





hadoop lambda
最近,一群人要求我详细介绍我为我们的书《分布式实时计算的风暴蓝图》撰写的Druid / Storm集成。 德鲁伊很棒。 风暴很棒。 两者一起解决了实时维查询/聚合问题。
实际上,人们正在将其视为主流,称其为RAD Stack ,并添加了“ Lambda Architecture”标签。 老实说,也许有更好的方法。 Lamda Architectures的以下假设一直困扰着我。
摘自Nathan关于Lambda Architectures的文章 :
实时计算任意数据集上的任意函数是一个艰巨的问题。 没有哪个工具可以提供完整的解决方案。 相反,您必须使用各种工具和技术来构建完整的大数据系统。
lambda体系结构将问题分解为三层:批处理层,服务层和速度层,从而解决了实时计算任意数据上任意函数的问题。
该建议使大多数人为批处理,速度/处理和查询部署了单独的基础架构/框架,这是很好的,因为它允许您“为每个作业使用正确的工具”。 这导致了诸如“ RAD Stack”之类的问题。 人们为每一层选择一种技术。 (例如,速度=风暴,批处理= Hadoop和服务= Impala)
但是,如果您生活在这样的环境中,则它们需要大量资源,因为整个系统之间的重复使用很少。 我相信人们越来越开始怀疑各层之间的区别 。 其他人则提出了统一Lambda架构 。
最近,我发现自己处于统一主义者的阵营中……
在HMS,几年来我们一直在迭代Lambda架构。 我们有Storm,Hadoop和实时Web服务层。 这些功能均充当数据摄取机制。
它们都处理相同类型的数据,并且仅在接口,容量和客户端期望方面有所不同:
- 交易处理:
- 我们的事务处理是我们的Web服务层。
- 基于流/队列的处理
- 通常,我们发现自己更多地依赖于我们的事务处理能力。
- 批量处理
- 对于批处理,客户的期望甚至进一步降低。
像许多其他人一样,我们发现自己需要支持所有这些范例。 从字面上看,我们正在跨不同的框架/系统重写代码,当这些实现不同时(甚至略有不同),这会造成很大的麻烦。 数字没有排队,等等。
我们被迫提出一个解决方案,并使系统稍微崩溃。
我们用Storm看了DRPC,并考虑了从我们的Web服务层调用Storm,但是DRPC似乎很笨拙,并且没有得到支持。 而且,从Hadoop调用DRPC似乎是不明智的。 (有人尝试过吗?)
相反,我们决定锁定持久性的抽象。 我们环顾了ORM和DAO模式,但大多数都不支持微批处理的概念,这是一种抽象,我们希望该选项可以在不同的处理机制中加以利用。 最后, 我们决定将风暴/突发状态抽象作为持久性的通用机制。 我们构建了storm-cassandra-cql ,并将其嵌入到我们的Web服务和Hadoop中。
从Hadoop和我们的Web服务中,我们实例化了自己的元组,它们实现了Storm Tuple接口。 从那里,我们可以使用State抽象并重新使用Mappers,以确保所有三个处理范例之间的数据模型均一致。
作为一种快捷方式,在Hadoop中,我们直接在reduce阶段使用State对象,将输出格式设置为NullOutputFormat。 理想情况下,我们可能应该实现一个新的OutputFormat,即StormCassandraCqlFormat之类的东西,但是我不确定这会给我们带来很多好处。
对于Web服务,直接集成是直接的。 将JSON转换为元组,在StateUpdater上调用update(),然后在State对象上调用commit()。 但是我们还希望能够在提交到“深度存储”之前进行批处理并执行维度聚合。 这就引入了一个问题,我们将拥有已确认(200个响应代码)但尚未持久的数据。 不好。 如果节点发生故障,我们将丢失数据。 真的不好。
那么,解决方案是什么? 我们本可以集成Druid,但是相反,我们决定保持它的轻便,并…利用Storm作为我们的安全网!
考虑以下对Lambda体系结构的“传统”解释:
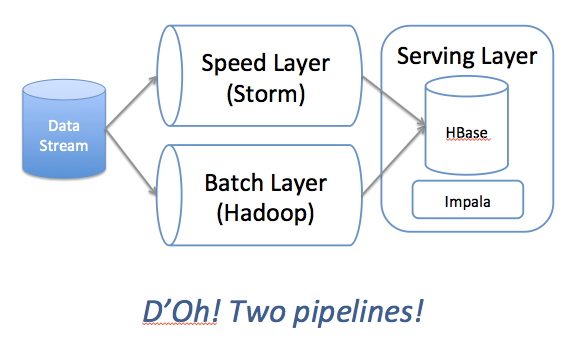
在这种传统方法中,批处理层(Hadoop)通常用于“纠正”速度层(Storm)中引入的处理中的错误。 Hadoop是安全网,可以纠正数字(通常是通过通宵的批处理作业),我们决定采用这种方法来翻转该模型,并使用Storm作为我们的安全网:
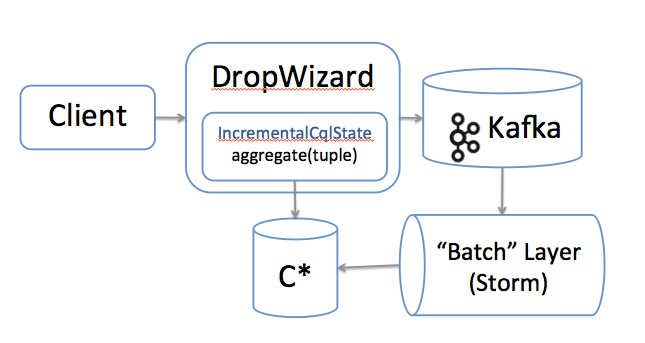
在这种情况下,我们使用嵌入式State对象在批处理中聚合数据,但是在确认HTTP请求之前,我们还写入Kafka队列以实现持久性。 序列图如下所示:
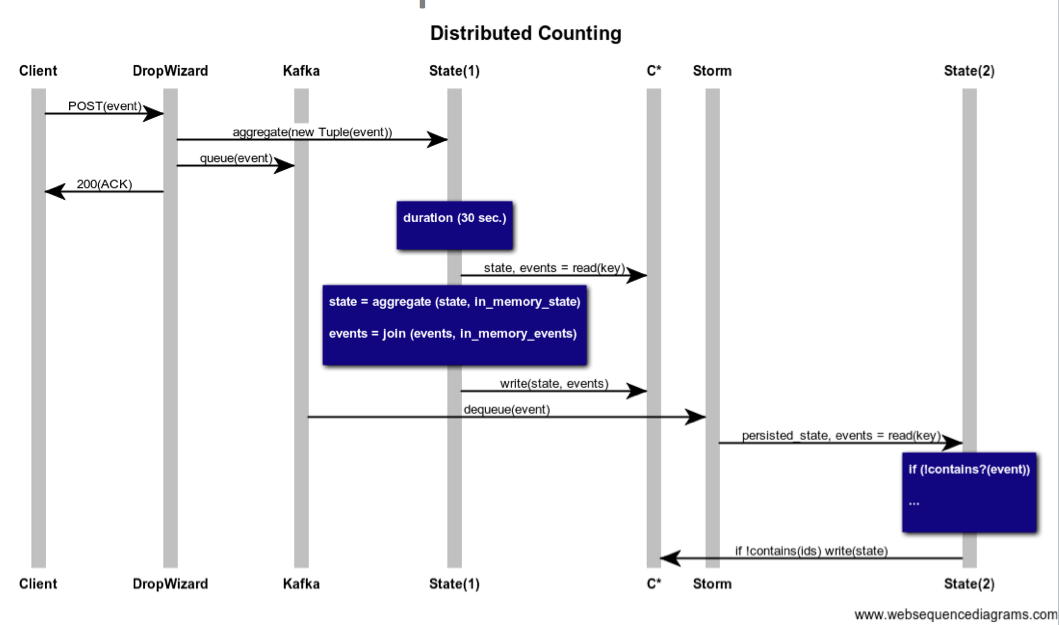
我们将事件持久化到队列中,更新“三叉戟状态”对象,然后*然后*返回200。然后,定期将状态刷新到存储。 (在这种情况下为Cassandra),如果我们删除节点也是可以的,因为Storm最终将最终(重新)处理事件并在需要时(重新)合并数据。 (这是我要掩盖一些非常重要的细节的地方,将在下一篇文章中解决)
关键是……我们已经开始从持久性开始崩溃。 我们正在重新使用Hadoop和Web服务中的Trident State抽象,并且已经将Storm移到了“重新处理/安全网”层,该层以前由Hadoop /批处理填充。
由于缺乏更好的术语,我们一直将其称为Delta体系结构,因为整个系统都集中于根据任何和所有处理范例进行的状态增量更新。
希望这能使人们思考。 在我的下一篇文章中,我将解释如何使用相同的体系结构交付维度聚合(如Druid),而无需直接合并Druid。
我们也有未解决的问题-
我们可以执行嵌入式拓扑吗?
这样做有意义吗?
有关更多详细信息,请查看我在Storm NYC聚会中所做的演示, 数据管道和Lambda体系结构的改进 。
我完全理解Lambda的大部分内容只是一个视角问题。 FWIW –这是我的(当前–可能会更改=)。 多亏了内森(Nathan)阐明了Lambda架构的概念,实现“大数据”视图已使人们有了共同的语言,可以与他们讨论一些真正棘手的问题的解决方案。
hadoop lambda















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









