







一、前言
1. 版本:
Hadoop 源码版本: Version 2.7.1
2. HDFS读一个文件的流程图
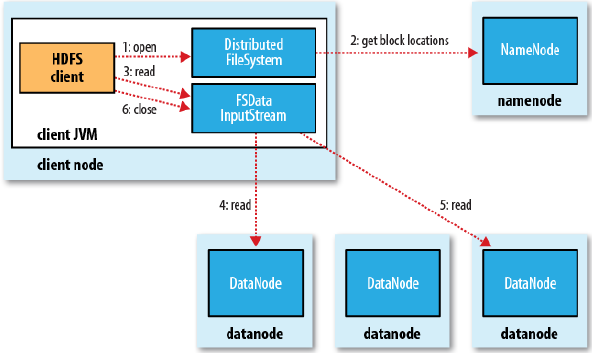
二、回顾区
用户的App通过调用流程FileSystem.open->DistributedFileSystem.open->DFSClient.open->new DFSInputStream()后,获取到了要读取文件的所有blocks信息(文件长度、文件包含的Block的位置等信息)并保存在DFSInputStream对象的成员变量里。由于block可能是本地的或者远程的,它们分别是怎么被读的?
三、预热区(数据结构)
- block: The hdfs block, typically large (~128MB). For more, pls refer to src RemoteBlockReader2.java in Hadoop Project
- chunk: A block is divided into chunks, each comes with a checksum. We want transfers to be chunk-aligned, to be able to verify checksums.
- packet: A grouping of chunks used for transport. It contains a header, followed by checksum data, followed by real data. For more, pls refer to src PacketReceiver.java and PacketHeader.java in Hadoop Project.
HDFS中进行通信的数据包(Packet)的格式如下:
+-----------------------------------------------------------------------+
| 4 byte packet length(exclude packet header) |
+------------------------------------------------------------------------+
| 8 byte offset in the block | 8 byte sequence number |
+------------------------------------------------------------------------+
| 1 byte isLastPacketInBlock |
+------------------------------------------------------------------------+
| 4 byte Length of actual data |
+-------------------------------------------------------------------------+
| x byte checksum data. x is defined below |
+-------------------------------------------------------------------------+
| actual data ......... |
+--------------------------------------------------------------------------+
x = (length of data + BYTE_PER_CHECKSUM - 1) / BYTE_PER_CHECKSUM * CHECKSUM_SIZE
- LocatedBlocks:LocatedBlocks在hdfs读取文件时调用openInfo()方法,最终调用的是DFSInputStream的fetchLocatedBlocksAndGetLa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









