






在度量传输质量(以做出某种预测)时,我们有不同的指标,它们具有不同的单位,不同的作用范围,不同的平均方法,不同的采集方法,因此需要一种统一的方法,以做到整合这些复杂的信息:
- 跨指标评估
- 跨主体比较
- 跨量纲分析
- 只区分正向和负向作用
- 跨量纲加强和减弱效应
目的是获得早起预警信号以及辅助决策制定。
时间和空间是渐变的,世界由于时间和空间的局部性也是渐变的,因此我们可以通过画像看到它代表的真实的东西。
在经济学领域,画像一般通过指数描述,指数消除了量纲,采用单一的指数曲线描述趋势非常方便。其实在任何以统计学为基础的领域,如气象学,社会学,互联网,底层逻辑相当一致,在网络传输领域,也有类似方法。
与具体某个指标相比,指数更具稳定性,它是多个因素共同作用的结果,当所有因素同向移动时,往往预示着背后某种原因正在产生结果,而单独某个指标甚至几个指标的异变往往无法直接改变指数,便可理所当然地当做噪声忽略。
此前我将 E = bw / delay 作为整体效能一起考虑两个因素就是这个意思,如今我将它再度扩展成指数。
以这类思想为基础,构建一个传输质量评价体系是合理的,该评价体系可作为传输优化的指导,影响传输协议的行为甚至迭代传输协议本身。
本文只描述思想,以 “拥塞指数”,“突发指数”,“随机丢包指数”,“Good 指数” 作为示例。下面简单介绍如何配置和应用评价体系的相关指标的指数。分以下步骤:
- 抽取指标的显式特征,如拥塞状态下时延一定大,时延方差却不一定大,故时延是显式特征,时延方差不是;
- 将 “一定小” 的显式特征用 sigmoid 减函数转换成 “一定大”,并将特征度量映射到 [0, 2] 或 [0, 1] 区间;
- 经重新映射的 “一定大” 的特征叫做 “阳性特征”;
- 选择另一个数学函数 f(v1, v2, v3, …),满足 “所有 ‘一定大’ 的阳性特征都 ‘足够大’ 时,f(x) 显著升高,否则保持低”;
- 调所有函数(比如 sigmoid,f(…))的参数,很难但很有趣。
依据在于,当且仅当所有显式特征均为阳性,才能判定病症。下面一个简单的 poc case 中,我使用以下的 sigmod 函数:
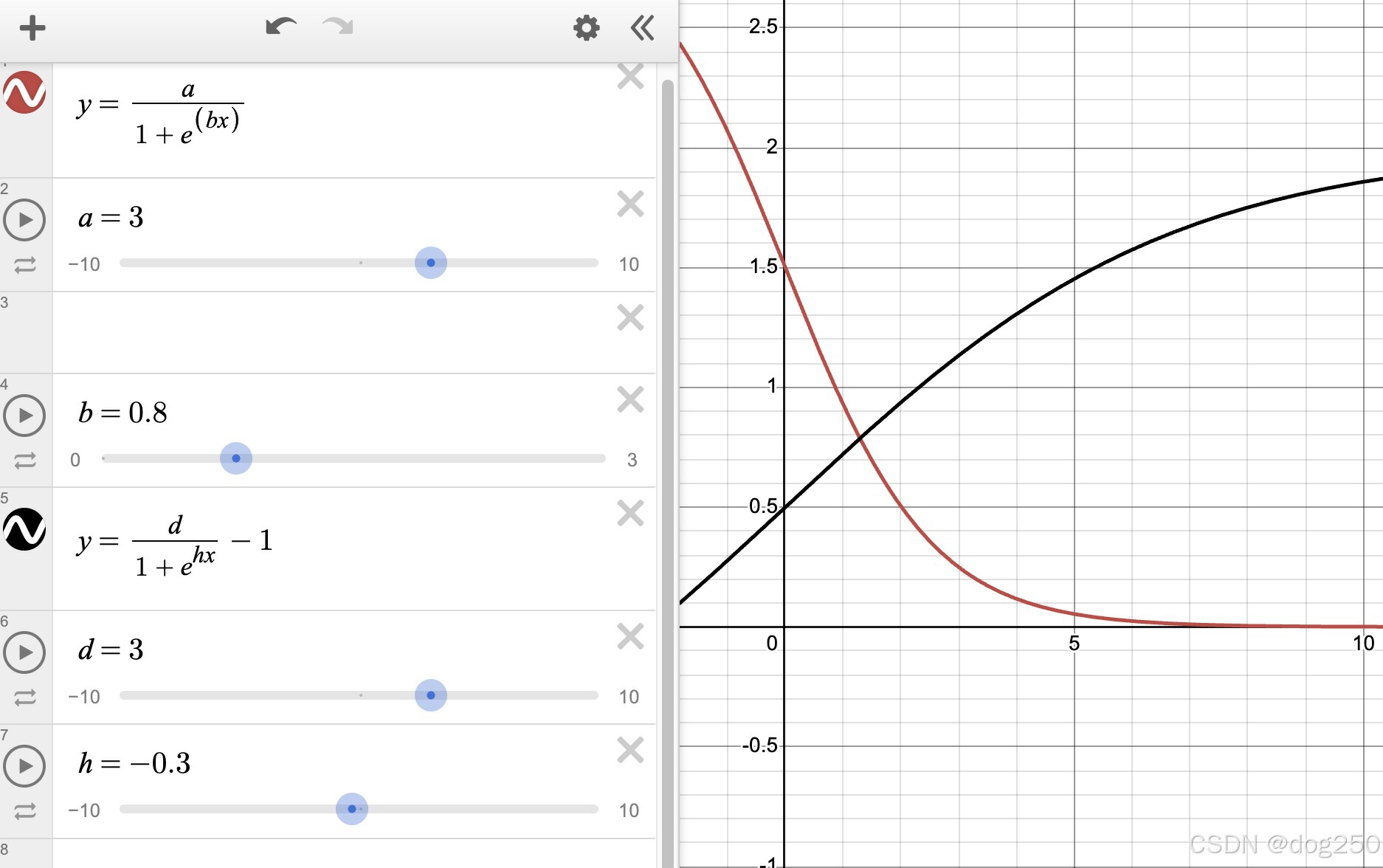
y 在 x >= 0 区间最值稍微超过 1 的理由是为了让下面描述的上述第三步的函数 f(x) 药效更猛:
- 只有所有 v1,v2,v3,… 都足够大时,f(v1, v2, v3, …) 才足够大,因此需要让小的更小,大的更大;
- so,大于 1 的算大,小于 1 的算小,比如 f ( . . . ) = ( ∏ a i ) n f(...)=(\prod {a_i})^n f(...)=(∏ai)n or f ( . . . ) = ( Σ a i ) n − Σ a i n f(...)=(\Sigma a_i)^n-\Sigma a_i^n f(...)=(Σai)n−Σain
将 f(…) 的图像视为指数画像,只要观察相应指标的指数画像的凸起部分展示的凸显阳性特征,就可以知道它发生或者没发生,以及通过阳性幅度看出发生程度。
我来简单描述这个 case:
| 时延 | 时延方差 | 带宽 | 带宽方差 | |
|---|---|---|---|---|
| 稳定拥塞 | 大 | 小 | N/A | N/A |
| 突发拥塞 | 大 | 大 | N/A | N/A |
| 随机丢包(高) | 小 | 小 | 小 | 大 |
| 随机丢包(低) | 小 | 小 | 大 | 小 |
低时延和高带宽几乎就是端到端追求的全部,用它们构建评价体系的指标是简单直接的,但在本 case 之外,你可以为更细致的画像生成指数,也可以为既有画像指数增加新的指标,包括不限于:
- 丢包间隔,丢包间隔方差,连续两次丢包时的 cwnd 比值,bw / delay 以及方差,通用 QoE 映射模型
仍以以上表格为基,下面是一个简单的模拟代码:
if n > 500 and n <= 1000:
# 随机突发拥塞
Buff = random.randint(0, 20)
elif n > 1500 and n <= 2000:
# 持续拥塞
Buff = 20
elif n > 2500 and n <= 3000:
# 逐渐拥塞
Buff += 0.04
elif n > 3500 and n <= 4000:
# 随机高丢包率(无拥塞)
Buff = 0
if random.random() < drate:
wx[n] = wx[n]/2
wy[n] = wy[n]/2
elif n > 4200 and n <= 4600:
# 随机低丢包率(无拥塞)
Buff = 0
if random.random() < drate/50:
wx[n] = wx[n]/2
else:
# Good
Buff = 0
while wx[n] + wy[n] + Buff > 1.2*C*R:
wx[n] = wx[n]/2
wy[n] = wy[n]/2
本 case 的目标很简单,通过查看拥塞指数,突发指数,随机丢包指数,成功分离出突发抖动,常规拥塞以及随机丢包。通过这几个指数精确诊断带宽下降的原因,进而指导传输协议行为。
下面是我针对以上模拟的场景,加入上述画像指数的实现,用 matplotlib 生产的图像:
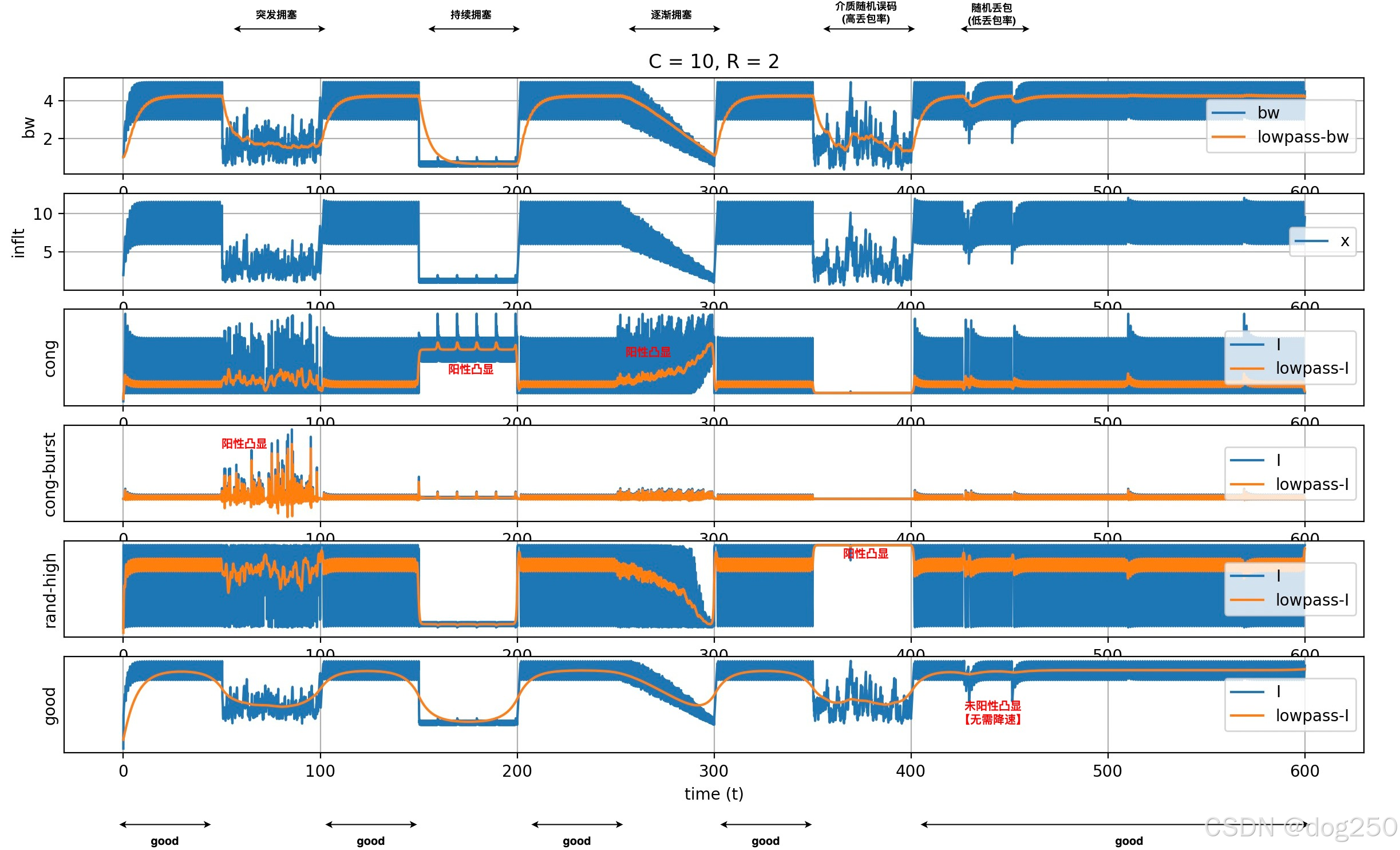
注意最后的 good,它成功过滤出 “有问题” 需要处理的区间,唯独低丢包率的随机丢包区间被掠过,说明在这个滤波器范围内,它无需处理。用一个更加低通的滤波显示一下:
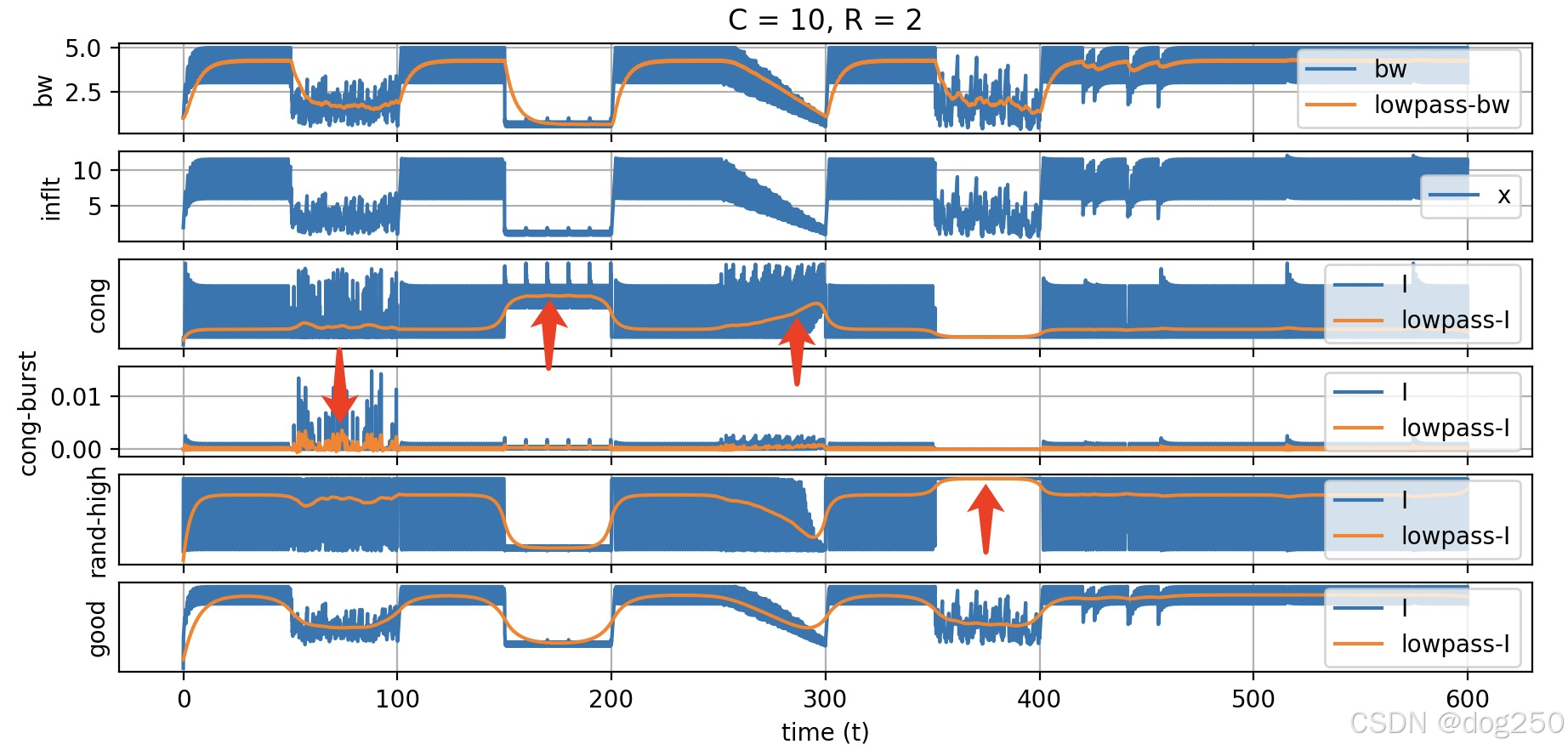
通过看这个图诊断传输性能的方法很简单:
- 将每个指标的指数画像与测量带宽画像平行平铺在下面,时间尺度保持一致;
- 在带宽异常的时间区间分别审视每个指标的指数画像;
- 对于每个指数画像的对应该区间,如果凸显阳性,该指标便为阳性;
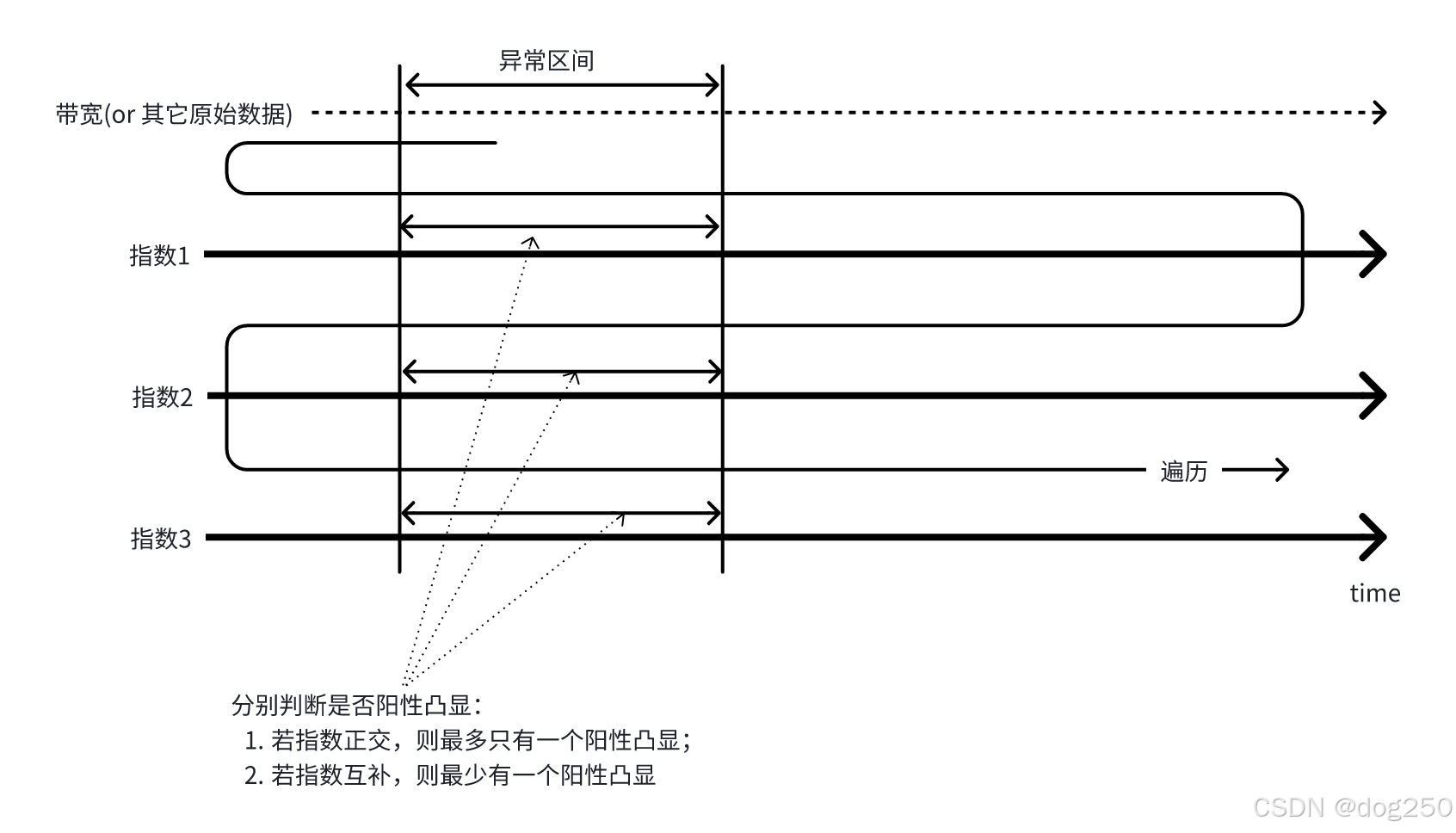
由此便可甄别出异常原因。
在任意时刻均可查看这些指数画像以优化传输协议的行为。由于世界是渐变的,具有时间和空间局部性,因此这类画像是可信的。
但在变化的初始边缘,请注意不要预测,你不知道它是一场灾难的开始,还是仅仅一个毛刺,此时的行为保持和变化之中一致:
- 如果检测到处在持续拥塞之中,继续保持保守的拥塞控制策略;
- 如果首次检测到异常,相信它是一次灾难的开始转入保守,直到画像表明只是毛刺,方可由保守重新积极;
- 关注指数画像的早期异常永远是正确的,区别在于如何反应;
- …
只是一个 demo,相当于一幅素描甚至仅仅是轮廓,仅描述这个评价体系的具体工作原理。还可以加入更多指标,用 sigmoid 函数抽取 “阳性特征”,勾勒越多越逼真,指数画像越逼真越可信,油画和素描的区别。
…
用法方面,该评价体系可构建于任何作为 sender 的服务器,作为守护进程运行,不断采集传输流的数据生成指数画像,而传输协议则可以随时查阅这些指数画像以获得指导。
比如,可以使用阿里云开源(但显然是 Version 2,需要自己完善)的 tcprt:TCP-RT功能的配置说明,注意,仅用它采集数据的模块,用守护进程主动拉取或传输协议主动推送的方式获得原始数据后实时生成指数画像。
传输协议优化圈子多年来仍在试图通过单一指标优化单一算法,最初我也持这种想法,当我发现任何单一指标都易变不稳定后,我决定多看几个指标,我曾基于 Bloom Filter 用多个阳性结果 “与”,但效果不佳,因为连续的度量并非非此即彼,很难在离散的 True or False 间定夺,直到采用 “指数” 的思想,让阳性特征自动推高显式指标,我只需要观察指数曲线即可剔除单一指标经常带来的假阳性误判。
非常有意思,之前在公司吭吭哧哧好几个月硬是没放出个屁,时间和精力净化在应对开会和汇报上了,然而项目下架后,竟然凭兴趣画出了轮廓,完成了 demo…PS:sigmoid 函数真是个好东西,它将高低大小映射到了一个固定归一化区间。
浙江温州皮鞋湿,下雨进水不会胖。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









