







与网络数据包的发送不同,网络收包是异步的的,因为你不确定谁会在什么时候突然发一个网络包给你,因此这个网络收包逻辑其实包含两件事:
1.数据包到来后的通知
2.收到通知并从数据包中获取数据
这两件事发生在协议栈的两端,即网卡/协议栈边界以及协议栈/应用边界:
网卡/协议栈边界:网卡通知数据包到来,中断协议栈收包;
协议栈栈/应用边界:协议栈将数据包填充socket队列,通知应用程序有数据可读,应用程序负责接收数据。
本文就来介绍一下关于这两个边界的这两件事是怎么一个细节,关乎网卡中断,NAPI,网卡poll,select/poll/epoll等细节,并假设你已经大约懂了这些。
a.每个数据包到来即中断CPU,由CPU调度中断处理程序进行收包处理,收包逻辑又分为上半部和下半部,核心的协议栈处理逻辑在下半部完成。
b.数据包到来,中断CPU,CPU调度中断处理程序并且关闭中断响应,调度下半部不断轮询网卡,收包完毕或者达到一个阀值后,重新开启中断。
其中的方式a在数据包持续快速到达的时候会造成很大的性能损害,因此这种情况下一般采用方式b,这也是Linux NAPI采用的方式。
关于网卡/协议栈边界所发生的事件,不想再说更多了,因为这会涉及到很多硬件的细节,比如你在NAPI方式下关了中断后,网卡内部是怎么缓存数据包的,另外考虑到多核处理器的情形,是不是可以将一个网卡收到的数据包中断到不同的CPU核心呢?那么这就涉及到了多队列网卡的问题,而这些都不是一个普通的内核程序员所能驾驭的,你要了解更多的与厂商相关的东西,比如Intel的各种规范,各种让人看到晕的手册...
协议栈/socket边界事件
因此,为了更容易理解,我决定在另一个边界,即协议栈栈/应用边界来描述同样的事情,而这些基本都是内核程序员甚至应用程序员所感兴趣的领域了,为了使后面的讨论更容易进行,我将这个协议栈栈/应用边界重命名为协议栈/socket边界,socket隔离了协议栈和应用程序,它就是一个接口,对于协议栈,它可以代表应用程序,对于应用程序,它可以代表协议栈,当数据包到来的时候,会发生如下的事情:
1).协议栈将数据包放入socket的接收缓冲区队列,并通知持有该socket的应用程序;
2).CPU调度持有该socket的应用程序,将数据包从接收缓冲区队列中取出,收包完毕。
总体的示意图如下
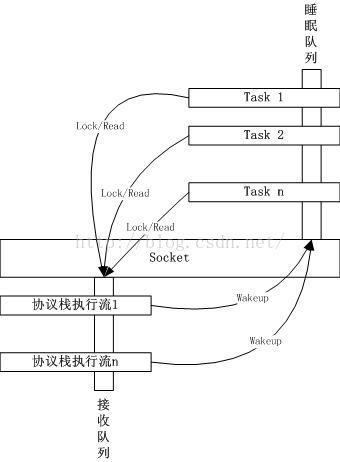
这个模型非常简单且直接,和网卡中断CPU通知网络上有数据包到来需要处理一样,协议栈通过这种方式通知应用程序有数据可读,在继续讨论细节以及select/poll/epoll之前,先说两个无关的事,后面就不再说了,只是因为它们相关,所以只是提一下而已,不会占用大量篇幅。
这个话题在网上的讨论早就已经汗牛充栋,但是仔细想一下就会发现排他唤醒依然有问题,它会大大降低效率。
为什么这么说呢?因为协议栈的唤醒操作和应用程序的实际Accept操作之间是完全异步的,除非在协议栈唤醒应用程序的时候,应用程序恰好阻塞在Accept上,任何人都不能保证当时应用程序在干什么。举一个简单的例子,在多核系统上,协议栈方面同时来了多个请求,而且也恰恰有多个线程等待在睡眠队列上,如果能让这多个协议栈执行流同时唤醒这多个线程该有多好,但是由于一个socket只有一个Accept队列,因此对于该队列的排他唤醒机制基本上将这个畅想给打回去了,唯一一个accpet队列的排入/取出的带锁操作让整个流程串行化了,完全丧失了多核并行的优势,因此REUSEPORT以及基于此的FastTCP就出现了。(今天周末,仔细研究了Linux kernel 4.4版本带来的更新,真的让人眼前一亮啊,后面我会单独写一篇文章来描述)
当然,如果REUSEPORT的基于源IP/源端口对的hash计算,直接避免了将同一个流“中断”到不同的socket的接收队列上。
好了,插曲已经说完,接下来该细节了。
起码在2.6.8的内核上就是这么搞的。后来的版本都是这个基础版本的优化版本,先后经历了两次的优化。
谁找的事谁来处理!当初就是因为应用程序lock住了socket而使得协议栈不得不将skb排入backlog,那么在应用程序release socket的时候,就会将backlog队列里面的skb放入接收队列中去,模拟协议栈将skb入队并唤醒操作。
引入backlog队列后,单一的接收队列变成了一个两阶段的接力队列,类似流水线作业那样。这样无论如何协议栈都不用阻塞等待,协议栈如果不能马上将skb排入接收队列,那么这件事就由socket锁定者自己来完成,等到它放弃锁定的时候这件事即可进行。操作例程如下:
协议栈排队skb---
获取socket自旋锁
应用程序占有socket的时候:将skb排入backlog队列
应用程序未占有socket的时候:将skb排入接收队列,唤醒接收队列
释放socket自旋锁
应用程序接收数据---
获取socket自旋锁
阻塞占用socket
释放socket自旋锁
读取数据:由于已经独占了socket,可以放心地将接收队列skb的内容拷贝到用户态
获取socket自旋锁
将backlog队列的skb排入接收队列(这其实本该由协议栈完成的,但是由于应用程序占有socket而被延后到了此刻),唤醒睡眠队列
释放socket自旋锁
可以看到,所谓的socket锁,并不是一把简单的自旋锁,而是在不同的路径有不同的锁定方式,总之,只要能保证socket的元数据受到保护,方案都是合理的,于是我们看到这是一个两层锁的模型。
参与者类别:NON-Sleep-不可睡眠类,Sleep-可睡眠类
参与者数量:NON-Sleep多个,Sleep类多个
竞争者:NON-Sleep类之间,Sleep类之间,NON-Sleep类和Sleep类之间
数据结构:
X-被锁定实体
X.LOCK-自旋锁,用于锁定不可睡眠路径以及保护标记锁
X.FLAG-标记锁,用来锁定可睡眠路径
X.sleeplist-等待获得标记锁的task队列
对于socket收包逻辑,其实就是将skb插入接收队列并唤醒socket的睡眠队列填充到上述的direct_func中即可,同时delay_func的任务就是将skb插入到backlog队列。
该抽象出来的模型基本就是一个两层锁逻辑,自旋锁在可睡眠路径仅仅用来保护标记位,可睡眠路径使用标记位来锁定而不是使用自旋锁本身,标记位的修改被自旋锁保护,这个非常快的修改操作代替了慢速的业务逻辑处理路径(比如socket收包...)的完全锁定,这样就大大减少了竞态带来的CPU时间的自旋开销。近期我在实际的一个场景中就采用了这个模型,非常不错,效果也真的还好,因此特意抽象出了上述的代码。
引入这个两层锁解放了不可睡眠路径的操作,使其在可睡眠路径的task占有一个socket期间仍然可以将数据包排入到backlog队列而不是等待可睡眠路径task解锁,然而有的时候可睡眠路径上的逻辑也不是那么慢,如果它不慢,甚至很快,锁定时间很短,那么是不是就可以直接跟不可睡眠路径去争抢自旋锁了呢?这正是引入可睡眠路径fast lock的契机。
a.处理临界区非常小
b.当前没有其它进程/线程上下文中的socket处理逻辑正在处理这个socket。
满足以上条件的,说明这是一个单纯的环境,竞争者地位对等。那么很显然的一个问题就是谁来处理backlog队列的问题,这个问题其实不是问题,因为这种情况下backlog就用不到了,操作backlog必须持有自旋锁,socket在fast lock期间也是持有自旋锁的,两个路径完全互斥!因此上述条件a就极其重要,如果在临界区内出现了大的延迟,会造成协议栈路径过度自旋!新的fast lock框架如下:
之所以上述代码那么复杂而不是仅仅的spin_lock/spin_unlock,是因为如果X.FLAG为1,说明该socket已经在处理了,比如阻塞等待。
以上就是在协议栈/socket边界上的异步流程的队列和锁的总体架构,总结一下,包含5个要素:
a=socket的接收队列
b=socket的睡眠队列
c=socket的backlog队列
d=socket的自旋锁
e=socket的占有标记
这5者之间执行以下的流程:
有了这个框架,协议栈和socket之间就可以安全异步地进行网络数据的交接了,如果你仔细看,并且对Linux 2.6内核的wakeup机制有足够的了解,且有一定的解耦合的思想,我想应该可以知道select/poll/epoll是怎样一种工作机制了。关于这个我想在本文的第二部分描述,我觉得,只要对基础概念有足够的理解且可以融会贯通,很多东西都是可以仅仅靠想而推导出来的。
下面,我们可以在以上这个框架内让skb参与进来了。
Linux为skb提供了一个destructor析构回调函数,每当skb被赋予新的属主的时候会调用前一个属主的析构函数,并被指定一个新的析构函数,我们比较关注的是skb从协议栈到socket的这最后一棒,在将skb排入到socket接收队列之前,会调用下面的函数:
其中skb_orphan主要是回调了前一个属主赋予该skb的析构函数,然后为其指定一个新的析构回调函数sock_rfree。在skb_set_owner_r调用完成后,该skb就正式进入socket的接收队列了:
最后通过调用sk_data_ready来通知睡眠在socket睡眠队列上的task数据已经被排入接收队列,其实就是一个wakeup操作,然后协议栈就返回。很显然,接下来关于该skb的所有处理均在进程/线程上下文中进行了,等到skb的数据被取出后,这个skb不会返回给协议栈,而是由进程/线程自行释放,因此在其destructor回调函数sock_rfree中,主要做的就是把缓冲区空间还给系统,主要做两件事:
1.该socket已分配的内存减去该skb占据的空间
sk->sk_rmem_alloc = sk->sk_rmem_alloc - skb->truesize;
2.该socket预分配的空间加上该skb占据的空间
sk->sk_forward_alloc = sk->sk_forward_alloc + skb->truesize;
net.ipv4.tcp_mem = 18978 25306 37956
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_mem = 18978 25306 37956
....
以上的每一项三个值中,含义如下:
第一个值mem[0]:表示正常值,凡是内存用量低于这个值时,都正常;
第二个值mem[1]:警告值,凡是高于这个值,就要着手紧缩方案了;
第三个值mem[2]:不可逾越的界限,高于这个值,说明内存使用已经超限了,数据要丢弃了。
注意,这些配置值是针对单独协议的,而sockopt中配置的recvbuff配置的是针对单独一条连接的缓冲区大小限制,两者是不同的。内核在处理这个协议限额的时候,为了避免频繁检测,采用了预分配机制,第一次即便只是来了一个1byte的包,也会为其透支一个页面的内存限额,这里并没有实际进行内存分配,因为实际的内存分配在skb生成以及IP分片重组的时候就已经确定了,这里只是将这些值累加起来,检测一下是否超过限额而已,因此这里的逻辑仅仅是一个加减乘除的过程,除了计算过程消耗的CPU之外,并没有消耗其它的机器资源。
计算方法如下
proto.memory_allocated:每一个协议一个,表示当前该协议在内核socket缓冲区里面一共已经使用了多少内存存放skb;
sk.sk_forward_alloc:每一个socket一个,表示当前预分配给该socket的内存剩余用量,可以用来存放skb;
skb.truesize:该skb结构体本身的大小以及其数据大小的总和;
skb即将进入socket的接收队列前夕的累加例程:
协议缓冲区回收时期(会在释放skb或者过期删除skb时调用):
这个逻辑可以在sk_rmem_schedule等sk_mem_XXX函数中看个究竟。
本文的第一部分到此已经结束,第二部分将着重描述select,poll,epoll的逻辑。
1.数据包到来后的通知
2.收到通知并从数据包中获取数据
这两件事发生在协议栈的两端,即网卡/协议栈边界以及协议栈/应用边界:
网卡/协议栈边界:网卡通知数据包到来,中断协议栈收包;
协议栈栈/应用边界:协议栈将数据包填充socket队列,通知应用程序有数据可读,应用程序负责接收数据。
本文就来介绍一下关于这两个边界的这两件事是怎么一个细节,关乎网卡中断,NAPI,网卡poll,select/poll/epoll等细节,并假设你已经大约懂了这些。
网卡/协议栈边界的事件
网卡在数据包到来的时候会触发中断,然后协议栈就知道了数据包到来事件,接下来怎么收包完全取决于协议栈本身,这就是网卡中断处理程序的任务,当然,也可以不采用中断的方式,而是采用一个单独的线程不断轮询网卡是否有数据包的到来,但是这种方式过于消耗CPU,做过多的无用功,因此基本被弃用,像这种异步事件,基本都是采用中断通知的方案。综合整个收包逻辑,大致可以分为以下两种方式a.每个数据包到来即中断CPU,由CPU调度中断处理程序进行收包处理,收包逻辑又分为上半部和下半部,核心的协议栈处理逻辑在下半部完成。
b.数据包到来,中断CPU,CPU调度中断处理程序并且关闭中断响应,调度下半部不断轮询网卡,收包完毕或者达到一个阀值后,重新开启中断。
其中的方式a在数据包持续快速到达的时候会造成很大的性能损害,因此这种情况下一般采用方式b,这也是Linux NAPI采用的方式。
关于网卡/协议栈边界所发生的事件,不想再说更多了,因为这会涉及到很多硬件的细节,比如你在NAPI方式下关了中断后,网卡内部是怎么缓存数据包的,另外考虑到多核处理器的情形,是不是可以将一个网卡收到的数据包中断到不同的CPU核心呢?那么这就涉及到了多队列网卡的问题,而这些都不是一个普通的内核程序员所能驾驭的,你要了解更多的与厂商相关的东西,比如Intel的各种规范,各种让人看到晕的手册...
协议栈/socket边界事件
因此,为了更容易理解,我决定在另一个边界,即协议栈栈/应用边界来描述同样的事情,而这些基本都是内核程序员甚至应用程序员所感兴趣的领域了,为了使后面的讨论更容易进行,我将这个协议栈栈/应用边界重命名为协议栈/socket边界,socket隔离了协议栈和应用程序,它就是一个接口,对于协议栈,它可以代表应用程序,对于应用程序,它可以代表协议栈,当数据包到来的时候,会发生如下的事情:
1).协议栈将数据包放入socket的接收缓冲区队列,并通知持有该socket的应用程序;
2).CPU调度持有该socket的应用程序,将数据包从接收缓冲区队列中取出,收包完毕。
总体的示意图如下
socket要素
如上图所示,每一个socket的收包逻辑都包含以下两个要素接收队列
协议栈处理完毕的数据包要排入到的队列,应用程序被唤醒后要从该队列中读取数据。睡眠队列
与该socket相关的应用程序如果没有数据可读,可以在这个队列上睡眠,一旦协议栈将数据包排入socket的接收队列,将唤醒该睡眠队列上的进程或者线程。一把socket锁
在有执行流操作socket的元数据的时候,必须锁定socket,注意,接收队列和睡眠队列并不需要该锁来保护,该锁所保护的是类似socket缓冲区大小修改,TCP按序接收之类的事情。这个模型非常简单且直接,和网卡中断CPU通知网络上有数据包到来需要处理一样,协议栈通过这种方式通知应用程序有数据可读,在继续讨论细节以及select/poll/epoll之前,先说两个无关的事,后面就不再说了,只是因为它们相关,所以只是提一下而已,不会占用大量篇幅。
1.惊群与排他唤醒
类似TCP accpet逻辑这样,对于大型web服务器而言,基本上都是有多个进程或者线程同时在一个Listen socket上进行accept,如果协议栈将一个客户端socket排入了accept队列,是将这些线程全部唤醒还是只唤醒一个呢?如果是全部唤醒,很显然,只有一个线程会抢到这个socket,其它的线程抢夺失败后继续睡眠,可以说是被白白唤醒了,这就是经典的TCP惊群,因此产生了一种排他式的唤醒,也就是说只唤醒睡眠队列上的第一个线程,然后退出wakeup逻辑,不再唤醒后面的线程,这就避免了惊群。这个话题在网上的讨论早就已经汗牛充栋,但是仔细想一下就会发现排他唤醒依然有问题,它会大大降低效率。
为什么这么说呢?因为协议栈的唤醒操作和应用程序的实际Accept操作之间是完全异步的,除非在协议栈唤醒应用程序的时候,应用程序恰好阻塞在Accept上,任何人都不能保证当时应用程序在干什么。举一个简单的例子,在多核系统上,协议栈方面同时来了多个请求,而且也恰恰有多个线程等待在睡眠队列上,如果能让这多个协议栈执行流同时唤醒这多个线程该有多好,但是由于一个socket只有一个Accept队列,因此对于该队列的排他唤醒机制基本上将这个畅想给打回去了,唯一一个accpet队列的排入/取出的带锁操作让整个流程串行化了,完全丧失了多核并行的优势,因此REUSEPORT以及基于此的FastTCP就出现了。(今天周末,仔细研究了Linux kernel 4.4版本带来的更新,真的让人眼前一亮啊,后面我会单独写一篇文章来描述)
2.REUSEPORT与多队列
起初在了解到google的reuseport之前,我个人也做过一个类似的patch,当时的想法正是来自于与多队列网卡的类比,既然一块网卡可以中断多个CPU,一个socket上的数据可读事件为什么不能中断多个应用程序呢?然而socket API早就已经固定死了,这对我的想法造成了打击,因为一个socket就是一个文件描述符,表示一个五元组(非connect UDP的socket以及Listen tcp除外!),协议栈的事件恰恰只跟一个五元组相关...因此为了让想法可行,只能在socket API之外做文章,那就是允许多个socket绑定同样的IP地址/源端口对,然后按照源IP地址/端口对的HASH值来区分流量的路由,这个想法本人也实现了,其实跟多队列网卡是一个思想,完全一致的。多队列网卡不也是按照不同五元组(或者N元组?咱不较真儿)的HASH值来中断不同的CPU核心的吗?仔细想想当时的这个移植太TMD帅了,然而看到google的reuseport patch就觉得自己做了无用功,重新造了轮子...于是就想解决Accept单队列的问题,既然已经多核时代了,为什么不在每个CPU核心上保持一个accept队列呢?应用程序的调度让schedule子系统去考虑吧...这次没有犯傻,于是看到了新浪的FastTCP方案。当然,如果REUSEPORT的基于源IP/源端口对的hash计算,直接避免了将同一个流“中断”到不同的socket的接收队列上。
好了,插曲已经说完,接下来该细节了。
接收队列的管理
接收队列的管理其实非常简单,就是一个skb链表,协议栈将skb插入到链表的时候先lock住队列本身,然后插入skb,然后唤醒socket睡眠队列上的线程,接着线程加锁获取socket接收队列上skb的数据,就是这么简单。起码在2.6.8的内核上就是这么搞的。后来的版本都是这个基础版本的优化版本,先后经历了两次的优化。
接收路径优化1:引入backlog队列
考虑到复杂的细节,比如根据收到的数据修改socket缓冲区大小时,应用程序在调用recv例程时需要对整个socket进行锁定,在复杂的多核CPU环境中,有多个应用程序可能会操作同一个socket,有多个协议栈执行流也可能会往同一个socket接收缓冲区排入skb[详情请参考《 多核心Linux内核路径优化的不二法门之-多核心平台TCP优化》],因此锁的粒度范围自然就变成了socket本身。在应用程序持有socket的时候,协议栈由于可能会在软中断上下文运行,是不可睡眠等待的,为了使得协议栈执行流不至于因此而自旋阻塞,引入了一个backlog队列,协议栈在应用程序持有socket的时候,只需要将skb排入backlog队列就可以返回了,那么这个backlog队列最终由谁来处理呢?谁找的事谁来处理!当初就是因为应用程序lock住了socket而使得协议栈不得不将skb排入backlog,那么在应用程序release socket的时候,就会将backlog队列里面的skb放入接收队列中去,模拟协议栈将skb入队并唤醒操作。
引入backlog队列后,单一的接收队列变成了一个两阶段的接力队列,类似流水线作业那样。这样无论如何协议栈都不用阻塞等待,协议栈如果不能马上将skb排入接收队列,那么这件事就由socket锁定者自己来完成,等到它放弃锁定的时候这件事即可进行。操作例程如下:
协议栈排队skb---
获取socket自旋锁
应用程序占有socket的时候:将skb排入backlog队列
应用程序未占有socket的时候:将skb排入接收队列,唤醒接收队列
释放socket自旋锁
应用程序接收数据---
获取socket自旋锁
阻塞占用socket
释放socket自旋锁
读取数据:由于已经独占了socket,可以放心地将接收队列skb的内容拷贝到用户态
获取socket自旋锁
将backlog队列的skb排入接收队列(这其实本该由协议栈完成的,但是由于应用程序占有socket而被延后到了此刻),唤醒睡眠队列
释放socket自旋锁
可以看到,所谓的socket锁,并不是一把简单的自旋锁,而是在不同的路径有不同的锁定方式,总之,只要能保证socket的元数据受到保护,方案都是合理的,于是我们看到这是一个两层锁的模型。
两层锁定的lock框架
啰嗦了这么多,其实我们可以把上面最后的那个序列总结成一个更为抽象通用的模式,在某些场景下可以套用。现在就描述一下这个模式。参与者类别:NON-Sleep-不可睡眠类,Sleep-可睡眠类
参与者数量:NON-Sleep多个,Sleep类多个
竞争者:NON-Sleep类之间,Sleep类之间,NON-Sleep类和Sleep类之间
数据结构:
X-被锁定实体
X.LOCK-自旋锁,用于锁定不可睡眠路径以及保护标记锁
X.FLAG-标记锁,用来锁定可睡眠路径
X.sleeplist-等待获得标记锁的task队列
NON-Sleep类的锁定/解锁逻辑:
spin_lock(X.LOCK);
if(X.FLAG == 1) {
//add something todo to backlog
delay_func(...);
} else {
//do it directly
direct_func(...);
}
spin_unlock(X.LOCK);
Sleep类的锁定/解锁逻辑:
spin_lock(X.LOCK);
do {
if (X.FLAG == 0) {
break;
}
for (;;) {
ready_to_wait(X.sleeplist);
spin_unlock(X.lock);
wait();
spin_lock(X.lock);
if (X.FLAG == 0) {
break;
}
}
} while(0);
X.FLAG = 1;
spin_unlock(X.LOCK);
do_something(...);
spin_lock(X.LOCK)
if (have_delayed_work) {
do {
fetch_delayed_work(...);
direct_func(...);
} while(have_delayed_work);
}
X.FLAG = 0;
wakeup(X.sleeplist);
spin_unlock(X.LOCK);
对于socket收包逻辑,其实就是将skb插入接收队列并唤醒socket的睡眠队列填充到上述的direct_func中即可,同时delay_func的任务就是将skb插入到backlog队列。
该抽象出来的模型基本就是一个两层锁逻辑,自旋锁在可睡眠路径仅仅用来保护标记位,可睡眠路径使用标记位来锁定而不是使用自旋锁本身,标记位的修改被自旋锁保护,这个非常快的修改操作代替了慢速的业务逻辑处理路径(比如socket收包...)的完全锁定,这样就大大减少了竞态带来的CPU时间的自旋开销。近期我在实际的一个场景中就采用了这个模型,非常不错,效果也真的还好,因此特意抽象出了上述的代码。
引入这个两层锁解放了不可睡眠路径的操作,使其在可睡眠路径的task占有一个socket期间仍然可以将数据包排入到backlog队列而不是等待可睡眠路径task解锁,然而有的时候可睡眠路径上的逻辑也不是那么慢,如果它不慢,甚至很快,锁定时间很短,那么是不是就可以直接跟不可睡眠路径去争抢自旋锁了呢?这正是引入可睡眠路径fast lock的契机。
接收路径优化2:引入fast lock
进程/线程上下文中的socket处理逻辑在满足下列情况的前提下可以直接与内核协议栈竞争该socket的自旋锁:a.处理临界区非常小
b.当前没有其它进程/线程上下文中的socket处理逻辑正在处理这个socket。
满足以上条件的,说明这是一个单纯的环境,竞争者地位对等。那么很显然的一个问题就是谁来处理backlog队列的问题,这个问题其实不是问题,因为这种情况下backlog就用不到了,操作backlog必须持有自旋锁,socket在fast lock期间也是持有自旋锁的,两个路径完全互斥!因此上述条件a就极其重要,如果在临界区内出现了大的延迟,会造成协议栈路径过度自旋!新的fast lock框架如下:
Sleep类的fast锁定/解锁逻辑:
fast = 0;
spin_lock(X.LOCK)
do {
if (X.FLAG == 0) {
fast = 0;
break;
}
for (;;) {
ready_to_wait(X.sleeplist);
spin_unlock(X.LOCK);
wait();
spin_lock(X.LOCK);
if (X.FLAG == 0) {
break;
}
}
X.FLAG = 1;
spin_unlock(X.LOCK);
} while(0);
do_something_very_small(...);
do {
if (fast == 1) {
break;
}
spin_lock(X.LOCK);
if (have_delayed_work) {
do {
fetch_delayed_work(...);
direct_func(...);
} while(have_delayed_work);
}
X.FLAG = 0;
wakeup(X.sleeplist);
} while(0);
spin_unlock(X.LOCK);之所以上述代码那么复杂而不是仅仅的spin_lock/spin_unlock,是因为如果X.FLAG为1,说明该socket已经在处理了,比如阻塞等待。
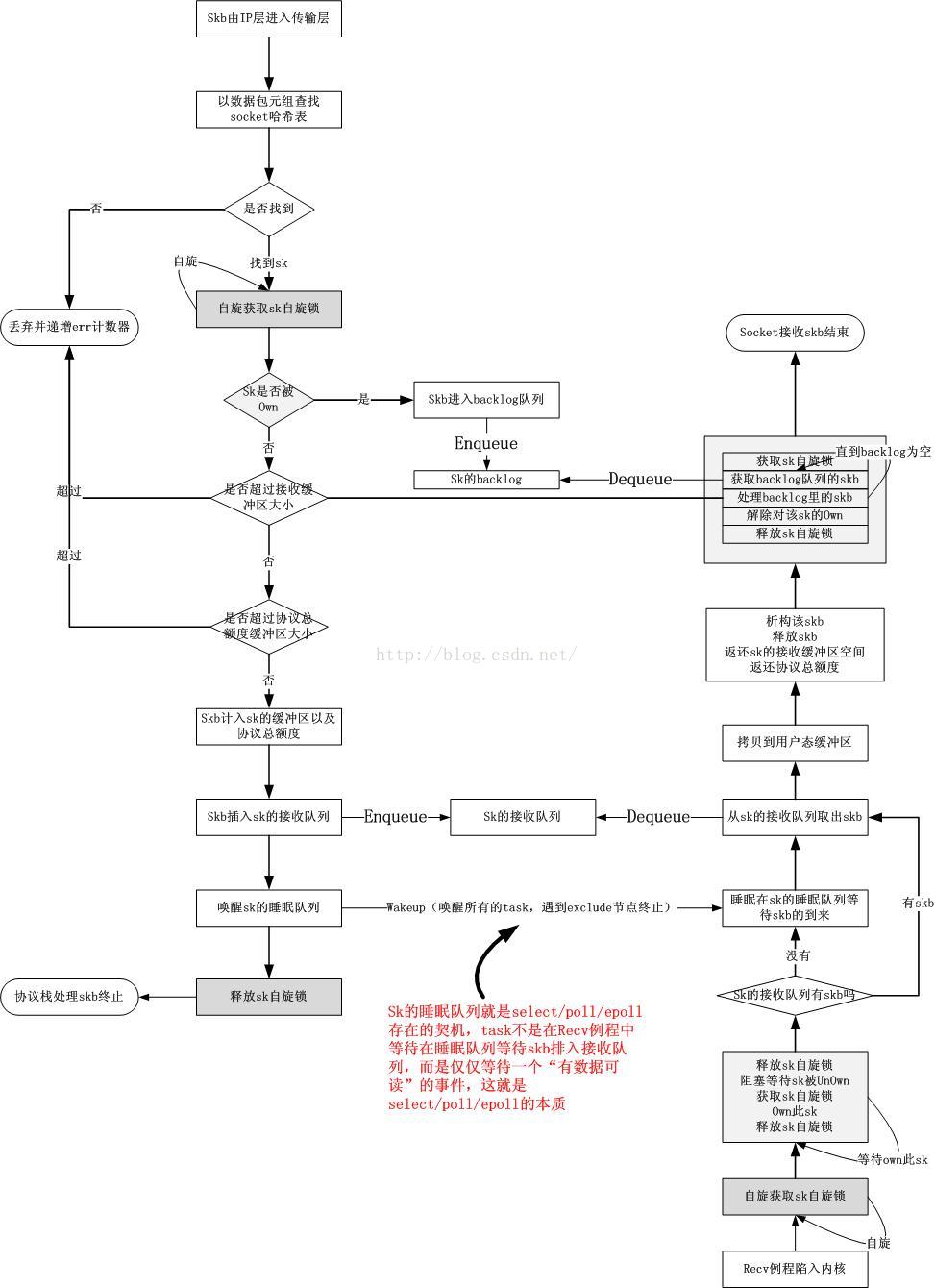
以上就是在协议栈/socket边界上的异步流程的队列和锁的总体架构,总结一下,包含5个要素:
a=socket的接收队列
b=socket的睡眠队列
c=socket的backlog队列
d=socket的自旋锁
e=socket的占有标记
这5者之间执行以下的流程:
有了这个框架,协议栈和socket之间就可以安全异步地进行网络数据的交接了,如果你仔细看,并且对Linux 2.6内核的wakeup机制有足够的了解,且有一定的解耦合的思想,我想应该可以知道select/poll/epoll是怎样一种工作机制了。关于这个我想在本文的第二部分描述,我觉得,只要对基础概念有足够的理解且可以融会贯通,很多东西都是可以仅仅靠想而推导出来的。
下面,我们可以在以上这个框架内让skb参与进来了。
接力传递的skb
在Linux的协议栈实现中,skb表示一个数据包,一个skb可以属于一个socket或者协议栈,但不能同时属于两者,一个skb属于协议栈指的是它不和任何一个socket相关联,它仅对协议栈本身负责,如果一个skb属于一个socket,就意味着它已经和一个socket进行了绑定,所有的关于它的操作,都要由该socket负责。Linux为skb提供了一个destructor析构回调函数,每当skb被赋予新的属主的时候会调用前一个属主的析构函数,并被指定一个新的析构函数,我们比较关注的是skb从协议栈到socket的这最后一棒,在将skb排入到socket接收队列之前,会调用下面的函数:
static inline void skb_set_owner_r(struct sk_buff *skb, struct sock *sk)
{
skb_orphan(skb);
skb->sk = sk;
skb->destructor = sock_rfree;
atomic_add(skb->truesize, &sk->sk_rmem_alloc);
sk_mem_charge(sk, skb->truesize);
}
其中skb_orphan主要是回调了前一个属主赋予该skb的析构函数,然后为其指定一个新的析构回调函数sock_rfree。在skb_set_owner_r调用完成后,该skb就正式进入socket的接收队列了:
skb_set_owner_r(skb, sk);
/* Cache the SKB length before we tack it onto the receive
* queue. Once it is added it no longer belongs to us and
* may be freed by other threads of control pulling packets
* from the queue.
*/
skb_len = skb->len;
skb_queue_tail(&sk->sk_receive_queue, skb);
if (!sock_flag(sk, SOCK_DEAD))
sk->sk_data_ready(sk, skb_len);
最后通过调用sk_data_ready来通知睡眠在socket睡眠队列上的task数据已经被排入接收队列,其实就是一个wakeup操作,然后协议栈就返回。很显然,接下来关于该skb的所有处理均在进程/线程上下文中进行了,等到skb的数据被取出后,这个skb不会返回给协议栈,而是由进程/线程自行释放,因此在其destructor回调函数sock_rfree中,主要做的就是把缓冲区空间还给系统,主要做两件事:
1.该socket已分配的内存减去该skb占据的空间
sk->sk_rmem_alloc = sk->sk_rmem_alloc - skb->truesize;
2.该socket预分配的空间加上该skb占据的空间
sk->sk_forward_alloc = sk->sk_forward_alloc + skb->truesize;
协议数据包内存用量的统计和限制
内核协议栈仅仅是内核的一个子系统,且其数据来自本机之外,数据来源并不受控,很容易受到DDos攻击,因此有必要限制一个协议的总体内存用量,比如所有的TCP连接只能用10M的内存这类,Linux内核起初仅仅针对TCP做统计,后来也加入了针对UDP的统计限制,在配置上体现为几个sysctl参数:net.ipv4.tcp_mem = 18978 25306 37956
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_mem = 18978 25306 37956
....
以上的每一项三个值中,含义如下:
第一个值mem[0]:表示正常值,凡是内存用量低于这个值时,都正常;
第二个值mem[1]:警告值,凡是高于这个值,就要着手紧缩方案了;
第三个值mem[2]:不可逾越的界限,高于这个值,说明内存使用已经超限了,数据要丢弃了。
注意,这些配置值是针对单独协议的,而sockopt中配置的recvbuff配置的是针对单独一条连接的缓冲区大小限制,两者是不同的。内核在处理这个协议限额的时候,为了避免频繁检测,采用了预分配机制,第一次即便只是来了一个1byte的包,也会为其透支一个页面的内存限额,这里并没有实际进行内存分配,因为实际的内存分配在skb生成以及IP分片重组的时候就已经确定了,这里只是将这些值累加起来,检测一下是否超过限额而已,因此这里的逻辑仅仅是一个加减乘除的过程,除了计算过程消耗的CPU之外,并没有消耗其它的机器资源。
计算方法如下
proto.memory_allocated:每一个协议一个,表示当前该协议在内核socket缓冲区里面一共已经使用了多少内存存放skb;
sk.sk_forward_alloc:每一个socket一个,表示当前预分配给该socket的内存剩余用量,可以用来存放skb;
skb.truesize:该skb结构体本身的大小以及其数据大小的总和;
skb即将进入socket的接收队列前夕的累加例程:
ok = 0;
if (skb.truesize < sk.sk_forward_alloc) {
ok = 1;
goto addload;
}
pages = how_many_pages(skb.truesize);
tmp = atomic_add(proto.memory_allocated, pages*page_size);
if (tmp < mem[0]) {
ok = 1;
正常;
}
if (tmp > mem[1]) {
ok = 2;
吃紧;
}
if (tmp > mem[2]) {
超限;
}
if (ok == 2) {
if (do_something(proto)) {
ok = 1;
}
}
addload:
if (ok == 1) {
sk.sk_forward_alloc = sk.sk_forward_alloc - skb.truesize;
proto.memory_allocated = tmp;
} else {
drop skb;
}
sk.sk_forward_alloc = sk.sk_forward_alloc + skb.truesize;协议缓冲区回收时期(会在释放skb或者过期删除skb时调用):
if (sk.sk_forward_alloc > page_size) {
pages = sk.sk_forward_alloc调整到整页面数;
prot.memory_allocated = prot.memory_allocated - pages*page_size;
}这个逻辑可以在sk_rmem_schedule等sk_mem_XXX函数中看个究竟。
本文的第一部分到此已经结束,第二部分将着重描述select,poll,epoll的逻辑。















 3816
3816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









