






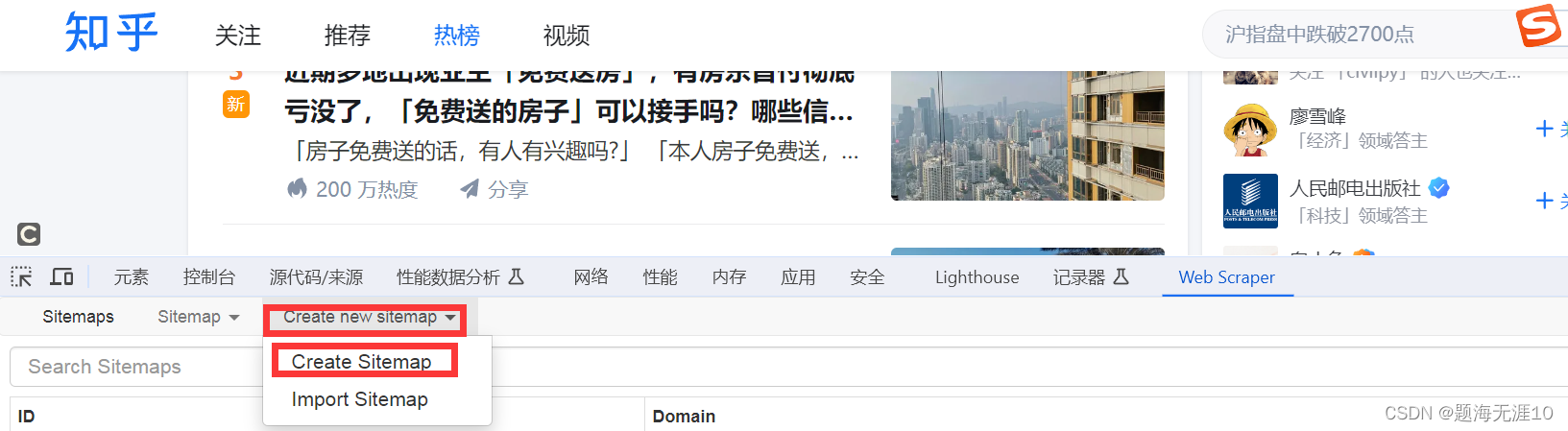
本节重点学习了以下内容
1、element与element click
2、重点理解主干与分支
3、理解multiple的用法
4、理解P的使用方法
5、没有涉及到翻页。
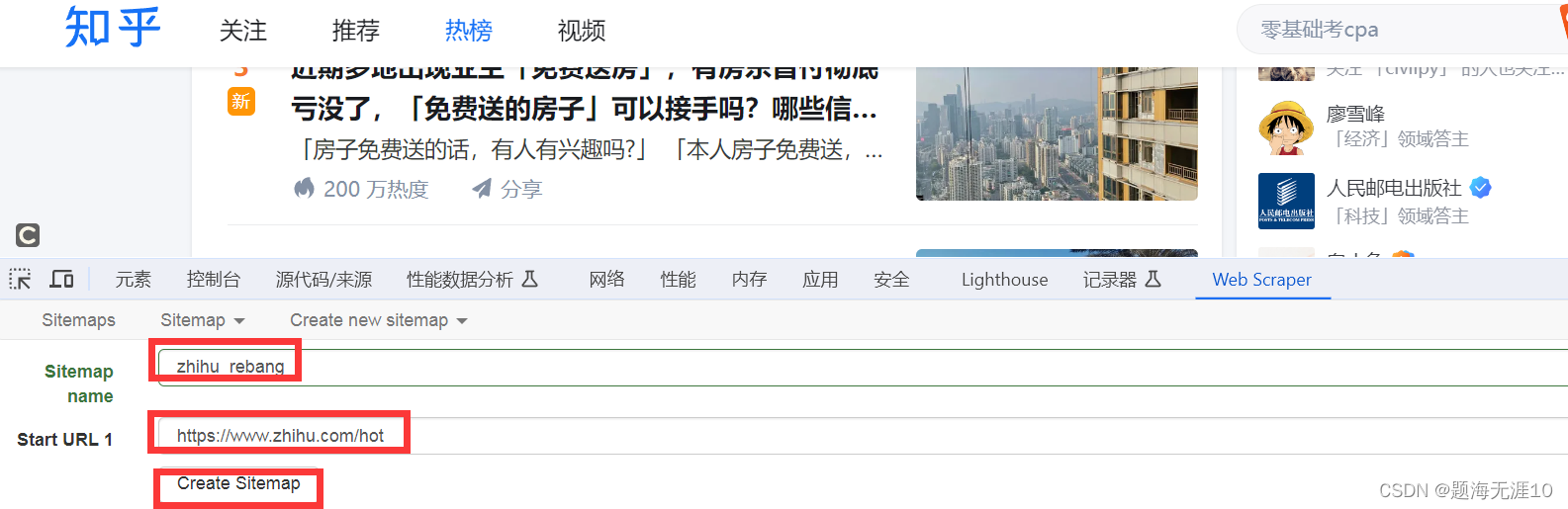
在根目录下建立一个选择器(白话:我想选择每个家庭的汇总信息)
 想选择每个家庭的,所以需要multiple
想选择每个家庭的,所以需要multiple

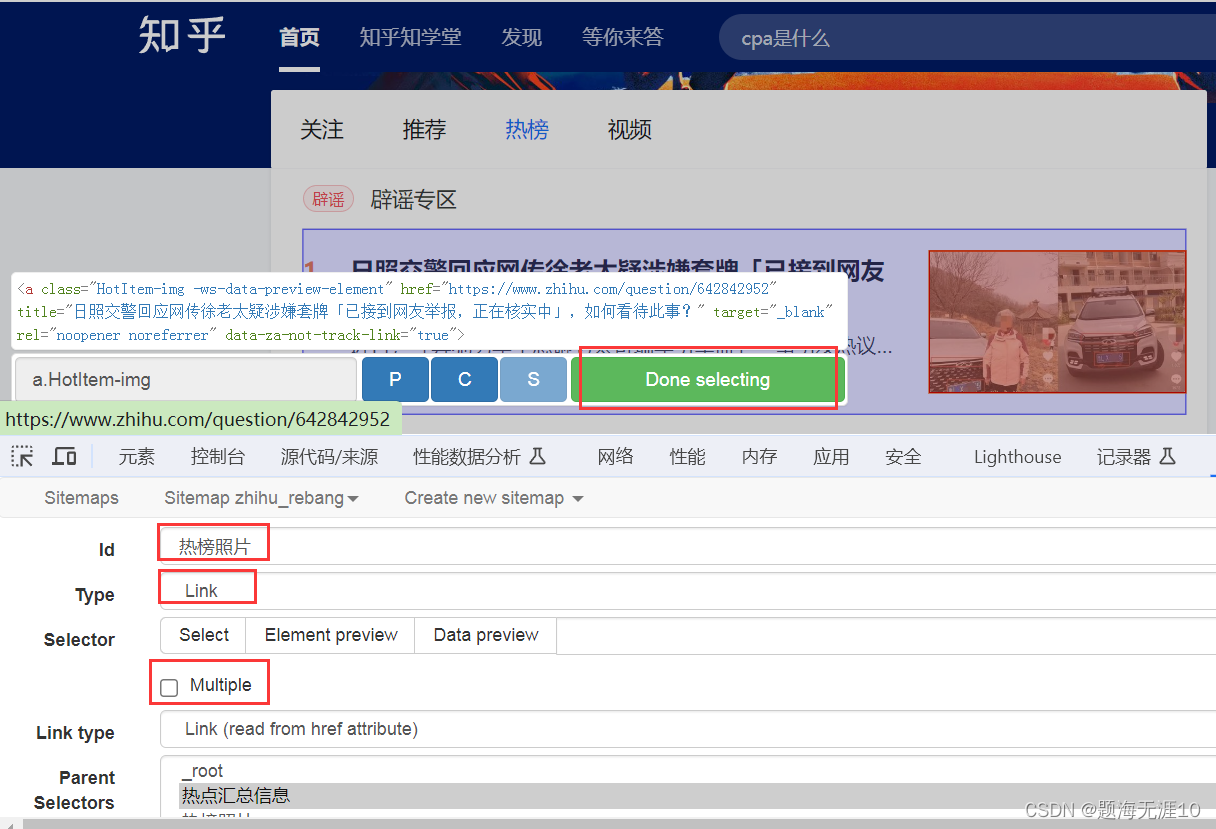
不要忘记Done selecting(其中的P的意思是连续选择,当需要连续的时间,可以按P)

然后需要点进这个“热点汇总信息”目录


再去抓取家庭中的信息
比如热榜标题(因为此时是单个家庭,所以不需要multiple)

热榜照片(因为我们是获取照片的链接,所以用link,有了链接,可以使用其他的工具下载图片)
 查看一下刚才的选择器,还可以预览Data preview
查看一下刚才的选择器,还可以预览Data preview
(这里有个问题,选择器的顺序不知道是否可以调)

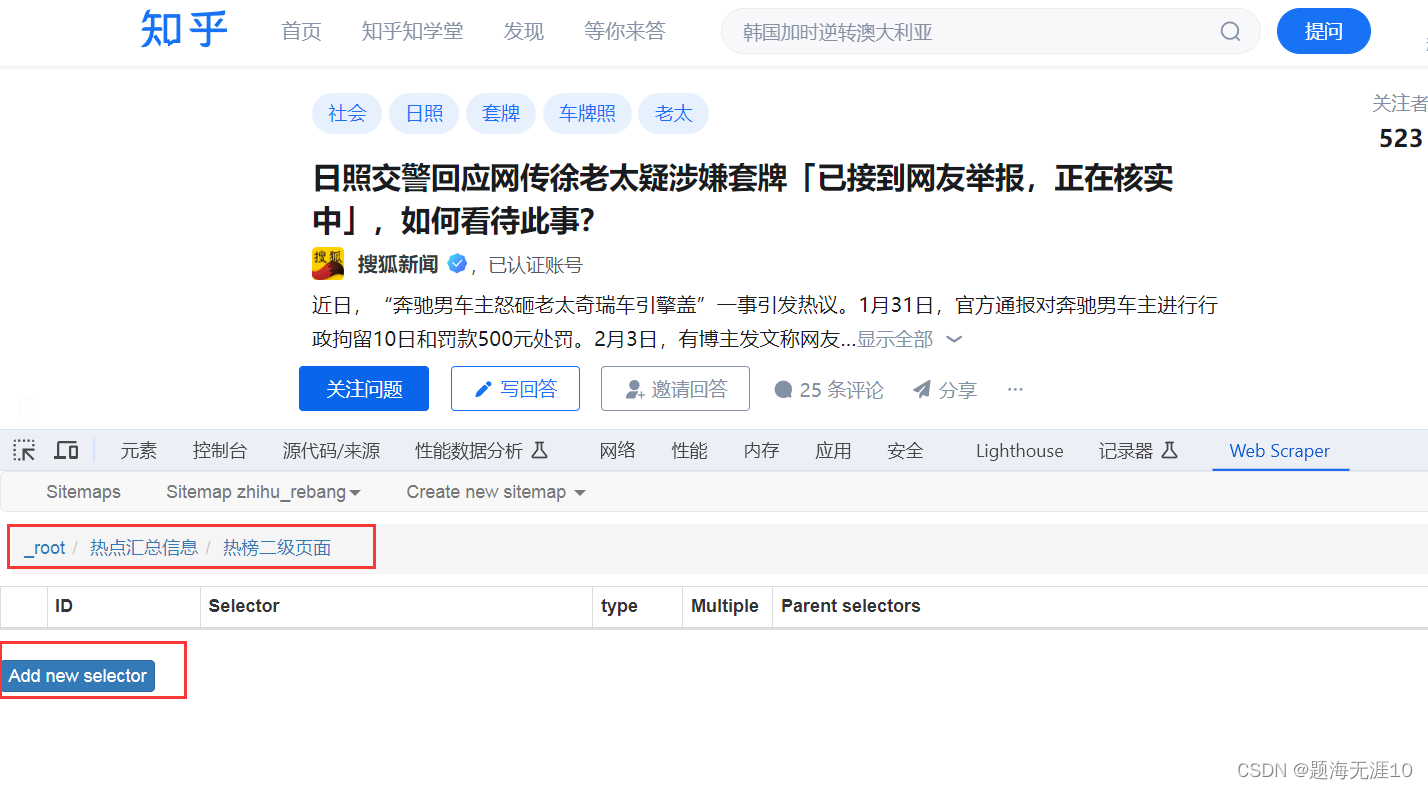
我还想爬取里面的家庭说明(这个需要点进去,到二级页面)那么需要用到link

下面一步要注意,①需要点进热榜二级页面进行爬取②需要在网页中点击到二级页面(这一步网页可能会跳转到新的网页,那么还需要按F12或者直接把跳转的新网页的链接,复制到刚才操作页面)
可以看到热榜内容需要点击“显示全部”
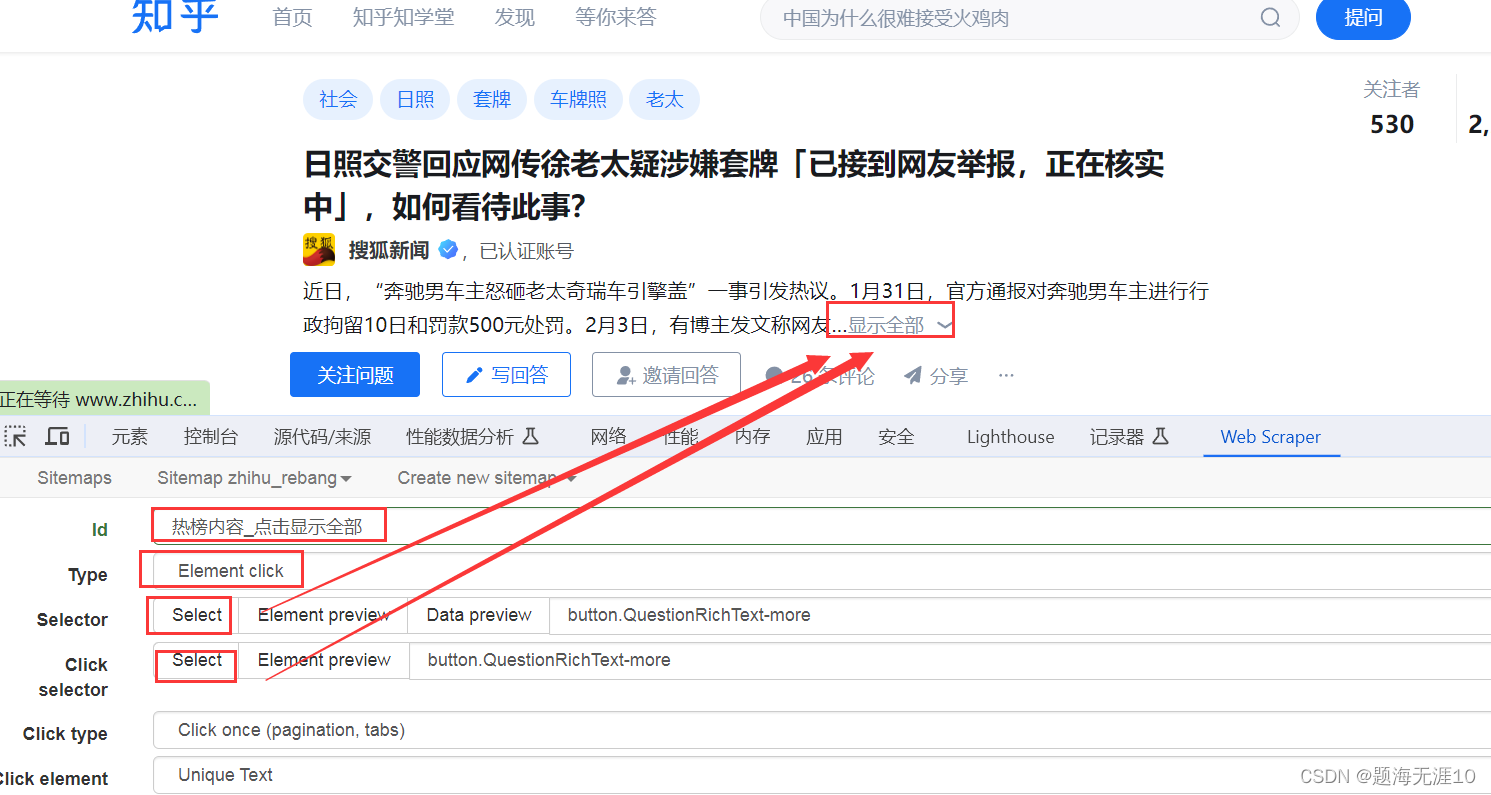
然后选择热榜文字,这里的文字可能有多段,需要点击multiple

最后点击爬取

这里的2000是表示2s
 导出excel或csv
导出excel或csv
 爬取后,发现有多行是一样的内容。(可能是在跳转二级链接后,选择文字使用了multiple的原因)
爬取后,发现有多行是一样的内容。(可能是在跳转二级链接后,选择文字使用了multiple的原因)

修改选择器


选择多段的时候,使用P,然后去掉multiple
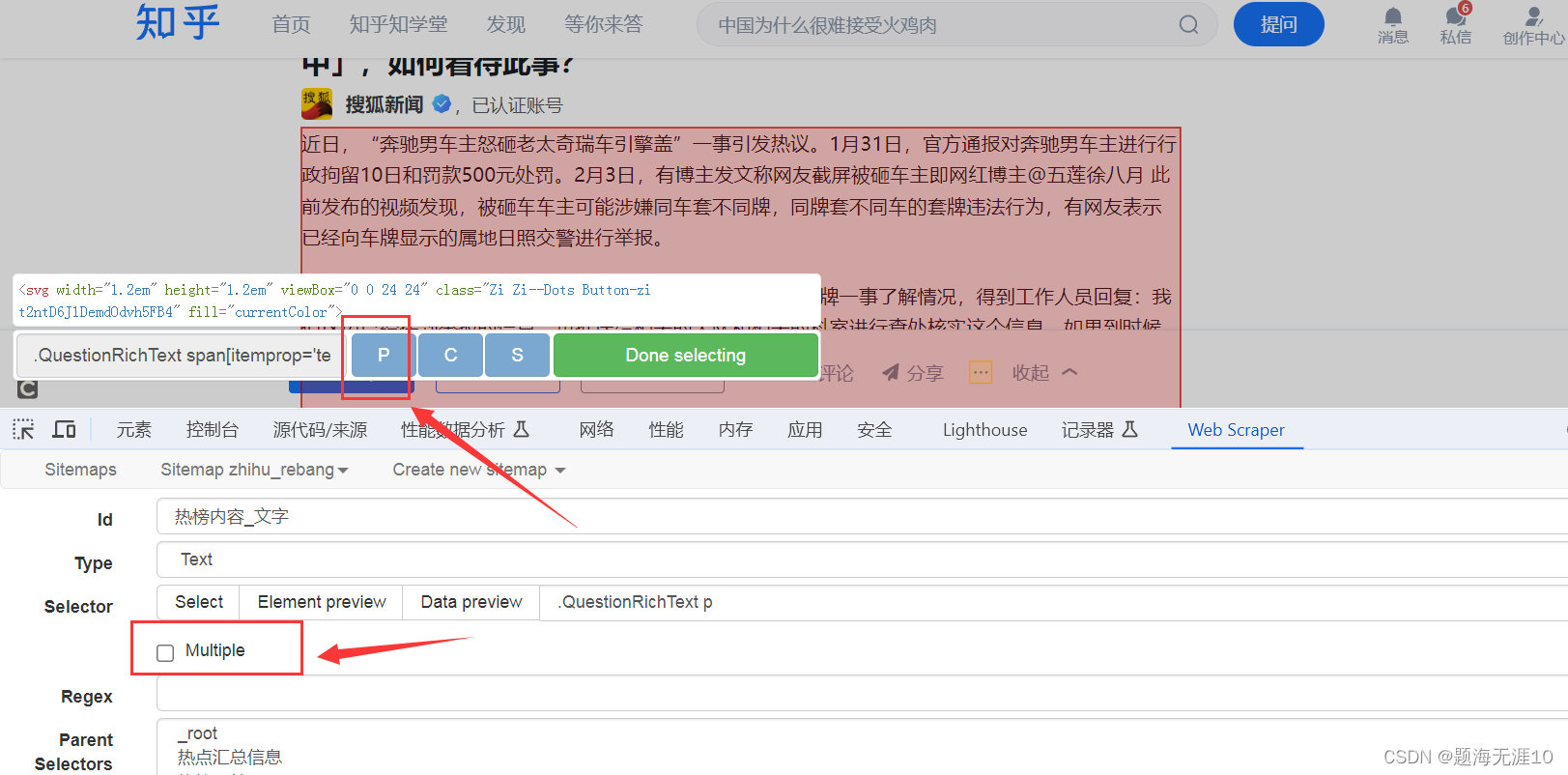
不显示数据的话可以点这个

结果图:
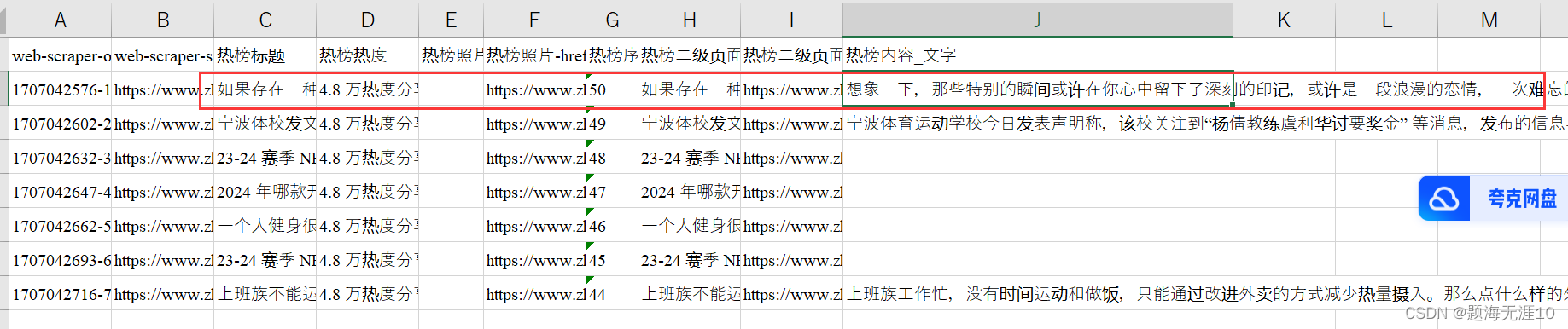

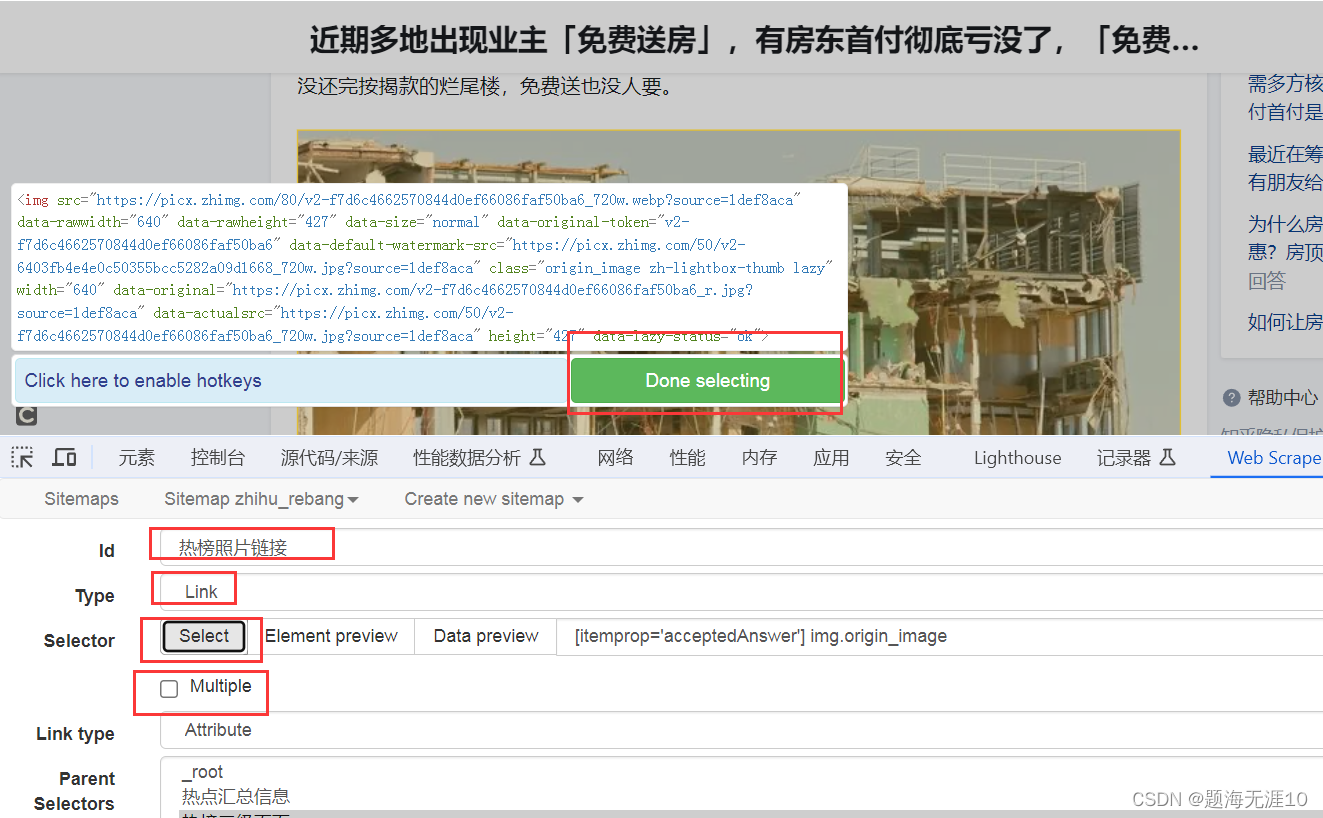
热榜照片的链接不正确,应该在热榜二级链接里面进行获取
点击进去,热榜二级页面,然后新建一个选择器(之前的照片链接那里可以删掉)
















 1339
1339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











