









1.聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到数字的总和,不是数字无意义 |
| AVG([DISTINCT] expr) | 返回查询到数字的平均值,不是数字无意义 |
| MAX([DISTINCT] expr) | 返回查询到数字的最大值,不是数字无意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
测试:

这个函数在执行时间和select一起执行。count计数时会自动剔除空字段。

2.使用在select语句中group by语句对指定列进行分组查询
select column1, column2, .. from table group by column;
这里使用scott_data.sql测试数据库
-- 1、建dept表
create table dept(
DEPTNO INT(2) NOT NULL PRIMARY KEY,
DNAME VARCHAR(14),
LOC VARCHAR(13)
);
-- 2、建emp表
CREATE TABLE emp(
EMPNO INT(4) NOT NULL PRIMARY KEY,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR NUMERIC(4),
HIREDATE DATETIME,
SAL NUMERIC(7,2),
COMM NUMERIC(7,2),
DEPTNO INT(2)
);
-- 3、建salgrade表
CREATE TABLE salgrade (
GRADE NUMERIC,
LOSAL NUMERIC,
HISAL NUMERIC
);
-- 4、建bonus表
CREATE TABLE bonus(
ENAME VARCHAR(10),
JOB VARCHAR(9),
SAL NUMERIC,
COMM NUMERIC
);
-- 5、在dept中插入数据
INSERT INTO dept VALUES (10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept VALUES (20, 'RESEARCH', 'DALLAS');
INSERT INTO dept VALUES (30, 'SALES', 'CHICAGO');
INSERT INTO dept VALUES (40, 'OPERATIONS', 'BOSTON');
-- 6、在emp中插入数据
INSERT INTO emp VALUES (7369, 'SMITH', 'CLERK', 7902, '1980-12-17',800,NULL,20);
INSERT INTO emp VALUES (7499, 'ALLEN', 'SALESMAN', 7698, '1981-2-20',1600,300,30);
INSERT INTO emp VALUES (7521, 'WARD', 'SALESMAN', 7698, '1981-2-22',1250,500,30);
INSERT INTO emp VALUES (7566, 'JONES', 'MANAGER', 7839, '1981-4-2',2975,NULL,20);
INSERT INTO emp VALUES (7654, 'MARTIN', 'SALESMAN', 7698, '1981-9-28',1250,1400,30);
INSERT INTO emp VALUES (7698, 'BLAKE', 'MANAGER', 7839, '1981-5-1',2850,NULL,30);
INSERT INTO emp VALUES (7782, 'CLARK', 'MANAGER', 7839, '1981-6-9',2450,NULL,10);
INSERT INTO emp VALUES (7788, 'SCOTT', 'ANALYST', 7566, '1987-4-19',3000,NULL,20);
INSERT INTO emp VALUES (7839, 'KING', 'PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp VALUES (7844, 'TURNER', 'SALESMAN', 7698, '1981-9-8',1500,0,30);
INSERT INTO emp VALUES (7876, 'ADAMS', 'CLERK', 7788, '1987-5-23',1100,NULL,20);
INSERT INTO emp VALUES (7900, 'JAMES', 'CLERK', 7698, '1981-12-3',950,NULL,30);
INSERT INTO emp VALUES (7902, 'FORD', 'ANALYST', 7566, '1981-12-3',3000,NULL,20);
INSERT INTO emp VALUES (7934, 'MILLER', 'CLERK', 7782, '1982-1-23',1300,NULL,10);
-- 7、在salgrade中插入数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
-- 8、bonus表中无数据
选用上表进行练习,将备份还原后如下图:

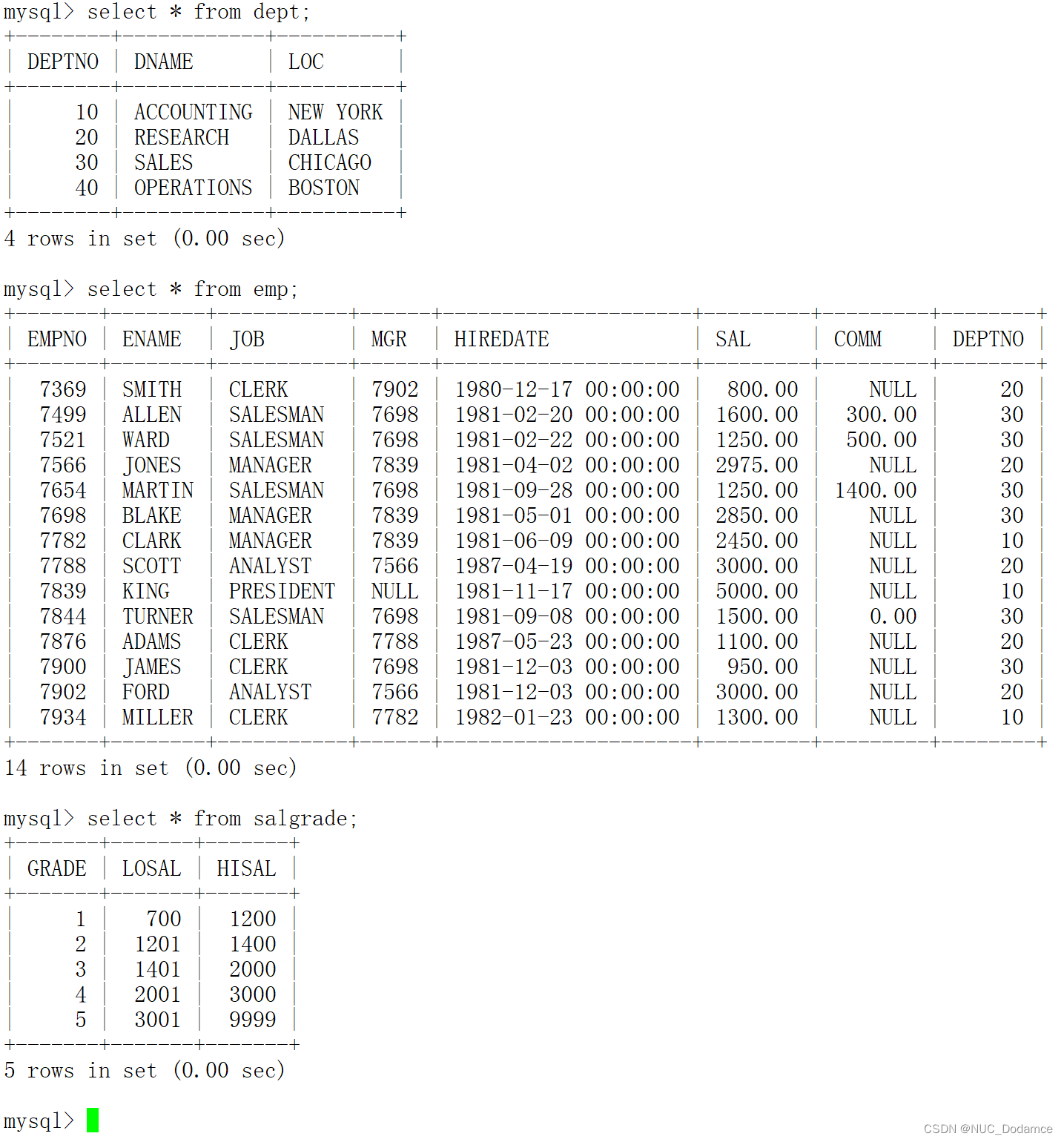
其中:
- emp员工表
- dept部门表
- salgrade工资等级表
练习:
1. 显示每个部门的平均工资和最高工资
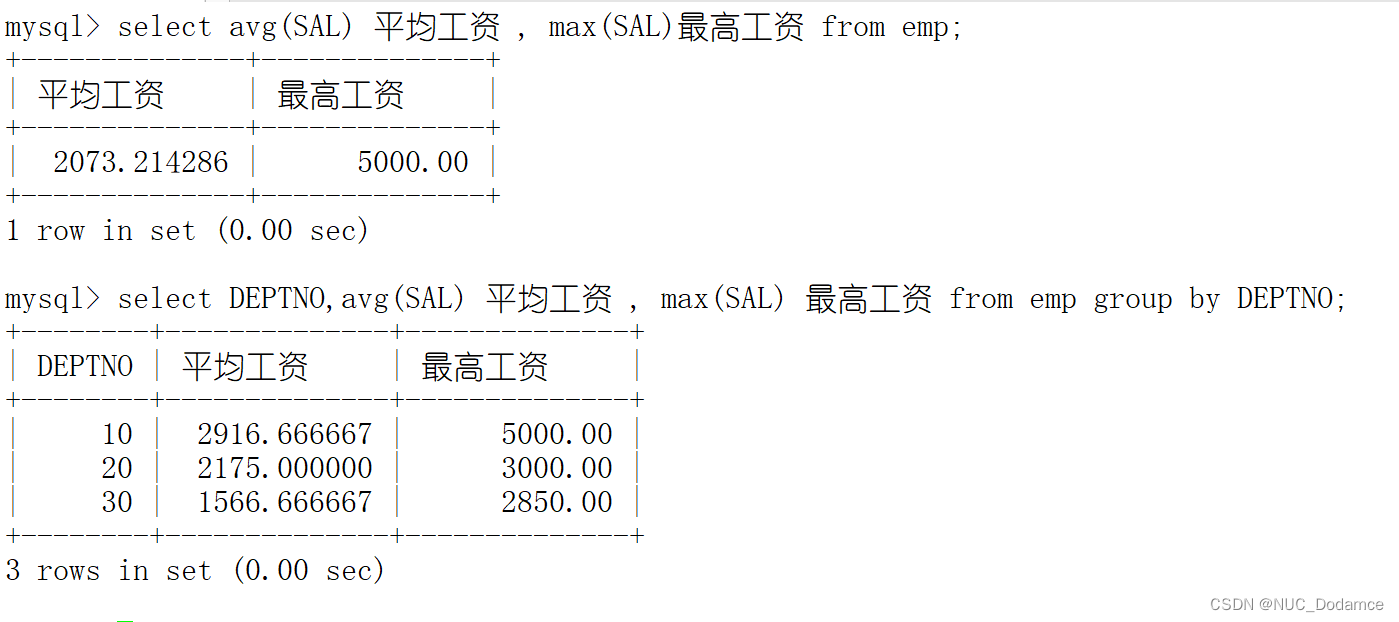
先将筛选的信息按照工资水平进行分组,之后再统计每组的平均工资和最高工资。
2.显示每个部门的每种岗位的平均工资和最低工资
先按照部门分组,每个部门有多种的岗位。
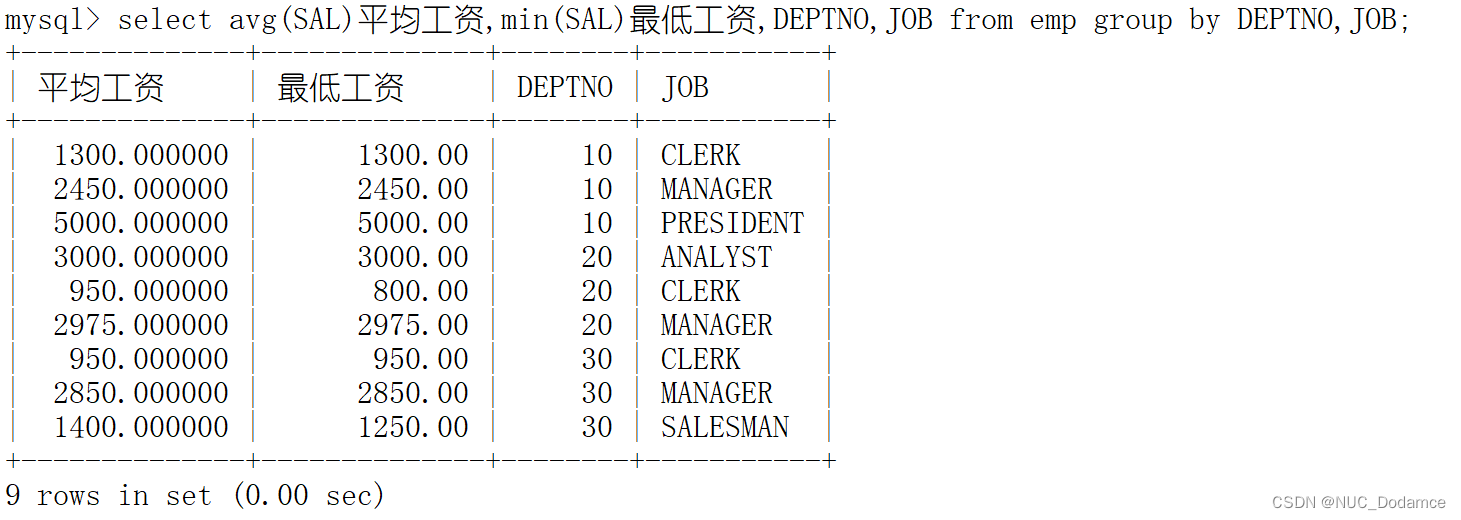
规定:如果要使用group by 的话凡是在select语句出现的原表列,必须在group by中出现,否则可能会报不支持错误。

错误信息为:
Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column ‘dodamce_test.emp.JOB’ which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
需要修改配置文件解决。
3.显示平均工资低于2000的部门和它的平均工资

如上图,已经获取到了部门的平均薪资,但这时候不能使用where来进行筛选,因为where选择适合select搭配使用的。
对数据分组完后的数据在进行查询使用having字段
因为having一定在select后执行,所以可以直接使用重命名的列来判断。

















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











