







1.正则表达式常见内容
修饰符
- re.I使匹配对大小写不敏感
- re.L做本地化识别匹配
re.L:使用当地locale。(python中有个locale模块,locale代表不同的语言,地区和字符集)由当前语言区域决定\w, \W, \b, \B和大小写敏感匹配。这个标记只能对byte样式有效。这个标记不推荐使用,因为语言区域机制很不可靠,它一次只能处理一个"习惯” - re.M多行匹配,影响^和$
- re.S使匹配包括换行在内的所有字符(常用)
- re.U根据Unicode字符集解析字符.这个标志影响\w \w \b \B(Python 2需要通过re.U匹配中文)
- re.X该标志通过给予你更灵活的格式以便你将正则表达式写的更易于理解.
简单的理解就是正则表达式的匹配模式
re.S首先将所有的HTML代码写成一行,方便正则表达式书写
元字符
- \d匹配任何十进制数。
- \D匹配任何非数字字符。
- \s匹配任何空白字符。(\t、空格、\n都属于空白字符)
- \S匹配任何非空白字符。
- \w匹配任何字母(包括汉字)或数字字符。(特殊字符:!@#¥%……&*等等这类字符不匹配)
- \W匹配任何非字母或数字字符。
findall函数
查找字符串中满足正则表达式的字符
pattern:查找的正则表达式
string:查找的字符串
flags:模式,一般默认即可
eg:
import re
Str = "0test4\n\tji1awda6dn7iq10"
print(re.findall('\d', Str)) # \d匹配任何十进制数
print(re.findall('\D', Str)) # \D匹配任何非数字字符
print(re.findall('\s', Str))
print(re.findall('\w', "123sadiw你好\n!@#$%^^&*【"))

数量修饰符
- .代表通配符,除了\n不能匹配外,其它全部都能匹配,一个点代表一个字符
- ^代表字符串开头进行匹配,只能放在最前面
- $代表字符串结尾进行匹配,只能放在最后面
- *代表0到无穷次
- +代表1次到无穷次
- ?代表0次到1次
- {}代表自行控制多少次,{0}== *,{1,}== +,{0,1}== ?,{6}代表6次,{1,6}代表1,2,3,4,5,6次
- []代表字符集,或的作用
注意:前面的 *、 +、?等都是贪婪匹配,也就是尽可能多的匹配,后面加?号使其变成惰性匹配,比如 +?匹配1个 字符
Str = "a1c a2c a3c abc abdc"
print(re.findall('a1c', Str))
print(re.findall('a.c', Str))
print(re.findall('a..c', Str))
print(re.findall('a.*?c', Str))
print(re.findall('a.*c', Str))

重点样例:
Str = "0test4\n\tji1awda6dn7iq10"
print(re.findall('\d', Str))
print(re.findall('\d*', Str))
print(re.findall('\d+', Str))

Str = "ac abc abbc abbbc a!c adddc"
print(re.findall('a.{1,2}c', Str))
print(re.findall('a[abc]c', Str)) # 匹配ac之间有a,b,c字符的字符串,这些字符只能出现一个
print(re.findall('a[abc][b]c', Str))

注意:
- 使用()将修饰符括起来代表提取匹配内的文字
Str = '<meta charset= "UTF-8">'
print(re.findall('<meta charset= ".*">', Str))
print(re.findall('<meta charset= "(.*)">', Str))

match、search函数
match从开始位置开始查找,如果匹配则返回一个位置对象。
search与match函数用法类似。区别,多次调用时search函数只会查找一次,找到后直接返回。match继续上次查找位置查找多次。(不常用)
findall是从字符串所有位置查找
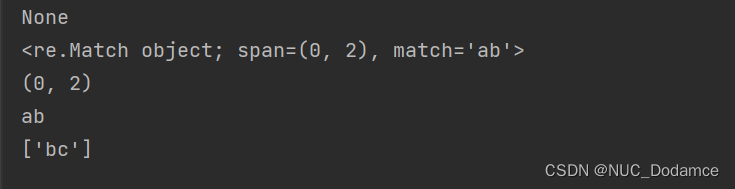
Str = "abcde1234"
print(re.match('dc', Str))
print(re.match('ab', Str))
data = re.match('ab', Str)
print(data.span())
print(data.group())
print(re.findall('bc', Str))
2.练习:用正则表达式判断身份证号是否正确
中国居民身份证号码编码规则
第一、二位表示省(自治区、直辖市、特别行政区)。
第三、四位表示市(地级市、自治州、盟及国家直辖市所属市辖区和县的汇总码)。其中,01-20,51-70表示省直辖市;21-50表示地区(自治州、盟)。
第五、六位表示县(市辖区、县级市、旗)。01-18表示市辖区或地区(自治州、盟)辖县级市;21-80表示县(旗);81-99表示省直辖县级市。
第七、十四位表示出生年月日(单数字月日左侧用0补齐)。其中年份用四位数字表示,年、月、日之间不用分隔符。例如:1981年05月11日就用19810511表示。
第十五、十七位表示顺序码。对同地区、同年、月、日出生的人员编定的顺序号。其中第十七位奇数分给男性,偶数分给女性。
第十八位表示校验码。作为尾号的校验码,是由号码编制单位按统一的公式计算出来的,校验码如果出现数字10,就用X来代替,详情参考下方计算方法。
- 其中第一代身份证号码为15位。年份两位数字表示,没有校验码。
- 前六位详情请参考省市县地区代码
- X是罗马字符表示数字10,罗马字符(1-12):Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ、Ⅵ、Ⅶ、Ⅷ、Ⅸ、Ⅹ、Ⅺ、Ⅻ……,详情请参考罗马字符
xxxxxx yyyy MM dd 375 0 十八位
地区-----年----月–日-3位顺序码-校验码
xxxxxx yy MM dd 75 0 十五位
地区—年—月–日-3位顺序码,无校验码
- 将身份证号码前面的17位数分别乘以不同的系数。从第一位到第十七位的系数分别为:7-9-10-5-8-4-2-1-6-3-7-9-10-5-8-4-2。
- 将这17位数字和系数相乘的结果相加。
- 用加出来和除以11,取余数。
- 余数只可能有0-1-2-3-4-5-6-7-8-9-10这11个数字。其分别对应的最后一位身份证的号码为1-0-X-9-8-7-6-5-4-3-2。
- 通过上面计算得知如果余数是3,第18位的校验码就是9。如果余数是2那么对应的校验码就是X,X实际是罗马数字10。
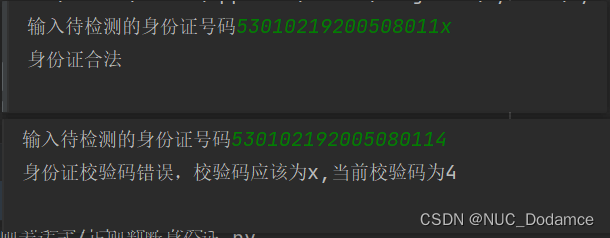
eg:例如:某男性的身份证号码为【53010219200508011x】, 我们看看这个身份证是不是合法的身份证。首先我们得出前17位的乘积和【(5×7)+(3×9)+(0×10)+(1×5)+(0×8)+(2×4)+(1×*2)+(9×1)+(2×6)+(0×3)+(0×7)+(5×9)+(0×10)+(8×5)+(0×8)+(1×4)+(1×2)】是189,然后用189除以11得出的结果是189/11=17----2,也就是说其余数是2。最后通过对应规则就可以知道余数2对应的检验码是X。所以,可以判定这是一个正确的身份证号码。
import re
Str = str(input('输入待检测的身份证号码'))
len_str = len(Str)
isEagle = False
'''
xxxxxx yyyy MM dd 375 0 十八位
地区-----年----月--日-3位顺序码-校验码
xxxxxx yy MM dd 75 0 十五位
地区---年---月--日-2位顺序码-校验码
# 假设18位身份证号码:41000119910101123X 410001 19910101 123X
# ^开头
# [1-9] 第一位1-9中的一个 4
# \\d{5} 五位数字 10001(前六位省市县地区)
# (18|19|20) 19(现阶段可能取值范围18xx-20xx年)
# \\d{2} 91(年份)
# ((0[1-9])|(10|11|12)) 01(月份)
# (([0-2][1-9])|10|20|30|31)01(日期)
# \\d{3} 三位数字 123(第十七位奇数代表男,偶数代表女)
# [0-9Xx] 0123456789Xx其中的一个 X(第十八位为校验值)
# $结尾
# 假设15位身份证号码:410001910101123 410001 910101 123
# ^开头
# [1-9] 第一位1-9中的一个 4
# \\d{5} 五位数字 10001(前六位省市县地区)
# \\d{2} 91(年份)
# ((0[1-9])|(10|11|12)) 01(月份)
# (([0-2][1-9])|10|20|30|31)01(日期)
# \\d{3} 三位数字 123(第十五位奇数代表男,偶数代表女),15位身份证不含X
# $结尾
'''
key_18 = re.compile('^[1-9]\d{5}(18|19|20)\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$')
key_15 = re.compile('^[1-9]\d{5}\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}$')
# 验证身份证结构是否合法,如果18位还需要验证校验位
if len_str == 15 or len_str == 18:
if len_str == 15 and re.match(key_15, Str):
isEagle = True
elif len_str == 18 and re.match(key_18, Str):
# 前十七位加权因子
var = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
# 除以11后,可能产生的11位余数对应的验证码
var_id = ['1', '0', 'x', '9', '8', '7', '6', '5', '4', '3', '2']
ret = 0
for i in range(0, 17):
ret += int(Str[i]) * var[i]
ret %= 11
if var_id[ret] != Str[-1].lower():
print(f'身份证校验码错误,校验码应该为{var_id[ret]},当前校验码为{Str[-1]}')
else:
isEagle = True
else:
print('身份证不合法,位数错误,请检查重试')
if isEagle:
print('身份证合法')
else:
print('身份证不合法')
















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











