [16:13:35] Data Regions Configured:
[16:13:35] ^-- default [initSize=256.0 MiB, maxSize=3.2 GiB, persistenceEnabled=true]Ignite还警告说该集群尚未激活,您必须使用control.sh脚本激活该集群。 让我们激活集群并创建一些表来存储数据。
第四步 。 在激活集群之前,让我们考虑一下control.sh工具的特定功能。 control.sh脚本当前支持以下命令:
| 命令 | 描述 |
|---|---|
| -启用 | 该命令将集群切换为活动状态。 在这种情况下,如果集群中不存在基准拓扑,则将在集群激活期间创建新的基准。 新的基准拓扑将包括集群拓扑中的所有已连接节点。 |
| –停用 | 停用集群。 在这种状态下,功能有限。 |
| -州 | 打印当前集群状态。 |
| –基准 | 此命令旨在管理基准拓扑。 当不带任何参数使用此命令时,它将打印当前集群基准拓扑信息。 以下参数可与此命令一起使用:添加,删除,设置和版本。 |
要调用特定命令,请使用以下模式:
UNIX/LINUX/MacOS
$IGNITE_HOME/bin/control.sh现在,激活集群。 运行以下命令:
$IGNITE_HOME/bin/control.sh如果命令成功,您应该在控制台中看到以下消息。
Control utility [ver. 2.6.0#20180710-sha1:669feacc] 2018 Copyright(C) Apache Software Foundation
User: shamim
--------------------------------------------------------------------------------
Cluster activated此时,您还可以使用–state命令检查当前集群状态。 –state命令应返回一条消息,说明集群已激活。
步骤5 。 现在,创建一个表并填充一些数据。 我们使用SQLLINE工具连接到集群。 运行以下命令以启动SQLLINE工具:
sqlline.sh --color=true --verbose=true -u jdbc:ignite:thin://127.0.0.1/创建一个名为EMP的表,然后向该表中插入1000行。 使用以下DDL脚本创建EMP表,如下所示:
CREATE TABLE IF NOT EXISTS EMP
(
empno LONG, ename VARCHAR, job VARCHAR, mgr INTEGER, hiredate DATE,
sal LONG,
comm LONG,
deptno LONG,
CONSTRAINT pk_emp PRIMARY KEY (empno)
) WITH "template=partitioned,CACHE_NAME=EMPcache";接下来,使用GitHub存储库中的EMP_001.sql脚本在表中插入1000个条目。
0: jdbc:ignite:thin://127.0.0.1/> !run /PATH_TO_THE_FILE/the-apache-ignite-book/chapters/\ chapter-10/baseline/EMP_001.sql上面的命令将1000个条目插入EMP表或EMPcache。 使用visor CLI工具查看整个集群中缓存的大小。 在IgniteVisor控制台中运行命令cache -a。 该命令应返回以下输出,如图5所示。
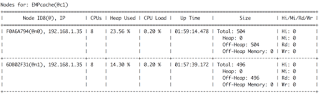
查看名为SIZE的列。 该列阐明了每个节点中存储的条目数。 在我们的例子中,我们的一个节点包含504个条目,另一个节点包含496个条目到EMPcache缓存中。
步骤6 。 到目前为止,我们仅启动了2个Ignite节点,并在集群中创建了基线拓扑。 让我们启动另一个Ignite节点。 对第3个Ignite节点再次执行相同的操作。
export IGNITE_HOME=PATH_TO_THE_IGNITE_NODE_ONE/ignite/2.6.0-s3
ignite.sh /PATH_TO_THE_SPRING_CONFIG_FILE/ignite/ignite-book-baseline.xml控制台上的日志应确认您已成功在持久性模式下启动节点。 此外,您应该在控制台上收到一条警告,即本地节点不包括在基准拓扑中,并且不会用于持久数据存储。 现在我们可以使用–baseline命令了。 让我们运行不带任何参数的命令,如下所示:
$IGNITE_HOME/bin/control.sh --baseline输出可能如下:
shamim:~ shamim$ control.sh --baseline
Control utility [ver. 2.6.0#20180710-sha1:669feacc] 2018 Copyright(C) Apache Software Foundation
User: shamim --------------------------------------------------------------------------------
Cluster state: active
Current topology version: 6
Baseline nodes:
ConsistentID=1640f655-4065-438c-92ca-478b5df91def, STATE=ONLINE ConsistentID=d8b04bc3-d175-443c-b53f-62512ff9152f, STATE=ONLINE
--------------------------------------------------------------------------------
Number of baseline nodes: 2
Other nodes: ConsistentID=3c2ad09d-c835-4f4b-b47a-43912d04d30e
Number of other nodes: 1上面的基线信息显示了群集状态,拓扑版本,具有一致ID的节点(属于基线拓扑的节点)以及不属于基线拓扑的节点。 在这里,基线节点数为2,基线由我们的第1个和第2个Ignite节点组成。
有时可能会发生在第一次集群激活期间未创建基线拓扑的情况。 在这种情况下,–baseline命令将返回“找不到基线节点”之类的消息。 在这种情况下,请停止第3个节点,并等待几秒钟。 然后,使用数字集群拓扑版本手动设置基线拓扑,如下所示:
control.sh --baseline version topologyVersion在上面的命令中,用实际的拓扑版本替换topologyVersion。 您可以在任何Ignite节点控制台中找到拓扑版本,如下所示:
Topology snapshot [ver=6, servers=3, clients=0, CPUs=8, offheap=9.6GB, heap=3.0GB]从控制台中选择最新的拓扑快照版本。
在此阶段,我们的第3个Ignite节点不是基线拓扑的一部分。 该节点将不用于持久数据存储。 这意味着,如果我们将创建任何新表并将数据插入其中,则该节点将不会为该新表存储任何数据。 让我们验证一下这个概念。
步骤7 。 使用以下DDL脚本创建一个新的表DEPT:
CREATE TABLE IF NOT EXISTS DEPT (
deptno LONG,
dname VARCHAR,
loc VARCHAR,
CONSTRAINT pk_dept PRIMARY KEY (deptno)
) WITH "template=partitioned,CACHE_NAME=DEPTcache";另外,使用DEPT.SQL插入100个部门。 DEPT.SQL脚本可从GitHub存储库中获得 。
0: jdbc:ignite:thin://127.0.0.1/> !run /PATH_TO_THE_FILE/github/the-apache-ignite-book/ch\ apters/chapter-10/baseline/DEPT.sql现在,在遮阳板控制台中运行命令cache -a,应打印类似图6所示的输出。
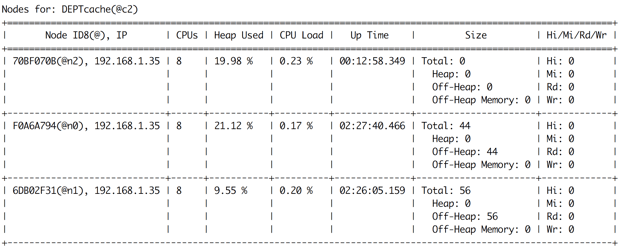
上图确认了第3个节点不包含任何持久性数据。 但是,不是基线拓扑一部分的节点可以参与任何内存计算。
步骤8 。 接下来,让我们将新的空节点添加到基准拓扑中以保存持久性数据。 调用命令–baseline add
将新节点添加到现有基准中。
control.sh --baseline add 3c2ad09d-c835-4f4b-b47a-43912d04d30e在以上命令中,将一致的ID 3c2ad09d-c835-4f4b-b47a-43912d04d30e替换为您的第3个Ignite节点的一致ID。 完成–baseline add命令后,将显示一条消息,确认新的基线拓扑包含3个节点。
Cluster state: active
Current topology version: 10
Baseline nodes:
ConsistentID=1640f655-4065-438c-92ca-478b5df91def, STATE=ONLINE
ConsistentID=3c2ad09d-c835-4f4b-b47a-43912d04d30e, STATE=ONLINE
ConsistentID=d8b04bc3-d175-443c-b53f-62512ff9152f, STATE=ONLINE
-------------------------------------------------------------------------------- Number of baseline nodes: 3
Other nodes not found.从3个节点形成新的基准拓扑后,将立即进行数据重新平衡。 新的空节点(在我们的示例中是第3个节点)将从其他节点接收其部分数据。 如果再次在Ignite Visor CLI中运行cache -a命令,则可以确认数据重新平衡。 图7显示了在基线拓扑中添加第三个节点后数据重新平衡的结果。
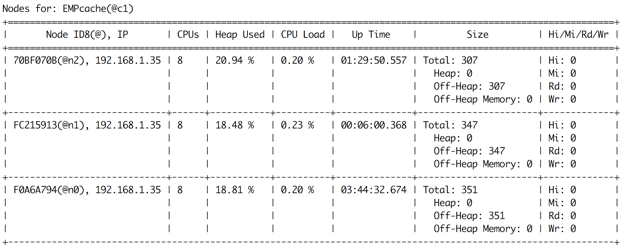
现在,每个节点几乎将条目的平均分配(约300个条目)存储在缓存EMPcache中。 但是,如果重新启动基线拓扑节点之一,将会发生什么? 让我们停止一个节点,然后尝试向表EMP中插入一些数据。
步骤9 。 按下CRTL + X键停止第二个节点。 执行不带任何参数的命令–baseline以打印基线拓扑的状态。
control.sh --baseline上面的命令将显示当前基线拓扑状态,与下一条消息非常相似:
--------------------------------------------------------------------------------
Cluster state: active
Current topology version: 11
Baseline nodes:
ConsistentID=1640f655-4065-438c-92ca-478b5df91def, STATE=OFFLINE
ConsistentID=3c2ad09d-c835-4f4b-b47a-43912d04d30e, STATE=ONLINE
ConsistentID=d8b04bc3-d175-443c-b53f-62512ff9152f, STATE=ONLINE
--------------------------------------------------------------------------------
Number of baseline nodes: 3
Other nodes not found预期脱机的节点之一。 现在,尝试通过SQLLINE工具将一些数据插入EMP表,如下所示:
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (2009, 'Sall\ ie', 'Sales Associate', 96, null, 3619, 34, 78);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (2010, 'Cori\ ', 'Human Resources Manager', 65, null, 1291, 86, 57);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (2011, 'Myrt\ le', 'VP Quality Control', 88, null, 5103, 21, 48);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (2012, 'Ches\ ', 'Desktop Support Technician', 46, null, 6352, 29, 21);您应该注意到,一些inserts语句失败,并带有错误,这些错误在下一个代码段中显示。
Caused by: class org.apache.ignite.internal.cluster.ClusterTopologyServerNotFoundExceptio\ n: Failed to map keys for cache (all partition nodes left the grid).
at org.apache.ignite.internal.processors.cache.distributed.dht.atomic.GridNearAtomicSing\ leUpdateFuture.mapSingleUpdate(GridNearAtomicSingleUpdateFuture.java:562)发生此错误是因为我们没有EMP表的备份副本。 应该存储数据的节点已停止,并且Ignite无法存储数据。 为避免这种情况,请考虑使用一个备份的缓存/表。 如果一个节点发生故障,它将不会丢失任何数据。 目前,我们有几种选择:
- 尽快重启离线节点,以最小的停机时间来防止数据丢失。
- 从基准拓扑中删除脱机节点并重新平衡数据。
第十步 。 让我们从基准拓扑中删除脱机节点。 执行以下命令:
Caused by: class control.sh --baseline remove 1640f655-4065-438c-92ca-478b5df91def完成remove命令后,基线拓扑发生了变化,但停止的节点除外。 请注意,通过从基准拓扑中删除节点,您确认您将无法在重新启动该节点后使用该节点上存储的数据。 此时,在对集群进行数据操作期间不会发生任何错误。 您可以成功插入新条目或将现有条目更新到缓存中。
请注意,要从基准拓扑中删除的节点应从群集断开,然后再从基准中删除。 否则,将出现错误“无法从基准删除节点”,该错误指定在从基准删除之前必须停止的节点。
除了拓扑管理之外,control.sh脚本还可以用于监视和控制群集状态,该状态在Ignite站点中有详细记录。 因此,请参考Ignite文档的控制脚本部分以获取更多信息。
翻译自: https://www.javacodegeeks.com/2018/12/apache-ignite-baseline-topology-examples.html
apache ignite















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









