







FUCK,作为笔记我必须用我惯用词语。
前言,此系列文章仅为学习笔记,CrazySprite就是个FUCK。引擎的开发目标是跨平台,自己做些小游戏,所以学习是最重要的。肯定有很多人骂我是傻逼,为啥要自己写基础库。。。FUCK,我就喜欢。
首先下手的是vector,hashmap,linklist,其它的就没啥兴趣了。我没那么贱,自己重写一套STL。
先来张截图,csStructArray就是csArray<T,false,false,8>
说明一下,这个是ms的stl,stlport比这个快很多,不过主要是在hashmap和list上。但是不至于快几倍。
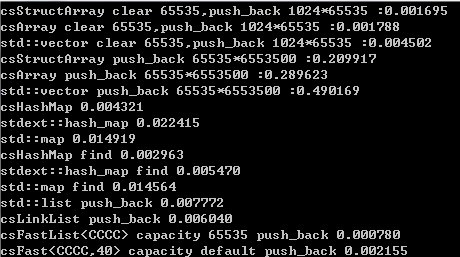
FUCK,首先是vector的实现。各种stl的实现基本是都2的指数级别增长, 那么试想一下,数组长度从1增长到1024,要重新分配好多次内存。。。但是如果干到几万,一次比如分配上65535。。。那又不知道要浪费多少。。。最后我选择的方式是capacity+(capacity*3)>>3+32,呼呼,当然不是我相到的。第二点,stl的对象创建和分配,这点没法避免,allocator也没法整,就算重写了allocator,也免不了一直跑循环,不过开销也很小的了多,但是我讨厌写这东西,内置支持了多好。所以我的array是这样定义的,template<typename T, bool NeedConstruct=true, bool NeedDestruct=true, s32 alignment=csALIGNMENT_DEFAULT>class csArray,恩,就是靠这两个参数,有点耍流氓的嫌疑。其实也可以用typeinfo来搞这俩信息,但是就跟特定的RTTI实现关联上了,FUCK,算了吧。vector要快要怎么办呢,有两点,一,用placement new创建对象,这要比每次单独分配快老多了,第二点,数组长度不够的时候,重新分配内存或者移动对象的时候,needconstruct和needdestruct是false就happy了,世界memmove,多开心。
FUCK,然后说说hashmap,ms的stl实现就是个悲剧,stlport好一些,查找几乎只比我的实现慢20%,甚至我如果把factor设置成2的快,比我还快。当然hashmap的hash函数相对于其它来说是最重要的。hashmap快的主要原因,是因为内部使用了csArray,给大伙看下数据结构,其它偶就不说了,没啥玩意:
template<typename K,typename V>
class csHashMap
{
struct Pair
{
csINLINE Pair(){}
csINLINE Pair(const K& k, const V& v):m_key(k),m_value(v){}
K m_key;
V m_value;
s32 m_hashNext;
};
protected:
s32 m_hashCount;
s32* m_hash;
csArray<Pair> m_pairs;
};
//------------------------------------------------------------------------
template<typename K,typename V> void
csHashMap<K,V>::_rehash()
{
csDELETE[] m_hash;
m_hash = csNEW s32[m_hashCount];
for( s32 i=0; i<m_hashCount; i++ )
{
m_hash[i] = csHASH_INDEX_NONE;
}
for( s32 i=0; i<m_pairs.size(); i++ )
{
Pair& p = m_pairs[i];
s32 iHash = (GetTypeHash(p.m_key) & (m_hashCount-1));
p.m_hashNext = m_hash[iHash];
m_hash[iHash] = i;
}
}
//------------------------------------------------------------------------
template<typename K, typename V> csINLINE void
csHashMap<K,V>::_relax()
{
while( m_hashCount>m_pairs.size()*csHASH_REHASH_FACTOR+8 )
{
m_hashCount /= 2;
}
_rehash();
}
基本上核心就是这几个吧
FUCK,最后说说LIST,这个是我用的时间最多的,第一版的实现虽然比MS的快一些,但是stlport的插入竟然比我快1倍!我完全不能忍。。。憋了有1,2天吧。。。看完了stlport list和malloc的实现,最后发现,他的核心竞争力依然是placement new,但是确有两点,限制住了他的速度,第一,他只有在对象小于128byte时候,才会只用placement new,第二,每次只分配20个对象的空间。FUCK,我继续耍流氓,首先,我实现了不同的csLinkList,这个没啥亮点,中规中矩,第二,要速度,就用csFastList,他是这样滴:
template<typename T, s32 PoolGrowStep=20>
class csFastList
{
protected:
Node* m_head;
s32 m_size;
//use to pre malloc memory
csArray<Node*,false,false> m_freeNodes;
csArray<MemoryBlock,false,false> m_memoryBlocks;
};
快就快在后面两个csArray上,快的原因就是用他们持有预分配的内存块,当然一次分配多少内存是可以控制的,第一次分配多少有个初始化函数是csFastList::csFastList(s32 capacity),如果够二的话,一次分配65535。。。然后在trim,把m_freeNodes浪费的内存回收了。。。同样插入65535个节点,速度是stlport的5-6倍。。。stl的十几倍。。。当然如果用和stlport一样的方法,初始化20,分配20,也会比stlport快一些。
FUCK,下一步写文件的管理。。。















 9064
9064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









