






这篇文章写的有点过于细节,因此考虑到可读性和日后的可查阅性,我以两个问题作为引子。作为TCP相关项目的招聘,也可以作为面试题,不过,我敢肯定,大多数人都不能回答第一个问题,第二个问题可能会模棱两可。
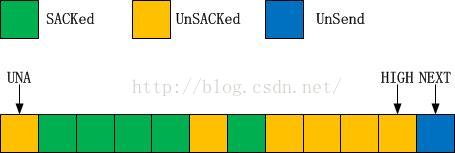
你能给出重传的序列吗?
TCP在快速重传的时候,会依照以下的优先级来传输数据段:
优先级1:标记为LOST的数据段
优先级2:新的尚未发送的数据段
优先级3:在UNA和HIGH区间内没有标记为LOST,没有标记为SACKed,没有重传过的数据段
下面我来解释一下这三类数据段各自是怎么定义的。
首先,优先级1所述的标记为LOST的数据段是由RFC3517的IsLost例程定义的,其定义如下:
IsLost (SeqNum):
This routine returns whether the given sequence number is
considered to be lost. The routine returns true when either
DupThresh discontiguous SACKed sequences have arrived above
'SeqNum' or (DupThresh * SMSS) bytes with sequence numbers greater
than 'SeqNum' have been SACKed. Otherwise, the routine returns
false.
我们以下仍然以问题1的场景描述中的图示来解析,时不时的可能会变动一下细节,但不伤大雅。
Linux在实现快速重传的时候,依照RFC3517的建议维护了一个计分板,该计分板中统计了哪些数据段是SACKed的,哪些数据段是LOST的,我们发现,上图正好是一个计分板的绝佳体现。
在计分板上标记LOST数据段的时候,其要求是要满足RFC3517的IsLost例程,简单点说,就是任何一个被标记为LOST的数据段后面都要有至少DupThresh个被SACKed的数据段。为了满足这个要求,我们在计分板(也就是上图)中标记LOST数据段的方法也就简单了:
从前往后遍历,只要碰到没有被SACKed的数据段就标记为LOST,遍历的过程以SACKed数据段剩余DupThresh个时停止!
因此, 可以在遍历的过程中数SACKed数据段的数量,记为cnt,直到cnt的数量达到SACKed数据段总量与DupThresh的差为止退出。在Linux中,这个逻辑正是由函数tcp_mark_head_lost来实现的,可以查看Linux源码详细研究该函数,本文就不再赘述了。但是还是给出伪代码,如下:
现在我们的计分板更新了,如下所示:
现在看优先级2传输的数据段,即尚未发送的新数据,也就是说在图中HIGH标记之后的数据段。这里也许你会有一点困惑,为什么新数据的传输优先级会更高。简单的解释就是,LOST标记的数据段数量是由SACKed数据段的数量决定的,理论上在数据包守恒的原则下二者是相等的,但考虑到网络乱序的存在,LOST标记的数据段数量会比SACKed数据段数量少一些,二者之差就是一个乱序度的度量值,也就是RFC3517中的DupThresh。因此,剩下那些既没有被SACKed,又没有标记为LOST的数据段,我们称为未决数据。理论上它们没有丢失,只是还在路上,之所以还没有收到ACK或者SACK的原因有三类:
1).乱序了
2).慢了
3).ACK丢了
不管是哪一个原因,它们并没有丢,起码是理论上认为它们并没有丢失,所以此时还需要再等待一下,不管是乱序了,慢了,还是ACK丢了,再等一下都是可以等到确认的,因此此时这类数据段的传输优先级自然就没有新的数据更高,于是在传输完LOST标记的数据段后,就要传输新数据,而不是上述的未决数据。
最后,我们想一下最坏的可能性,即那些未决数据真的丢失了,这很可能是我们的预判过于乐观了,当这些未决数据真的丢失了时,滑动窗口会因为它们而被阻滞无法前行,因此必须在合适的时候去重传它们,这个时机可以尽可能地保守向后,于是它们的传输优先级自然而然也就排在了新数据之后了。
我不喜欢用packetdrill本身的“预期”,我觉得这个packetdrill本身的机制就是垃圾(它并没有支持除了它调通的之外的情况!)!于是,我自己来预期...我还是用tcpdump来最终确认,图示如下:
和之前的packetdrill脚本不同的是,我不再发送太多的数据,而只是发送到14001为止。
此时,你会看到,数据段7001-8001和12001-13001同时被重传了,这是怎么回事呢?如果你初看,那么你会觉得TCP的重传逻辑一次性重传了所有的“空洞”,即7001-8001以及12001-13001,然而事实上7001-8001段和12001-13001段这两个段,并不是按照同一个机制传输出去的,第一个7001-8001数据段是优先级1的传输使然,而12001-13001数据段则是优先级3的传输使然!tcpdump的结果如下:
是否触发重传,不仅仅取决于被ACK/SACK的字节数与reordering*MSS的关系,还取决于发送的skb的大小。
假设当前的MSS为1000,reordering的值为3,那么是不是一定要重复确认的字节数超过3000才会触发快速重传呢?答案是否定的!因为协议栈其实是在计数段数与reordering的关系,而不是字节数。运行如下packetdrill脚本并抓包:
如注释中的问题,会触发快速重传吗?显然不会!但是原因真的是因为SACK字节数不够3*1000吗?非也!
试着将packetdrill脚本中的
显然,Linux是根据段数来触发快速重传的,而不是根据字节数。
什么叫盲目?对待一个事物根本还没琢磨透就想在上面玩创新,这就是盲目。这种盲目与新文化运动前后中国文化青年内心的迷茫还有大不同,那种迷茫更多的是因为旧规则已然被打碎,新规则尚未确立,在新旧之间的那种夹层里,人的内心是痛苦的。然而,不破而立这种盲目却着实不是这种夹层里的感觉,而是一种自大的狂妄。
如果说你要证明你的东西是好的,首先你要有一个不好的做参照,而不是拿一个你尚未琢磨透的东西做参照。这是当代青年的通病,当然我也是其中一员,然则我认识到这是一个大错。如果你有机会看现在IT领域的求职简历,侧重于研发的那种,你会发现各种精通,其内容往往都是大学必修课甚至选修课的目录,还有就是看过几本书就谈精通,殊不知很多书的书名定义就有大错误!比如我经常吐槽的,中国人写的《JAVA网络编程》,《Windows网络编程》...看完了之后,让人学会了JAVA编程,学会了Windows编程,却完全忘了网络,这些书与网络有关吗?
仅仅知道socket接口的调用,就说自己精通网络,然后大评特评BGP协议怎么不好,VLAN标准应该如何改造...此人太猛。这种态度往往都是初学者携带的特征,我老婆是学日语的,记得刚上大一那会儿,她每到超时,看到各种包装袋上只要写有日语,就会出声朗读一番,后来随着她过了一级,读了研究生...现在再也不会出声朗读了。一般的初学者往往会觉得什么都很简单,其实揭开表明那层膜,下面的水非常深,要想有真正自己的东西,把这水淌浑是必不可少的。
因此,本文特出两道题,试考一下温州皮鞋厂老板。
问题1:请描述TCP快速重传的细节
场景描述:
假设TCP进入快速重传时有以下的序列:
你能给出重传的序列吗?
答案:
重传的序列如下:
问题解析
这里到了问题1的正文。TCP在快速重传的时候,会依照以下的优先级来传输数据段:
优先级1:标记为LOST的数据段
优先级2:新的尚未发送的数据段
优先级3:在UNA和HIGH区间内没有标记为LOST,没有标记为SACKed,没有重传过的数据段
下面我来解释一下这三类数据段各自是怎么定义的。
首先,优先级1所述的标记为LOST的数据段是由RFC3517的IsLost例程定义的,其定义如下:
IsLost (SeqNum):
This routine returns whether the given sequence number is
considered to be lost. The routine returns true when either
DupThresh discontiguous SACKed sequences have arrived above
'SeqNum' or (DupThresh * SMSS) bytes with sequence numbers greater
than 'SeqNum' have been SACKed. Otherwise, the routine returns
false.
我们以下仍然以问题1的场景描述中的图示来解析,时不时的可能会变动一下细节,但不伤大雅。
Linux在实现快速重传的时候,依照RFC3517的建议维护了一个计分板,该计分板中统计了哪些数据段是SACKed的,哪些数据段是LOST的,我们发现,上图正好是一个计分板的绝佳体现。
在计分板上标记LOST数据段的时候,其要求是要满足RFC3517的IsLost例程,简单点说,就是任何一个被标记为LOST的数据段后面都要有至少DupThresh个被SACKed的数据段。为了满足这个要求,我们在计分板(也就是上图)中标记LOST数据段的方法也就简单了:
从前往后遍历,只要碰到没有被SACKed的数据段就标记为LOST,遍历的过程以SACKed数据段剩余DupThresh个时停止!
因此, 可以在遍历的过程中数SACKed数据段的数量,记为cnt,直到cnt的数量达到SACKed数据段总量与DupThresh的差为止退出。在Linux中,这个逻辑正是由函数tcp_mark_head_lost来实现的,可以查看Linux源码详细研究该函数,本文就不再赘述了。但是还是给出伪代码,如下:
for each skb in write-queue
if skb.SACKed == TRUE
cnt++
if cnt > SACKed_count - DupThresh
break
if skb.SACKed == FALSE
skb.LOST = TRUE现在我们的计分板更新了,如下所示:

现在看优先级2传输的数据段,即尚未发送的新数据,也就是说在图中HIGH标记之后的数据段。这里也许你会有一点困惑,为什么新数据的传输优先级会更高。简单的解释就是,LOST标记的数据段数量是由SACKed数据段的数量决定的,理论上在数据包守恒的原则下二者是相等的,但考虑到网络乱序的存在,LOST标记的数据段数量会比SACKed数据段数量少一些,二者之差就是一个乱序度的度量值,也就是RFC3517中的DupThresh。因此,剩下那些既没有被SACKed,又没有标记为LOST的数据段,我们称为未决数据。理论上它们没有丢失,只是还在路上,之所以还没有收到ACK或者SACK的原因有三类:
1).乱序了
2).慢了
3).ACK丢了
不管是哪一个原因,它们并没有丢,起码是理论上认为它们并没有丢失,所以此时还需要再等待一下,不管是乱序了,慢了,还是ACK丢了,再等一下都是可以等到确认的,因此此时这类数据段的传输优先级自然就没有新的数据更高,于是在传输完LOST标记的数据段后,就要传输新数据,而不是上述的未决数据。
最后,我们想一下最坏的可能性,即那些未决数据真的丢失了,这很可能是我们的预判过于乐观了,当这些未决数据真的丢失了时,滑动窗口会因为它们而被阻滞无法前行,因此必须在合适的时候去重传它们,这个时机可以尽可能地保守向后,于是它们的传输优先级自然而然也就排在了新数据之后了。
现实场景确认
如果仅仅是上面的理论分析,可能会比较枯燥,另外也不便于彻底理解,你只有看到它实实在在就是那样运作的,才能放心。本节用实例来打消最后的疑惑。依然采用packetdrill,脚本如下:+0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
// 三次握手
+0 < S 0:0(0) win 32792 <mss 1000, sackOK, nop, nop, nop, wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 257
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 257
// 随意写一些数据
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 4001 win 257
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 5001 win 257
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 6001 win 257
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 7001 win 257
// 场景自此开始
+0 write(4, ..., 1000) = 1000 // seq:7001-8001
+0 write(4, ..., 1000) = 1000 // seq:8001-9001
+0 write(4, ..., 1000) = 1000 // seq:9001-10001
+0 write(4, ..., 1000) = 1000 // seq:10001-11001
+0 write(4, ..., 1000) = 1000 // seq:11001-12001
+0 write(4, ..., 1000) = 1000 // seq:12001-13001
+0 write(4, ..., 1000) = 1000 // seq:13001-14001
+0 write(4, ..., 1000) = 1000 // seq:14001-15001
+0 write(4, ..., 1000) = 1000 // seq:15001-16001
+0 write(4, ..., 1000) = 1000 // seq:16001-17001
// 此时窗口已经塞满(初始窗口为10),17001-18001仅仅pending到发送队列,未实际发送
+0 write(4, ..., 1000) = 1000 // seq:17001-18001
// 窗口为10
+0 %{ print tcpi_snd_cwnd }%
// 我关闭了fack,以下仅仅触发sack的快速重传
+0 < . 1:1(0) ack 7001 win 257 <sack 8001:12001 13001:14001, nop, nop>
// 这里预期会重传7001-8001,由于窗口还够传1个段,预期还会传输尚未发送的17001-18001
+0 < . 1:1(0) ack 7001 win 257 <sack 8001:12001 13001:16001, nop, nop>
// 由于前面又SACK了2个新段14001-16001,按照计分板标记LOST的规则,会将12001-13001标记为LOST进而重传
// 请注意:如果上述SACK中的SACK段是8001:12001 13001:14001而不是8001:12001 13001:16001,则12001-13001依然会重传,只不过是作为未决数据的前向重传!
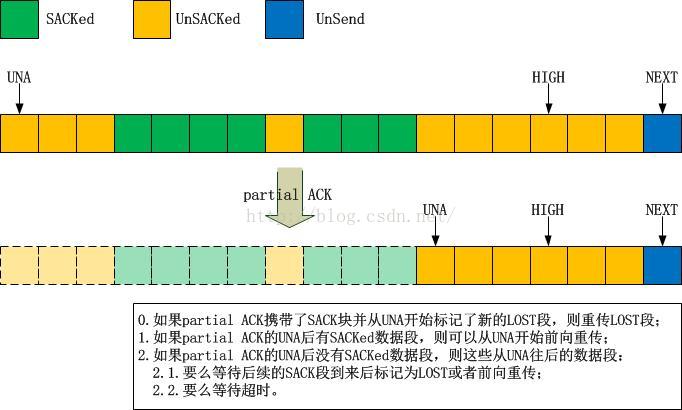
+0 < . 1:1(0) ack 16001 win 257 // 收到16001的ACK,此ACK为partial ACK(New Reno里规定)
// partial ACK后,无新数据,但依然有未决数据16001-18001,它们会不会被重传呢?这个问题下面在正文中解答!
+0 write(4, ..., 10) = 10
// 直到write过后,发送新的10字节数据
// 最后,发语辞,无意义,类似“呜呼”这样的...
+10.000 < . 1:1(0) ack 18001 win 257我不喜欢用packetdrill本身的“预期”,我觉得这个packetdrill本身的机制就是垃圾(它并没有支持除了它调通的之外的情况!)!于是,我自己来预期...我还是用tcpdump来最终确认,图示如下:

现在来解释上述packetdrill脚本中那个注释的疑问,即如果收到了partial ACK,并且其后面一直到HIGH再也没有被SACK的数据段,那么这些段会被重传吗?答案是不会!那么这里就有一个风险,万一它们真的丢了怎么办?!答案是只能等后续的SACK或者超时了!我来总结一下关于partial ACK后的重传吧:
误区之所在
我已经阐述了理论,但是不足,于是我阐述了上面的一个实例,然而还是不足,不足在哪里呢?不足在于,很多的逻辑会混淆在一起,比如优先级1和优先级3的数据段混淆在一起发送的话,你会认为这是通过一个机制发送的两个数据段还是通过两个机制分别发送的两个数据段呢?于是,我觉得有必要说一说。我先给出一个packetdrill脚本:+0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
//+0 fcntl(3, F_SETFL, O_NONBLOCK) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000, sackOK, nop, nop, nop, wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 257
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 257
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 4001 win 257
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 5001 win 257
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 6001 win 257
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 7001 win 257
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000 seq:15001-16001
// 注意,我只发了9个数据段!
+0 %{ print tcpi_snd_cwnd }%
+0 < . 1:1(0) ack 7001 win 257 <sack 8001:12001 13001:14001, nop, nop>
// 此时,应该重传7001-8001这是显然的,然而你会发现,连12001-13001也重传了,这是为什么呢?难道12001-13001也被标记为LOST了么?非也!
// 最后,发语辞,无意义,类似“呜呼”这样的...
+10.000 < . 1:1(0) ack 18001 win 257和之前的packetdrill脚本不同的是,我不再发送太多的数据,而只是发送到14001为止。
此时,你会看到,数据段7001-8001和12001-13001同时被重传了,这是怎么回事呢?如果你初看,那么你会觉得TCP的重传逻辑一次性重传了所有的“空洞”,即7001-8001以及12001-13001,然而事实上7001-8001段和12001-13001段这两个段,并不是按照同一个机制传输出去的,第一个7001-8001数据段是优先级1的传输使然,而12001-13001数据段则是优先级3的传输使然!tcpdump的结果如下:

问题2:请描述快速重传被触发的细节
这个问题相对比较简单,答案如下:是否触发重传,不仅仅取决于被ACK/SACK的字节数与reordering*MSS的关系,还取决于发送的skb的大小。
假设当前的MSS为1000,reordering的值为3,那么是不是一定要重复确认的字节数超过3000才会触发快速重传呢?答案是否定的!因为协议栈其实是在计数段数与reordering的关系,而不是字节数。运行如下packetdrill脚本并抓包:
+0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000, sackOK, nop, nop, nop, wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 257
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+0 > P. 1:1001(1000) ack 1
+.1 < . 1:1(0) ack 1001 win 257
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
// 注意这里只发10个字节,即将10个字节封装在一个数据段中。
+0 write(4, ..., 10) = 10
+0 write(4, ..., 1000) = 1000
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 257 <sack 2001:3001, nop, nop>
+0 < . 1:1(0) ack 1001 win 257 <sack 2001:4001, nop, nop>
+0 < . 1:1(0) ack 1001 win 257 <sack 2001:4002, nop, nop>
// 此时SACK了2001个字节,显然不够1000*3字节,会触发快速重传吗?
+.1 < . 1:1(0) ack 6001 win 257如注释中的问题,会触发快速重传吗?显然不会!但是原因真的是因为SACK字节数不够3*1000吗?非也!
试着将packetdrill脚本中的
+0 write(4, ..., 10) = 10+0 write(4, ..., 1) = 1显然,Linux是根据段数来触发快速重传的,而不是根据字节数。
后记与吐槽
正如我敢说,玩OpenVPN的人,大多数只是虚玩,根本很少人懂一样。不破而立也是虚的。什么叫盲目?对待一个事物根本还没琢磨透就想在上面玩创新,这就是盲目。这种盲目与新文化运动前后中国文化青年内心的迷茫还有大不同,那种迷茫更多的是因为旧规则已然被打碎,新规则尚未确立,在新旧之间的那种夹层里,人的内心是痛苦的。然而,不破而立这种盲目却着实不是这种夹层里的感觉,而是一种自大的狂妄。
如果说你要证明你的东西是好的,首先你要有一个不好的做参照,而不是拿一个你尚未琢磨透的东西做参照。这是当代青年的通病,当然我也是其中一员,然则我认识到这是一个大错。如果你有机会看现在IT领域的求职简历,侧重于研发的那种,你会发现各种精通,其内容往往都是大学必修课甚至选修课的目录,还有就是看过几本书就谈精通,殊不知很多书的书名定义就有大错误!比如我经常吐槽的,中国人写的《JAVA网络编程》,《Windows网络编程》...看完了之后,让人学会了JAVA编程,学会了Windows编程,却完全忘了网络,这些书与网络有关吗?
仅仅知道socket接口的调用,就说自己精通网络,然后大评特评BGP协议怎么不好,VLAN标准应该如何改造...此人太猛。这种态度往往都是初学者携带的特征,我老婆是学日语的,记得刚上大一那会儿,她每到超时,看到各种包装袋上只要写有日语,就会出声朗读一番,后来随着她过了一级,读了研究生...现在再也不会出声朗读了。一般的初学者往往会觉得什么都很简单,其实揭开表明那层膜,下面的水非常深,要想有真正自己的东西,把这水淌浑是必不可少的。
因此,本文特出两道题,试考一下温州皮鞋厂老板。

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









