






一、Redis Cluster集群
Redis Cluster是Redis官方提供的分布式解决方案。当遇到内存、并发、流量等瓶颈时,就可以采用Cluster架构达到负载均衡目的。
1.为什么要用redis-cluster集群?
1.首先Redis单实例主要有单点,容量有限,流量压力上限的问题。 Redis单点故障,可以通过主从复制replication,和自动故障转移sentinel哨兵机制。但Redis单Master实例提供读写服务,仍然有容量和压力问题。 2.并发问题 redis官方声称可以达到 10万/每秒,每秒执行10万条命令 假如业务需要每秒100万的命令执行呢? 解决方案如下 1.正确的应该是考虑分布式,加机器,把数据分到不同的位置,分摊集中式的压力。那么一堆机器做一件事.还需要一定的机制保证数据分区,并且数据在各个主Master节点间不能混乱。 总结: redis cluster:主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster
从redis 3.0之后版本支持redis-cluster集群,它是Redis官方提出的解决方案:
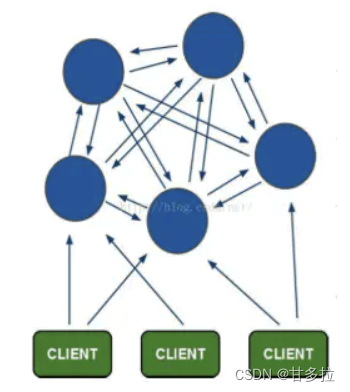
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。其redis-cluster架构图如下:
2.1.redis cluster特点
1.所有的redis节点彼此互联(PING-PONG机制)。 2.客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。 3.节点的fail是通过集群中超过半数的节点检测失效时才生效。
2.2redis-cluster数据分布
分布式数据分布方式为一致性hsah方式。 redis集群的hash slot方式: Redis集群中有16384个哈希槽,每个redis实例负责一部分slot,集群中的所有信息通过节点数据交换而更新。
2.3数据分布存储原理
Redis 集群使用数据分片(sharding)来实现:Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数(集群使用公式 CRC16(key) % 16384),这样每个key 都会对应一个编号在 0-16384 之间的哈希槽,那么redis就会把这个key 分配到对应范围的节点上了。同样,当连接三个节点任何一个节点想获取这个key时,也会这样的算法,然后内部跳转到存放这个key节点上获取数据。
例如三个节点:哈希槽分布的值如下:
cluster1: 0-5460 cluster2: 5461-10922 cluster3: 10923-16383
3、Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉. 1.主从切换机制 选举过程是集群中所有master参与,如果半数以上master节点与故障节点通信超过(cluster-node-timeout),认为该节点故障,自动触发故障转移操作. #故障节点对应的从节点自动升级为主节点 2.什么时候整个集群就不能用了? 如果集群任意一个主节点挂掉,且当前主节点没有从节点,则集群将无法继续,因为没有办法为这个节点承担范围内的哈希槽提供服务。但是,如果这个主节点和所对应的从节点同时失败,则Redis Cluster无法继续运行。
二、集群部署
环境准备: 1.准备三机器,关闭防火墙和selinux 2.制作解析并相互做解析。 注:规划架构两种方案,一种是单机多实例,这里我们采用多机器部署: 三台机器,每台机器上面两个redis实例,一个master一个slave,第一列做主库,第二列做备库 #记得选出控制节点 redis-cluster1 192.168.116.172 7000、7001 redis-cluster2 192.168.116.173 7002、7003 redis-cluster3 192.168.116.174 7004、7005
1.三台机器相同操作
1.安装redis
[root@redis-cluster1 ~]# mkdir /data
[root@redis-cluster1 ~]# yum -y install gcc automake autoconf libtool make [root@redis-cluster1 ~]# wget https://download.redis.io/releases/redis-7.0.9.tar.gz
[root@redis-cluster1 ~]# tar xzvf redis-6.2.0.tar.gz -C /data/
[root@redis-cluster1 ~]# cd /data/
[root@redis-cluster1 data]# mv redis-6.2.0/ redis
[root@redis-cluster1 data]# cd redis/
[root@redis-cluster1 redis]# make #编译
[root@redis-cluster1 redis]# mkdir /data/redis/data #创建存放数据的目录
编译完成的结果:
2.创建节点目录:按照规划在每台redis节点的安装目录中创建对应的目录(以端口号命名)
[root@redis-cluster1 redis]# pwd
/data/redis
[root@redis-cluster1 redis]# mkdir cluster #创建集群目录
[root@redis-cluster1 redis]# cd cluster/
[root@redis-cluster2 redis]# mkdir cluster
[root@redis-cluster2 redis]# cd cluster/
[root@redis-cluster2 cluster]# mkdir 7002 7003
[root@redis-cluster3 redis]# mkdir cluster
[root@redis-cluster3 redis]# cd cluster/
[root@redis-cluster3 cluster]# mkdir 7004 7005
3.拷贝配置文件到节点目录中,#三台机器相同操作
[root@redis-cluster1 cluster]# cp /data/redis/redis.conf 7000/
[root@redis-cluster1 cluster]# cp /data/redis/redis.conf 7001/
[root@redis-cluster2 cluster]# cp /data/redis/redis.conf 7002/
[root@redis-cluster2 cluster]# cp /data/redis/redis.conf 7003/
[root@redis-cluster3 cluster]# cp /data/redis/redis.conf 7004/
[root@redis-cluster3 cluster]# cp /data/redis/redis.conf 7005/
4.修改集群每个redis配置文件。(主要是端口、ip、pid文件,三台机器相同操作),修改如下:
[root@redis-cluster1 cluster]# cd 7000/
[root@redis-cluster1 7000]# vim redis.conf #修改如下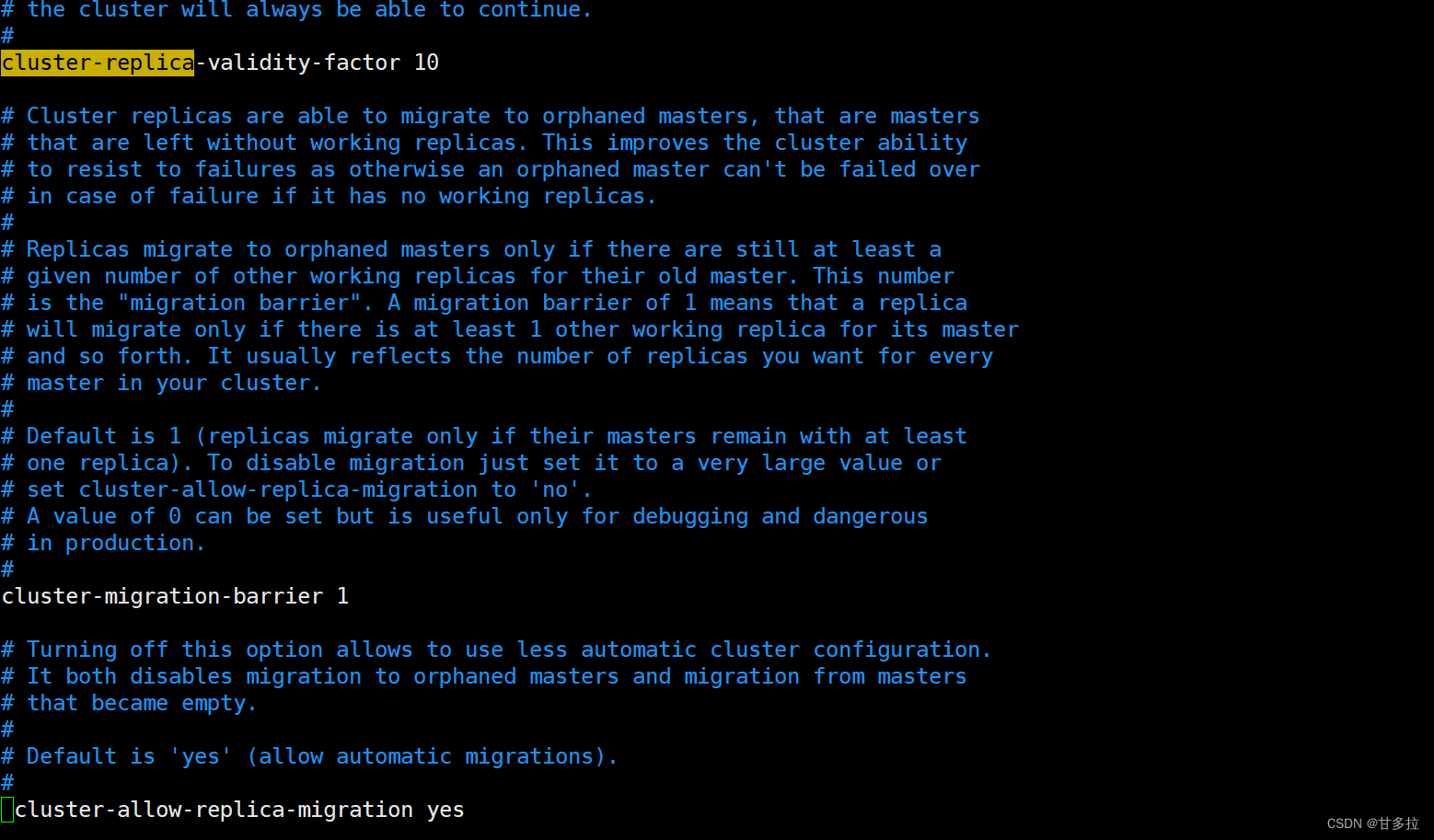
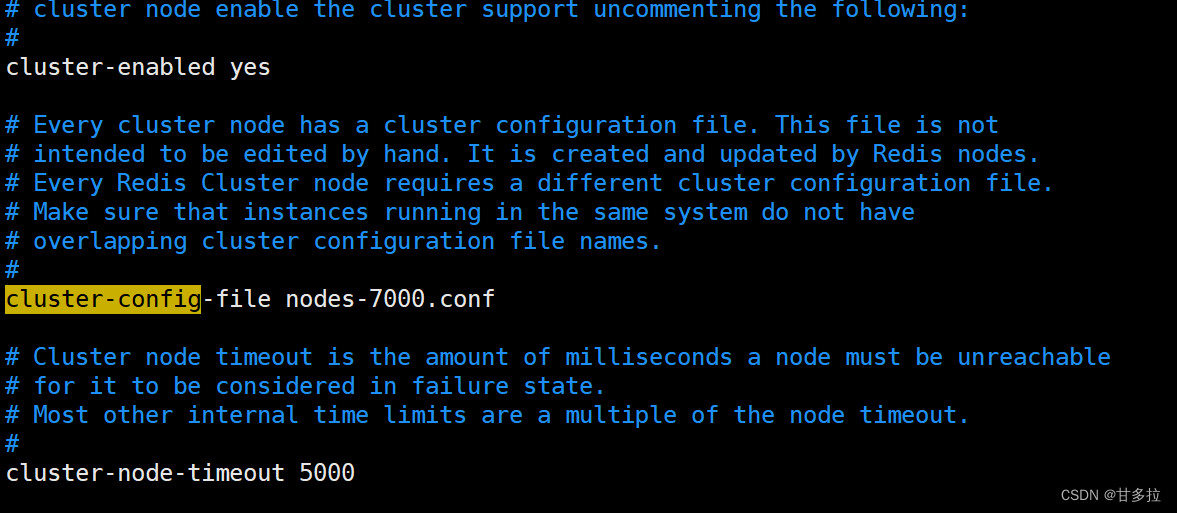


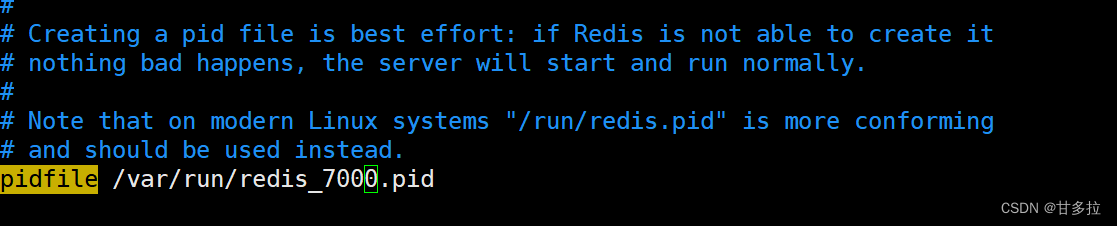


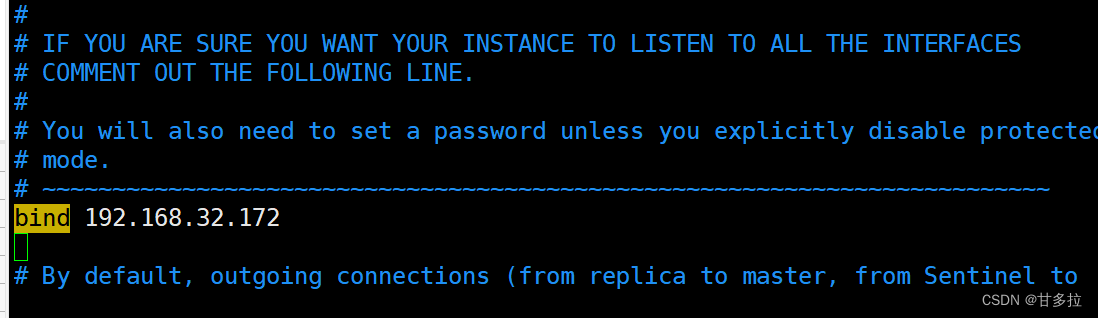
#注:
所有节点配置文件全部修改切记需要修改的ip、端口、pid文件...避免冲突。确保所有机器都修改。
5.启动三台机器上面的每个节点(三台机器相同操作)
[root@redis-cluster1 ~]# cd /data/redis/src/
[root@redis-cluster1 src]# ./redis-server ../cluster/7000/redis.conf
[root@redis-cluster1 src]# ./redis-server ../cluster/7001/redis.conf
[root@redis-cluster2 7003]# cd /data/redis/src/
[root@redis-cluster2 src]# ./redis-server ../cluster/7002/redis.conf
[root@redis-cluster2 src]# ./redis-server ../cluster/7003/redis.conf
[root@redis-cluster3 7005]# cd /data/redis/src/
[root@redis-cluster3 src]# ./redis-server ../cluster/7004/redis.conf
[root@redis-cluster3 src]# ./redis-server ../cluster/7005/redis.conf
查看端口
6.创建集群:在其中一个节点操作就可以
redis节点搭建起来后,需要完成redis cluster集群搭建,搭建集群过程中,需要保证6个redis实例都是运行状态。
Redis是根据IP和Port的顺序,确定master和slave的,所以要排好序,再执行。
参数:
--cluster-replicas 1:表示为集群中的每个主节点创建一个从节点.书写流程:主节点ip+port 对应一个从节点ip+port(正常是前面三个节点为主节点,后面的为从节点)
[root@redis-cluster1 src]# cd /data/redis/src/
[root@redis-cluster1 src]# ./redis-cli --cluster create --cluster-replicas 1 192.168.116.172:7000 192.168.116.172:7001 192.168.116.173:7002 192.168.116.173:7003 192.168.116.174:7004 192.168.116.174:7005
以下是运行效果图: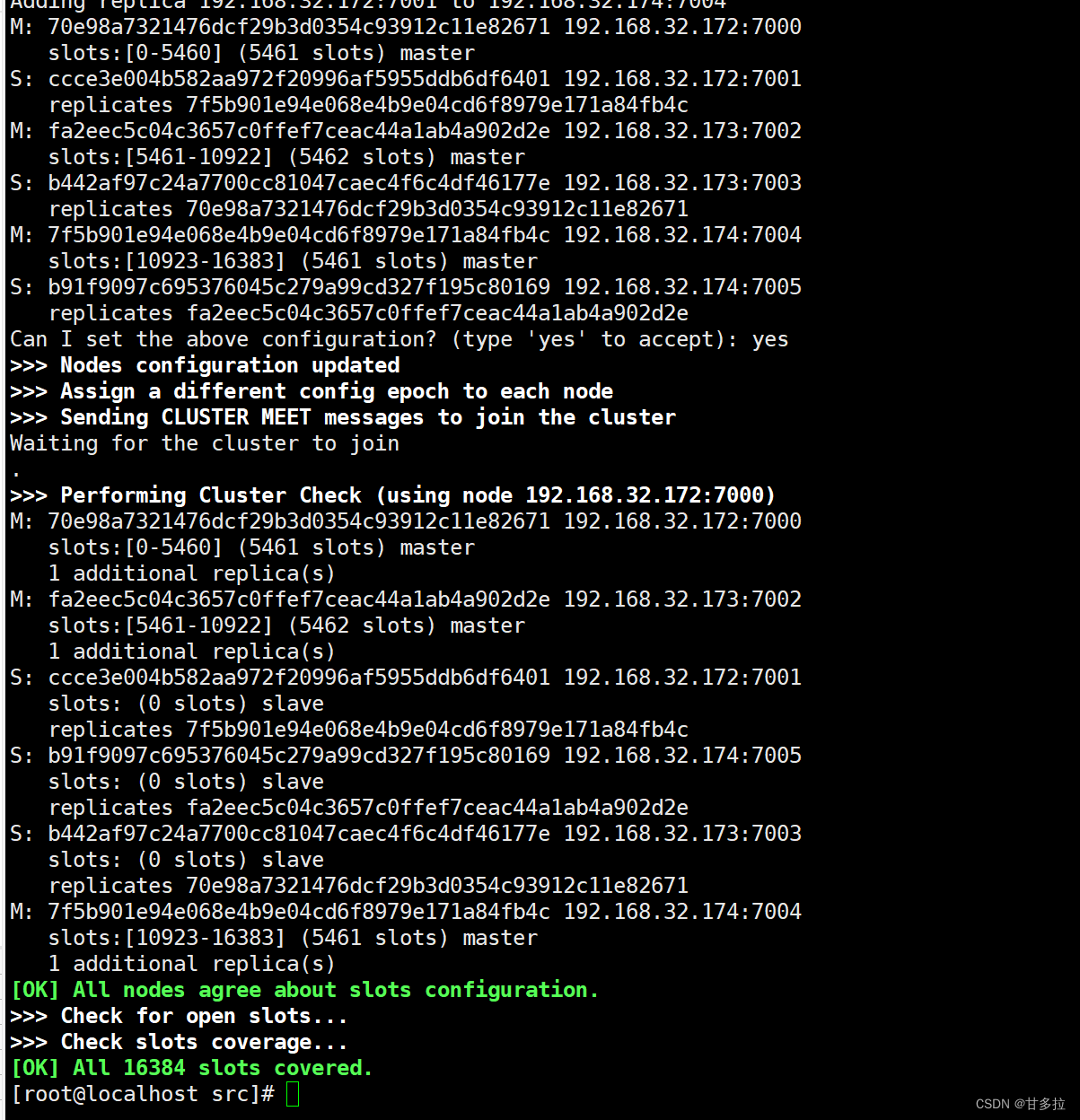
7.查看集群状态可连接集群中的任一节点,此处连接了集群中的节点192.168.116.172:7000
#登录集群客户端,-c标识以集群方式登录
[root@redis-cluster1 src]# ./redis-cli -h 192.168.116.172 -c -p 7000
192.168.116.172:7000> ping
PONG
192.168.116.173:7002> cluster info #查看集群信息
192.168.116.172:7000> cluster nodes #查看集群实例
运行效果图: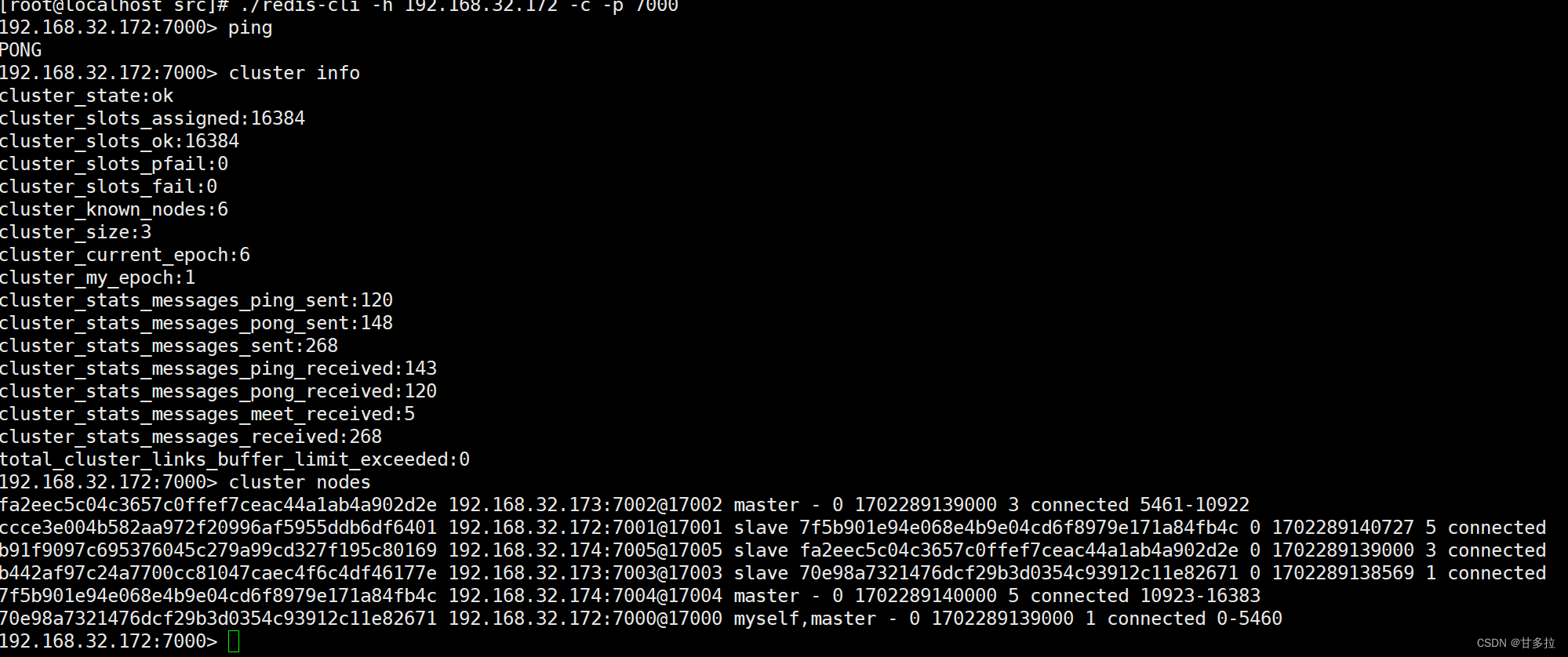
参数解释:
runid: 该行描述的节点的id。
ip:prot: 该行描述的节点的ip和port
flags: 分隔的标记位,可能的值有:
1.master: 该行描述的节点是master
2.slave: 该行描述的节点是slave
3.fail?:该行描述的节点可能不可用
4.fail:该行描述的节点不可用(故障)
master_runid: 该行描述的节点的master的id,如果本身是master则显示-
ping-sent: 最近一次发送ping的Unix时间戳,0表示未发送过
pong-recv:最近一次收到pong的Unix时间戳,0表示未收到过
config-epoch: 主从切换的次数
link-state: 连接状态,connnected 和 disconnected
hash slot: 该行描述的master中存储的key的hash的范围
















 2534
2534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











