






前言
使用c语言实现单链表的一些操作。
一、单链表
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。下面为单链表的一个结点的定义。
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
使用上面定义的结点,可以创建其他的结点,并且将这些结点链接起来。
下面就是创建了4个结点,并且给每个结点的数据域都赋值了,然后将指针域也赋值了,这样这些结点就已经链接起来了,通过首结点就可以访问后面的结点了。
void Test1()
{
struct SListNode* n1 = (struct SListNode*)malloc(sizeof(struct SListNode));
assert(n1);
struct SListNode* n2 = (struct SListNode*)malloc(sizeof(struct SListNode));
assert(n2);
struct SListNode* n3 = (struct SListNode*)malloc(sizeof(struct SListNode));
assert(n3);
struct SListNode* n4 = (struct SListNode*)malloc(sizeof(struct SListNode));
assert(n4);
n1->data = 1;
n2->data = 2;
n3->data = 3;
n4->data = 4;
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;
}
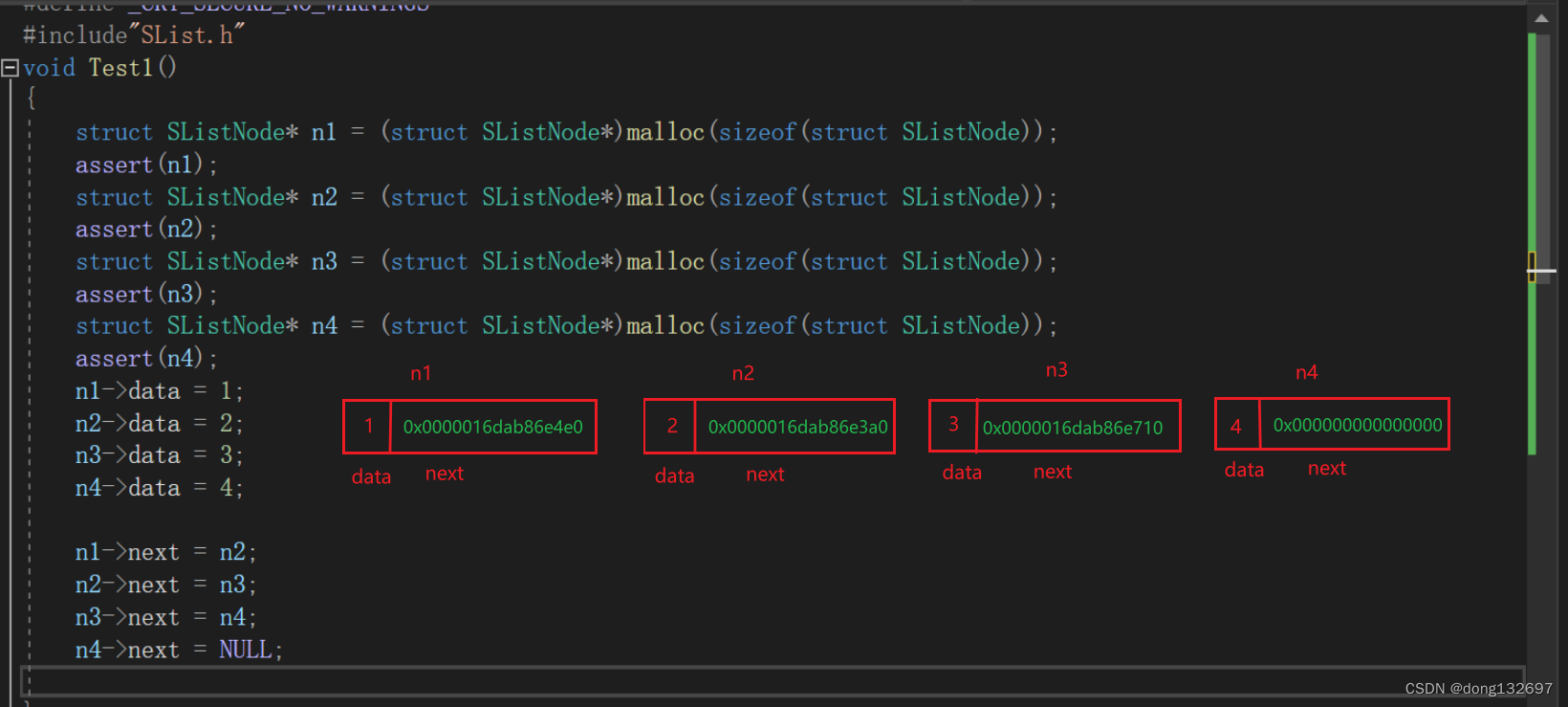
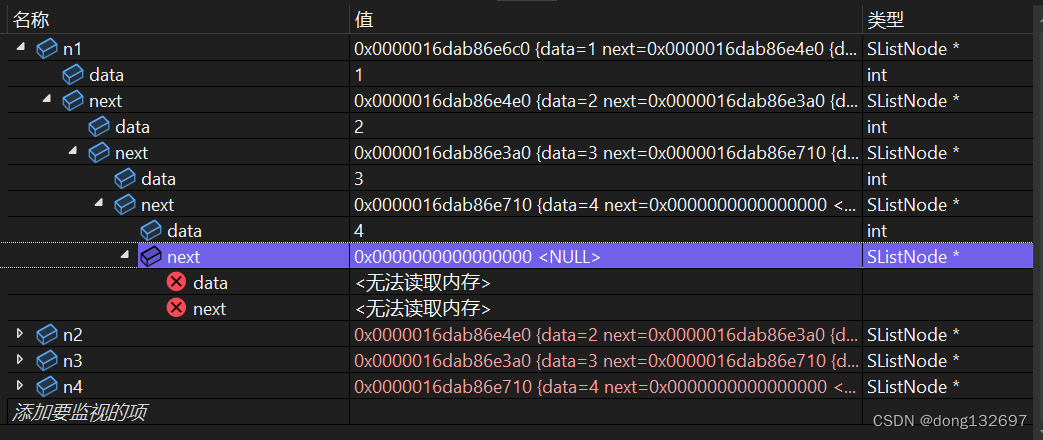
从上面的两个图可知n1~n4都是结构体指针,而单链表的结点定义时,next成员变量定义的类型也是结构体指针,所以可以通过n1结点的next指针得到n2结点,然后依次类推得到后面的结点。通过这个思想,我们可以写一个函数来遍历单链表中所有结点的数据。即代码如下
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead; //得到单链表的头节点
while (cur != NULL) //如果cur不是单链表的尾结点,就继续向后访问
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n"); //尾结点的next指针指向NULL
}
上述方法可以通过传进来的头节点来遍历单链表的所有结点,当我们需要在单链表尾部插入一个数据时,我们可以进行这样的操作。
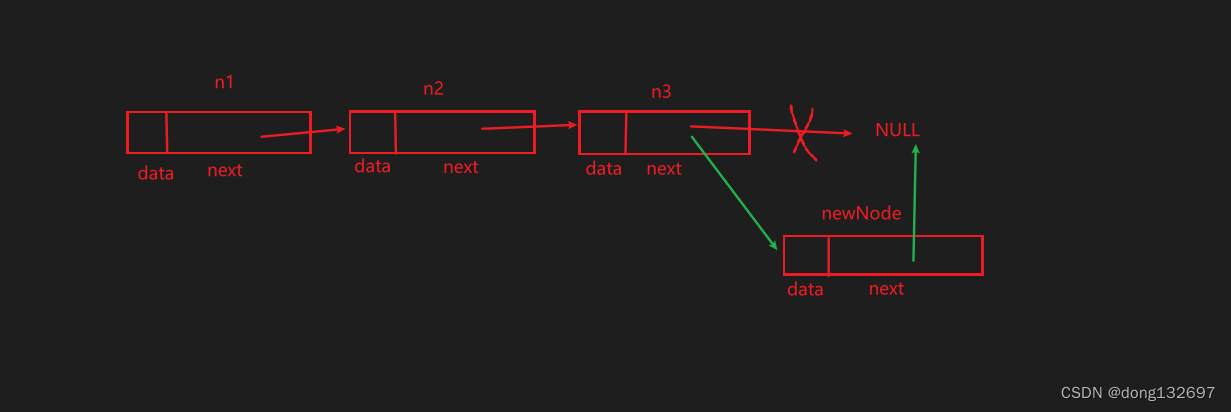
代码实现为
void SListPushBack(SLTNode* phead, SLTDataType x)
{
assert(phead);
SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode)); //申请一个新的结点
assert(newNode);
newNode->data = x; //将新结点的数据域设为指定值
newNode->next = NULL; //将新结点的next指针域置为NULL,即新结点为尾结点
//找单链表的尾结点
SLTNode* tail = phead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newNode;
}
测试代码为
void Test2()
{
SLTNode* ps = (SLTNode*)malloc(sizeof(SLTNode));
ps->data = 1;
ps->next = NULL;
SListPushBack(ps, 2);
SListPushBack(ps, 3);
SLTNode* ps2 = NULL;
SListPushBack(ps2, 1);
//ps = NULL;
SListPrint(ps);
SListPrint(ps2);
}
使用此方法可以在得到一个不为NULL的头节点后,在该结点后面插入新的结点,但是如果该方法传入的为一个空单链表时,即该单链表没有一个元素,首节点为NULL,此时该方法就不再适用,因为此时单链表里面没有一个结点,所以此时插入的结点就为单链表的首节点,故要使测试代码中结构体指针ps2指向新创建的结点,就要修改ps2的值为新结点的地址,所以要想在SListPushBack()函数中修改ps2的值,就要在调用时传入ps2的地址,这样在SListPushBack()函数里面解引用ps2的地址才能改变ps2的值。而又因为ps2为结构体指针,所以接收ps2地址的指针为二级指针,此时SListPushBack()需要这样定义,SListPushBack(SLTNode** pphead,SLTDataType x)。该方法实现如下。
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode)); //创建一个新结点
assert(newNode);
newNode->data = x;
newNode->next = NULL;
if (*pphead == NULL) //如果单链表为空,就使新结点为单链表的首结点。
{
*pphead = newNode;
}
else
{
//找单链表的尾结点
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newNode;
}
}
实现了单链表的尾部插入新结点,我们可以通过如图的思想来实现头部插入新结点。
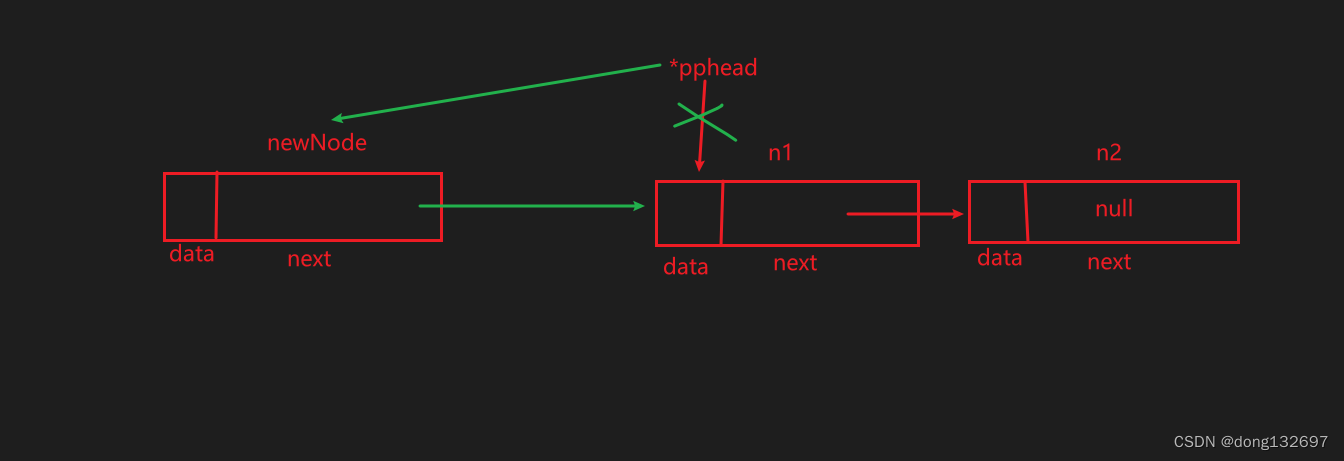
因为头部插入和尾部插入都需要创建新结点,所以我们可以直接写一个函数来创建新结点,并且该函数将结点的地址返回。
SLTNode* CreateListNode(SLTDataType x)
{
SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode));
assert(newNode);
newNode->data = x;
newNode->next = NULL;
return newNode;
}
接下来我们就可以通过该方法得到一个新结点,并且使用头部插入的方法将该结点插入到单链表中。
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newNode = CreateListNode(x); //得到一个新结点
newNode->next = *pphead;
*pphead = newNode; //此时将*pphead指向新结点,即新结点为单链表首结点
}
当我们实现了单链表结点的尾插法和头插法后,接下来就是实现尾删法和头删法。
尾删法实现时需要考虑单链表是否为空表,如果单链表为空表,则不可以删除结点;如果单链表只有一个结点时,删除结点后,单链表为空表。这两种情况都需要单独处理。尾删法具体实现代码如下。
void SListPopBack(SLTNode** pphead)
{
assert(*pphead); //当单链表为空表时,无法删除
if ((*pphead)->next == NULL) //当单链表只有一个结点时,删除尾结点后,单链表为空
{
free(*pphead); //释放删除的结点空间
*pphead = NULL;
}
else
{
//SLTNode* tail = (*pphead)->next;
//SLTNode* tailPre = *pphead;
//while (tail->next != NULL)
//{
// tail = tail->next;
// tailPre = tailPre->next;
//}
//tailPre->next = NULL;
//free(tail); //释放删除的结点空间
//还可以使用下面这种写法
SLTNode* tail = *pphead;
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
头删法也需要单独处理尾删法遇到的那两种情况。代码如下。
void SListPopFront(SLTNode** pphead)
{
assert(*pphead); //如果为空表,则无法删除
if ((*pphead)->next == NULL) //当单链表只有一个结点时,删除头结点后,单链表为空
{
free(*pphead); //释放删除的结点空间
*pphead = NULL;
}
else
{
SLTNode* tmp = *pphead;
*pphead = (*pphead)->next;
free(tmp); //释放删除的结点空间
tmp = NULL;
}
}
当单链表的增删操作都实现后,就该实现单链表的查找元素了,如果查到该结点,就将该结点的地址返回。
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
assert(phead);
SLTNode* tmp = phead;
while (tmp != NULL)
{
if (tmp->data == x)
{
return tmp;
}
tmp = tmp->next;
}
return NULL;
}
查找结点的函数还可以用来修改结点的数据域和指针域。
void Test4()
{
SLTNode* ps = (SLTNode*)malloc(sizeof(SLTNode));
ps = NULL;
SListPushBack(&ps, 1);
SListPushBack(&ps, 2);
SListPushBack(&ps, 3);
SListPushBack(&ps, 4);
SLTNode* ret = SListFind(ps, 3);
if (ret)
{
printf("找到了\n");
ret->data = 30; //查找到结点后还可以修改结点的数据域和指针域
}
SListPrint(ps);
}
单链表还可以实现在给定结点之前插入一个结点,此时需要遍历整个单链表,并且还要记录给定结点的前一个结点,这样才能实现插入,并且当给定结点为头结点时,此时为头插法,所以直接调用前面的头插法即可。
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);
assert(pphead);
if (*pphead == pos)
{
SListPushFront(pphead, x);
}
else
{
SLTNode* tmp = *pphead;
while (tmp->next != pos)
{
tmp = tmp->next;
}
SLTNode* newNode = CreateListNode(x);
newNode->next = tmp->next;
tmp->next = newNode;
}
}
单链表删除给定结点时,需要先遍历整个单链表,并且记录给定结点的前一个结点,让前一个结点的next指针等于给定结点的next指针,然后释放给定结点所占用的空间,这样就实现了删除给定结点。当给定结点为单链表头结点时,这时只需调用头删法即可。
void SListErase(SLTNode** pphead, SLTNode* pos)
{
assert(pos);
assert(pphead);
if (pos == *pphead)
{
SListPopFront(pphead);
}
else
{
SLTNode* pre = *pphead;
while (pre->next != pos)
{
pre = pre->next;
}
pre->next = pos->next;
free(pos);
pos = NULL;
}
}
因为单链表中在给定结点之前插入结点和删除给定结点都需要遍历单链表,所以两种方法的时间复杂度都为O(N),在实际应用中,都是在给定结点之后插入结点和删除给定结点之后的结点,这样只需要知道给定结点即可,并且实现两种方法的时间复杂度为O(1)。因为是在给定结点之后插入或删除,所以默认单链表不为空,故不需要使用二级指针,只需要知道指向给定结点的指针即可,然后通过这个指针改变该结点的next指针域。
在给定结点之后插入结点如下。
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
/*SLTNode* newNode = CreateListNode(x);
* 需要注意语句的执行顺序
newNode->next = pos->next;
pos->next = newNode;*/
//不在乎链接顺序
SLTNode* newNode = CreateListNode(x);
SLTNode* nextNode = pos->next;
pos->next = newNode;
newNode->next = nextNode;
}
删除给定结点之后的结点如下。当给定结点之后为NULL时,则不需要删除。
void SListEraseAfter(SLTNode* pos)
{
assert(pos);
if (pos->next == NULL)
{
return;
}
SLTNode* nextNode = pos->next;
pos->next = pos->next->next;
free(nextNode);
nextNode = NULL;
}
总结
单链表的特点是空间不需要提前开辟,在使用时再开辟空间,所以没有单链表满的情况。
单链表的插入和删除可以有时间复杂度为O(1)的方法实现。















 6760
6760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









