






1 需求分析
此数据集包含美国Inc5000强企业的各项数据。它包含有用的信息,如企业类型、行业、投入产出、地区等其他信息,以作为数据分析的各项指标。本项目计划制作一个分析网站对投资大数据进行分析多层次多角度的分析。其意义在于,它可以帮助投资者更好地了解市场和行业趋势,从而做出更明智的投资决策。通过对大量数据的分析,投资者可以发现一些潜在的投资机会,以及市场中的风险和机会。此外,投资大数据还可以帮助投资者更好地管理风险,可见对于此进行大数据分析相当有意义。
随着互联网技术的广泛应用和数据采集技术的不断提高,大数据已经成为了金融投资领域的一种重要手段。投资大数据分析是指通过对市场、公司等各类数据的深度挖掘与分析,找出其中的规律和关联性,为投资决策提供科学、有效的支持。
一、数据规模不断增长
随着互联网的发展,各种类型的数据规模不断增加,这就为投资者提供了更多的信息来源。例如,金融市场数据、企业财务数据、电商数据、社交网络数据等等,都可以通过各种途径获取,包括公开数据、私人数据等等。
二、算法和技术的不断进步
随着机器学习、自然语言处理、深度学习、神经网络等技术的发展,大数据分析的算法也得到了飞速发展。传统的数据分析方法已经无法处理如此庞大的数据量和复杂的数据结构,而现在的算法可以更好地发掘数据之间的联系和潜在规律。
三、投资者对风险的关注
投资者在做决策时,往往需要考虑风险因素。大数据分析可以为投资者提供更为全面、客观的数据支持,有助于投资者更好地评估风险,并制定更为科学的投资策略。
四、投资者对效率的追求
现在的投资竞争越来越激烈,机构投资者和个人投资者都需要追求效率,以获取更多的利润。数据分析可以帮助投资者更快速、准确地识别潜在的投资机会,以及更好地预测市场变化趋势。
目前,投资大数据分析已经成为了金融领域中不可或缺的一部分,它可以帮助投资者更好地了解市场、企业、投资组合等各方面的情况,以及更加精准地定位投资机会和风险。
1.2 案例分析
这些数据是2014年Inc 5000公司榜单,该榜单是美国最快增长的私营公司的排名列表。根据这份清单,本项目可以看到全美最成功、最快增长的企业在哪里,以及它们是何种类型的公司。
从这份清单中可以看出,来自加利福尼亚州的Fuhu排名第一,这家公司主要从事消费品和服务业,增长率高达158956.91%,收入达1.96亿美元。接下来是Quest Nutrition和Reliant Asset Management,分别是食品和饮料和商业产品与服务领域的公司。继续往后排名,本项目可以看到Superfish、Acacia Communications等知名公司。
在榜单前20名中,健康、能源和金融服务是最常见的行业类型。此外,在整个榜单中的领域种类依次是:食品和饮料、商业产品和服务、IT服务、建筑和工程、广告和营销、零售和电子商务等。
榜单还提供了公司所在城市、收入、增长率、员工数量等信息,这些数据可以帮助研究这些公司如何运营管理。总体而言,这份清单提供了有关美国最快增长公司的宝贵信息,有助于本项目借鉴和学习成功企业的管理经验。
通过对数据的研究,本项目针对数据的特点与角度提出了以下几个分析角度:
1.员工与行业
2.地理与行业
3.投入产出与行业 //仪表盘
4.投入产出比与员工数量
5.投入产出比与地理位置
6.行业与在榜年数
7.行业与员工数量
8.行业占比
9.地理占比
本项目将在下面的概要设计中讨论对于上述分析角度本项目的思考与设计。
2 概要设计
2.1 总体设计
1.数据采集 通过已给的数据传入到Linux中
2.数据预处理 利用Spark对数据中的一些信息字段变为方便自己使用的信息
3.数据迁移 将表中的数据从 DataX 迁移到MySQL中
4.数据展示 将表中的数据利用JavaWeb后端展示到页面上
5.数据可视化 利用Echarts可视化数据

图2-1.总体设计图
2.2数据库表结构设计
根据本项目提出的问题,本项目列出了以下设计图

图2-2.hive表设计图
2.3JavaWeb后端设计
首先本项目确定本项目JSP页面将要分析的所有问题自己对应的表现方式如下:
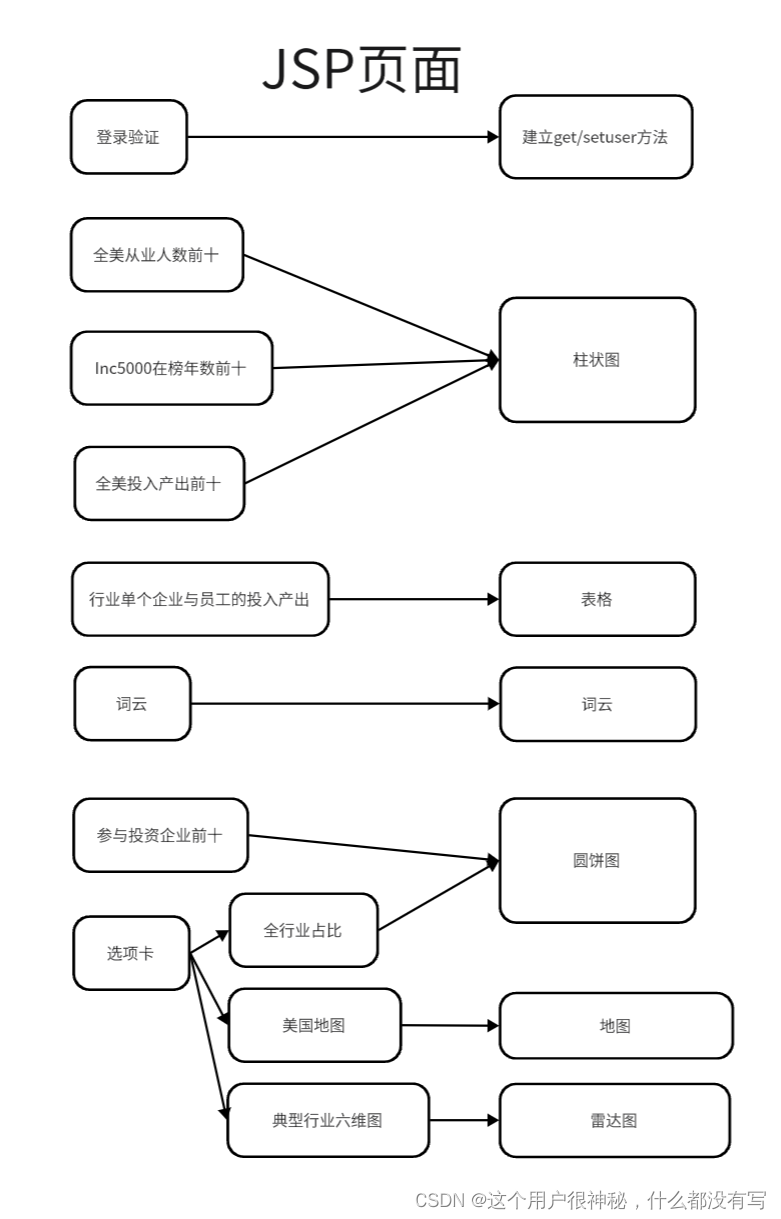
在此之后本项目需要根据设计好的表现方式来设计对应的实体类以及方法,如下:

连接MySQL数据库,通过三层架构对以上方法进行实现。
3 开发工具和编程语言
开发工具:VMware,MobaXterm_Personal_21.4,Filezilla,Idea,Tomcat
编程语言:HiveSQL,Spark SQL,Java,HTML,CSS,Javascript
4 详细设计
利用Filezilla工具将Inc5000.csv文件上传到Linux虚拟机中,路径为/home/Hadoop/data并备份保存一份以防万一。使用Flume将已经导入虚拟机的数据通过数据收集导入HDFS以备使用Spark进行数据处理。(简要介绍)
4.1 Spark数据处理
利用Spark对导入的数据进行处理
//行业与总员工数量
df = spark.sql("select industry ,sum(workers) as sum_workers from dw_inc5000 group by industry order by sum_workers desc")
df.write.format("Hive")
.mode("overwrite")
.option("delimiter", "\t")
.option("serialization.format", "\t")
.saveAsTable(" industry_and_sumworkers")
//行业与平均员工数量
df = spark.sql("select industry ,avg(workers) as avg_workers from dw_inc5000 group by industry order by avg_workers desc")
df.write.format("Hive")
.mode("overwrite")
.option("delimiter", "\t")
.option("serialization.format", "\t")
.saveAsTable("industry_and_avgworkers")
//地理位置与行业(一个州里面有多少个企业)
df = spark.sql(" select state_l as state,count(industry) as count from dw_inc5000 " +"group by state order by count DESC")
df.write.format("Hive")
.mode("overwrite")
.option("delimiter", "\t")
.option("serialization.format", "\t")
.saveAsTable(" industry_and_state")
//投入产出比与行业
df = spark.sql(" select industry, AVG(revenue/(growth*10000)) as avg_inoutput " +"from dw_inc5000 group by industry order by avg_inoutput DESC")
df.write.format("Hive")
.mode("overwrite")
.option("delimiter", "\t")
.option("serialization.format", "\t")
.saveAsTable("industry_and_inoutput")
//行业、平均员工数量、投入产出比
df = spark.sql("select industry_and_avgworkers.industry ,industry_and_avgworkers.avg_workers," +
" industry_and_InOutPut.avg_inoutput from industry_and_avgworkers,industry_and_InOutPut " +
"where industry_and_inoutput.industry=industry_and_avgworkers.industry order by avg_inoutput DESC")
df.write.format("Hive")
.mode("overwrite")
.option("delimiter", "\t")
.option("serialization.format", "\t")
.saveAsTable(" industry_and_inoutput_and_workers")
4.2 使用DataX进行数据迁移
使用如下配置文件进行数据迁移(简要介绍)
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://master:9000",
"path": "/user/hive/warehouse/inc.db/ads/*",
"column": [{
"index": "0",
"type": "string",
},
{
"index": "1",
"type": "double",
}],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ",",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"password": "123456",
"username": "root",
"connection": [
{
"jdbcUrl":"jdbc:mysql://master:3306/inc5000?useUnicode=true&characterEncoding=utf8",
"table": [
"industry_and_avgworkers"
]
}
],
"column": [
"*"
],
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
},
"errorLimit": {
"record": 0
}
}
}
}
4.3 建立Javaweb后端
4.3.1 建立三层架构

建立如图所示三层架构以备使用
4.3.1 连接数据库

里面已经存有Datax迁移来的数据。
4.3.2 建立如下方法
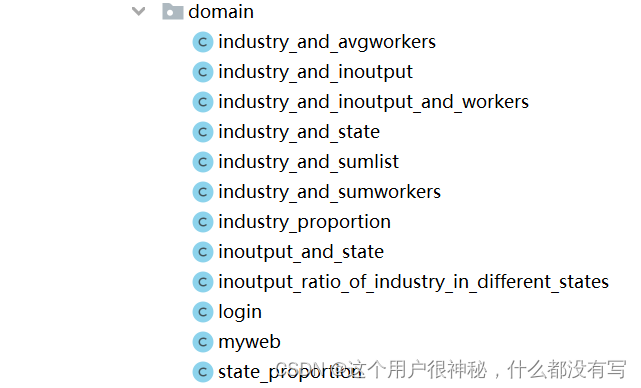
在方法中申明变量准备读取数据库中的数据。
package com.example.sparkweb.domain;
public class inoutput_ratio_of_industry_in_different_states {
private String industry;
private String state_1;
private Double total_revenue;
private Double total_growth;
private Double input_output_ratio;
public String getIndustry() {
return industry;
}
public void setIndustry(String industry) {
this.industry = industry;
}
public String getState_1() {
return state_1;
}
public void setState_1(String state_1) {
this.state_1 = state_1;
}
public Double getTotal_revenue() {
return total_revenue;
}
public void setTotal_revenue(Double total_revenue) {
this.total_revenue = total_revenue;
}
public Double getTotal_growth() {
return total_growth;
}
public void setTotal_growth(Double total_growth) {
this.total_growth = total_growth;
}
public Double getInput_output_ratio() {
return input_output_ratio;
}
public void setInput_output_ratio(Double input_output_ratio) {
this.input_output_ratio = input_output_ratio;
}
}
4.3.3 建立service方法与接口

在service方法中调用dao层的服务。以下为接口:
package com.example.sparkweb.service.impl;
import com.example.sparkweb.domain.*;
import java.util.List;
public interface iservice {
login getUserByUsernameAndPassword(String username, String password);
List<industry_and_sumlist> queryAll3();
List<industry_and_avgworkers> queryAll();
List<industry_and_inoutput> queryAll1();
List<industry_and_state> queryAll2();
List<industry_and_inoutput_and_workers> queryAll4();
List<inoutput_ratio_of_industry_in_different_states> queryAll5();
List<industry_and_sumworkers> queryAll6();
List<industry_proportion> queryAll7();
List<inoutput_and_state> queryAll8();
List<state_proportion> queryAll9();
}
以下为service服务:
import com.example.sparkweb.dao.idao;
import com.example.sparkweb.dao.impl.cdao;
import com.example.sparkweb.domain.*;
public class service implements iservice {
private idao dao = new cdao();
@Override
public login getUserByUsernameAndPassword(String username, String password) {
return dao.getUserByUsernameAndPassward(username,password);
}
@Override
public List<industry_and_sumlist> queryAll3(){
return dao.queryAll3();
}
@Override
public List<industry_and_avgworkers> queryAll(){
return dao.queryAll();
}
@Override
public List<industry_and_inoutput> queryAll1(){
return dao.queryAll1();
}
@Override
public List<industry_and_state> queryAll2(){
return dao.queryAll2();
}
@Override
public List<industry_and_inoutput_and_workers> queryAll4(){
return dao.queryAll4();
}
@Override
public List<inoutput_ratio_of_industry_in_different_states> queryAll5(){
return dao.queryAll5();
}
@Override
public List<industry_and_sumworkers> queryAll6(){
return dao.queryAll6();
}
@Override
public List<industry_proportion> queryAll7(){
return dao.queryAll7();
}
@Override
public List<inoutput_and_state> queryAll8(){
return dao.queryAll8();
}
@Override
public List<state_proportion> queryAll9(){
return dao.queryAll9();
}
}
4.3.4 建立dao方法与接口

以下为接口:
package com.example.sparkweb.dao;
import com.example.sparkweb.domain.*;
import java.util.List;
public interface idao {
login getUserByUsernameAndPassward(String username, String password);
List<industry_and_sumlist> queryAll3();
List<industry_and_avgworkers> queryAll();
List<industry_and_inoutput> queryAll1();
List<industry_and_state> queryAll2();
List<industry_and_inoutput_and_workers> queryAll4();
List<inoutput_ratio_of_industry_in_different_states> queryAll5();
List<industry_and_sumworkers> queryAll6();
List<industry_proportion> queryAll7();
List<inoutput_and_state> queryAll8();
List<state_proportion> queryAll9();
}
以下为方法:
package com.example.sparkweb.dao.impl;
import com.example.sparkweb.dao.idao;
import com.example.sparkweb.domain.*;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class cdao implements idao {
private QueryRunner runner =new QueryRunner(com.example.sparkweb.until.JdbcUtil.getDataSource());
public login getUserByUsernameAndPassward(String username, String password) {
String sql="SELECT * FROM stu01 WHERE name=? AND pwd=?";
try {
login user =runner.query(sql,new BeanHandler<>(login.class),username,password);
return user;
} catch (SQLException throwables) {
throw new RuntimeException(throwables);
}
}
@Override
public List<industry_and_sumlist> queryAll3() {
List<industry_and_sumlist> list=new ArrayList<>();
String sql ="SELECT * FROM industry_and_sumlist";
try {
list = runner.query(sql,new BeanListHandler<>(industry_and_sumlist.class));
} catch (SQLException e) {
throw new RuntimeException(e);
}
return list; // 下面实现它
}
4.3.5 建立servlet
调用service服务接口:
package com.example.sparkweb.web;
import com.example.sparkweb.domain.*;
import com.example.sparkweb.service.impl.iservice;
import com.example.sparkweb.service.impl.service;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.annotation.*;
import java.io.IOException;
import java.util.List;
@WebServlet(name = "sparkServlet", value = "/sparkServlet")
public class sparkServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
iservice service= new service();
// 调用服务,查询所有图书
List<industry_and_sumlist> list3 = service.queryAll3();
List<industry_and_avgworkers> list = service.queryAll();
List<industry_and_inoutput> list1 = service.queryAll1();
List<industry_and_state> list2 = service.queryAll2();
List<industry_and_inoutput_and_workers> list4 = service.queryAll4();
List<inoutput_ratio_of_industry_in_different_states> list5 = service.queryAll5();
List<industry_and_sumworkers> list6 = service.queryAll6();
List<industry_proportion> list7 = service.queryAll7();
List<inoutput_and_state> list8 = service.queryAll8();
List<state_proportion> list9 = service.queryAll9();
转发到页面:
request.setAttribute("list3", list3);
request.setAttribute("list", list);
request.setAttribute("list1", list1);
request.setAttribute("list2", list2);
request.setAttribute("list4", list4);
request.setAttribute("list5", list5);
request.setAttribute("list6", list6);
request.setAttribute("list7", list7);
request.setAttribute("list8", list8);
request.setAttribute("list9", list9);
获取登陆验证密码并输出到控制台,并且完成登陆验证:
/*乱码问题的解决*/
request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf8");
// 获取用户提交的用户名和密码
String username = request.getParameter("username");
String password = request.getParameter("password");
System.out.println(username + "," + password);
// 服务器检验用户的输入
// 访问数据库==》查询username和password对应的用户
com.example.sparkweb.service.impl.iservice userService = new service();
// 接口引用 = new 实现类的对象
login user = userService.getUserByUsernameAndPassword(username, password);
if (user == null) {
System.out.println("error"+"啦!密码都记不住吗?杂鱼~");
String error = "账号或密码错误";
request.setAttribute("error",error);
request.getRequestDispatcher("login.jsp").forward(request, response);
} else {
//登陆成功
request.setAttribute("name",username);
System.out.println(username+"登陆成功");
//重定向到首页
request.getRequestDispatcher("demo.jsp").forward(request, response);
4.3.6 配置JDBCuntil
package com.example.sparkweb.until;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.util.Properties;
public class JdbcUtil {
private static DataSource dataSource;
static {
// 读取资源目录下的配置文件,以输入流的方式返回
InputStream is = JdbcUtil.class.getClassLoader().getResourceAsStream("db.properties");
Properties p = new Properties();
try {
p.load(is);
dataSource = DruidDataSourceFactory.createDataSource(p);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static DataSource getDataSource(){
return dataSource;
}
}
4.4 制作数据可视化分析页面
4.4.1导入servlet
将负责前端同学完成的前端导入到webapp之下:
创建demo.jsp和login.jsp作为展示页面和登陆页面,复制html代码加入jsp文件。
添加如下代码引入servlet中的方法:
<%@ page import="java.util.List" %>
<%@ page import="com.example.sparkweb.domain.industry_and_sumlist" %>
<%@pageimport="com.example.sparkweb.domain.industry_and_avgworkers"%>
<%@ page import="com.example.sparkweb.domain.*" %>
<%@taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<%
List<industry_and_avgworkers> list = (List<industry_and_avgworkers>)request.getAttribute("list");
List<industry_and_inoutput> list1 = (List<industry_and_inoutput>)request.getAttribute("list1");
List<industry_and_state> list2 = (List<industry_and_state>)request.getAttribute("list2");
List<industry_and_sumlist> list3 = (List<industry_and_sumlist>)request.getAttribute("list3");
List<industry_and_inoutput_and_workers> list4 = (List<industry_and_inoutput_and_workers>)request.getAttribute("list4");
List<inoutput_ratio_of_industry_in_different_states> list5 = (List<inoutput_ratio_of_industry_in_different_states>)request.getAttribute("list5");
List<industry_and_sumworkers> list6 = (List<industry_and_sumworkers>)request.getAttribute("list6");
List<industry_proportion> list7 = (List<industry_proportion>)request.getAttribute("list7");
List<inoutput_and_state> list8 = (List<inoutput_and_state>)request.getAttribute("list8");
List<state_proportion> list9 = (List<state_proportion>)request.getAttribute("list9");
%>
4.4.2连接图表数据与数据库
开始针对表格与图表制作可视化分析界面,例如:
var titles=new Array();
var adatas=new Array();
var bdatas=new Array();
var bdatas1=new Array()
<%
for(int i=0;i<list6.size();i++){
%>
titles[<%=i%>]='<%=list6.get(i).getIndustry()%>'
adatas[<%=i%>]=<%=list6.get(i).getSum_workers()%>
<%
}
%>
<%
for(int i=0;i<10;i++){
%>
bdatas[<%=i%>]=<%=list.get(i).getAvg_workers()%>
//bdatas1[<%=i%>]=bdatas[<%=i%>]*100
<%
}
%>
来完成引入变量将echarts图表与后台数据库连接到一起。在echarts中使用这以上声明的变量即可让表格显示后台数据。本项目考虑了ajax可能更适合实时的将数据显示到echarts上。但是考虑到投资大数据的性质,它并非一个实时性相对较高的数据类型,因此本项目放弃了使用ajax而是用更为简单的代码实现来替换数据。
关于EL表达式将在下文提及,本项目面临jquery与EL表达式$符号的混用问题,付出了很多时间之后放弃了EL表达式的使用。
效果如图所示:

从本表中可以看出各大热门行业的从业人数与平均人数的比例,从而展示各大热门行业参与的企业数与行业本身的性质。如法炮制其他echarts图表以导入数据。
4.4.3CSS文件中加入滚动字幕
.ul_listIn{
-webkit-animation: 10s gundong linear infinite normal;
animation: 10s gundong linear infinite normal;
position: relative;}
@keyframes gundong {
0% {
-webkit-transform: translate3d(0, 0, 0);
transform: translate3d(0, 0, 0);
}
100% {
-webkit-transform: translate3d(0, -20vh, 0);
transform: translate3d(0, -20vh, 0);
}
}
效果如图所示:

本表格展示了各个平均行业的产出率,展示向相对应行业投资的获利可能。
4.4.3设置刷新自动修改颜色
color: function () {
return (
'rgb(' +
[Math.round(Math.random() * 256), Math.round(Math.random() * 256), Math.round(Math.random() * 256)].join(
','
) +
')'
);
},
因为本项目目标表格条目较多,可能会出现“颜色不够用”的情况。因此引入一个自动刷新颜色的功能非常重要。
效果如图所示:
刷新前:

刷新后:

4.5 建立前后端通信完成登陆验证、页面跳转、数据展示
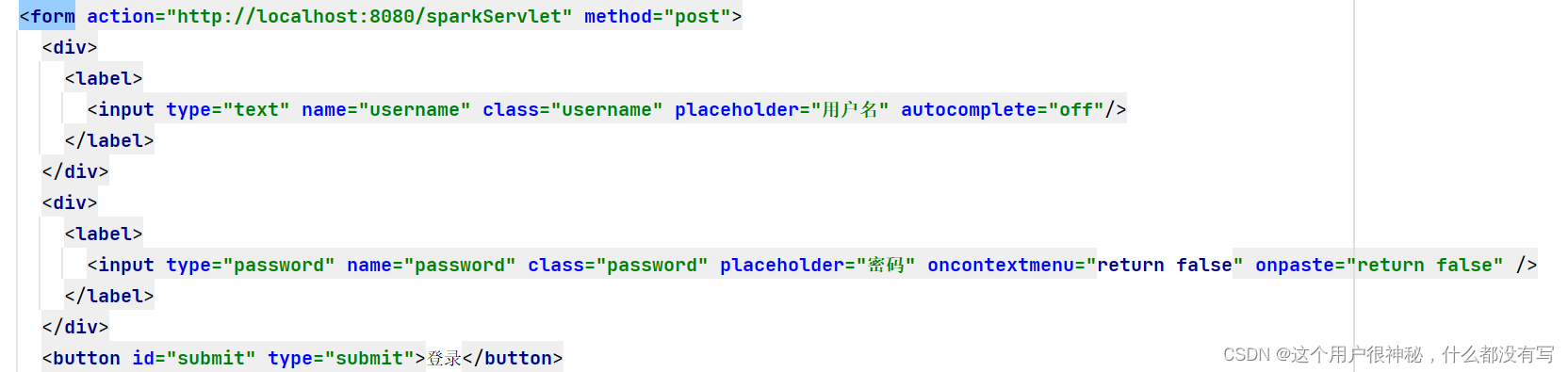
通过post进行按键页面跳转

访问数据库查询对应用户,完成登陆验证。

打开F12检查数据是否正确取出。
5 运行结果
5.1 登录页面展示
以下为登陆验证:

数据库内容:

输入正确密码登录成功,错误密码重新登陆。
5.2 整体页面效果展示
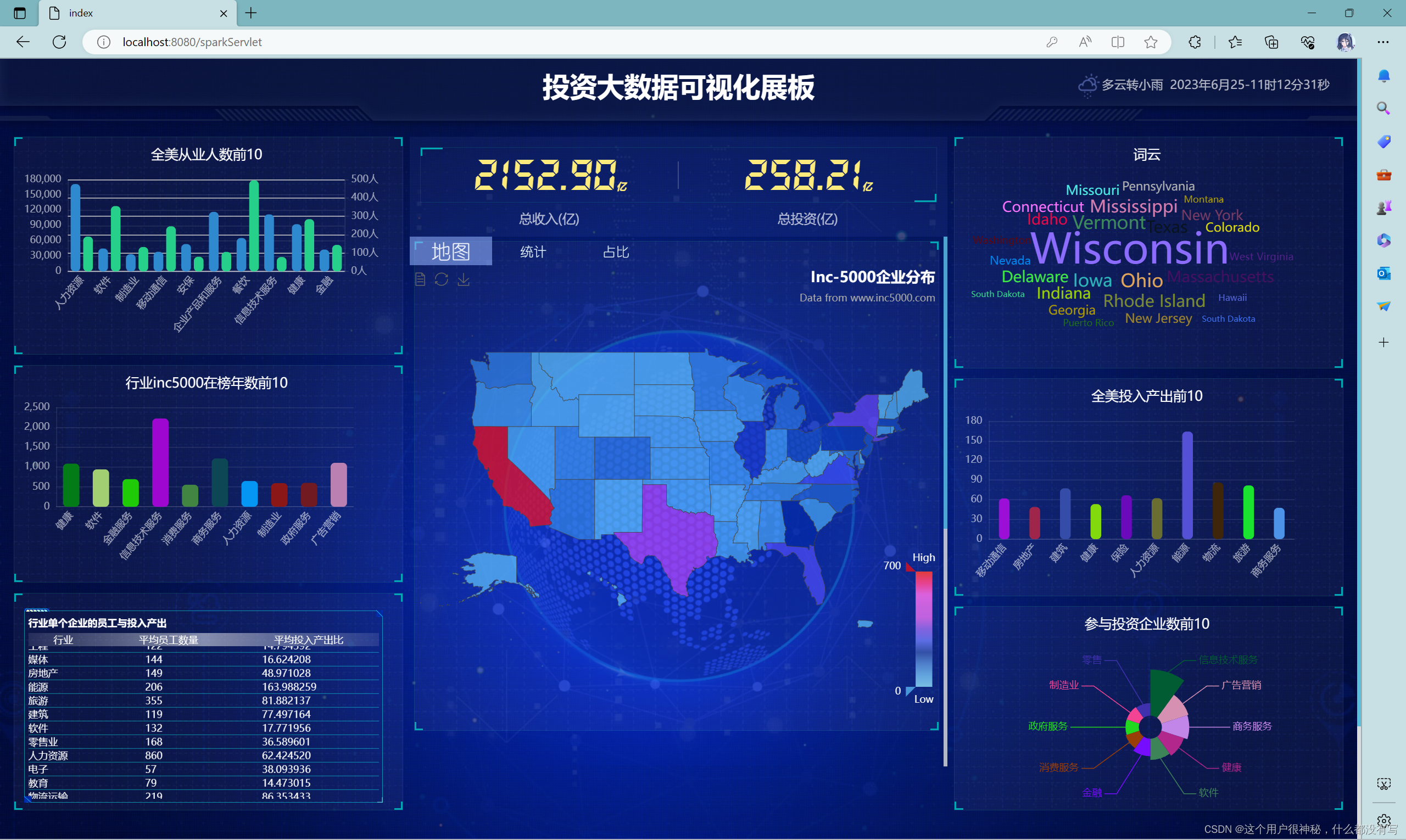
页面切换1

页面切换2

页面切换3
6 调试分析
6.1 问题1:EL表达式与jQuery混用
表现为取出数据但是无法填入数组进行echarts展示,在F12报错为不认识$符号,这是因为在jstl与jQuery中都有该符号,可以在使用EL表达式的地方停用jquery来防止这个冲突,但是过程很繁琐,因此本项目认为应尽量使用js代码来代替jQuery。放弃使用这种较为繁琐的表达方式。
6.1 问题2:EL表达式与jQuery混用
表现为取出数据但是无法填入数组进行echarts展示,在F12报错为不认识$符号,这是因为在jstl与jQuery中都有该符号,可以在使用EL表达式的地方停用jquery来防止这个冲突,但是过程很繁琐,因此本项目认为应尽量使用js代码来代替jQuery。放弃使用这种较为繁琐的表达方式。
7 总结
经过此次的实践课程学习,本项目对大数据项目中所用到的工具有了基本的了解并能够简单的应用(例如spark,datax,echarts,tomcat等),同时对于在大数据的应用实际场景中遇到实际问题的处理有了更为直观的认识,能够独立的处理一个较为简单的数据分析处理任务(在提供相应数据源的情况下)。本项目认为此项目的优点在于:步骤完善简洁,内容明确。本项目认为此项目的缺点在于:
1.没用使用ajax建立一个实时展现数据变化的系统。
2.数据可视化阶段中,未能完全利用到所给元数据中的所有数据。
全部项目加源码详见:
https://afdian.net/a/dsjsparkweb
抽到这个项目的校友?还请不要白嫖TAT














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









